Exploration de données
L’exploration de données[notes 1], connue aussi sous l'expression de fouille de données, forage de données, prospection de données, data mining[1], ou encore extraction de connaissances à partir de données, a pour objet l’extraction d'un savoir ou d'une connaissance à partir de grandes quantités de données, par des méthodes automatiques ou semi-automatiques.
Elle se propose d'utiliser un ensemble d'algorithmes issus de disciplines scientifiques diverses telles que les statistiques, l'intelligence artificielle ou l'informatique, pour construire des modèles à partir des données, c'est-à-dire trouver des structures intéressantes ou des motifs selon des critères fixés au préalable, et d'en extraire un maximum de connaissances.
L'utilisation industrielle ou opérationnelle de ce savoir dans le monde professionnel permet de résoudre des problèmes très divers, allant de la gestion de la relation client à la maintenance préventive, en passant par la détection de fraudes ou encore l'optimisation de sites web. C'est aussi le mode de travail du journalisme de données[2].
L'exploration de données[3] fait suite, dans l'escalade de l'exploitation des données de l'entreprise, à l'informatique décisionnelle. Celle-ci permet de constater un fait, tel que le chiffre d'affaires, et de l'expliquer comme le chiffre d'affaires décliné par produits, tandis que l'exploration de données permet de classer les faits et de les prévoir dans une certaine mesure [notes 2] ou encore de les éclairer en révélant par exemple les variables ou paramètres qui pourraient faire comprendre pourquoi le chiffre d'affaires de tel point de vente est supérieur à celui de tel autre.
Histoire
La génération de modèles à partir d'un grand nombre de données n'est pas un phénomène récent. Pour qu'il y ait création de modèle il faut qu'il y ait collecte de données. En Chine on prête à l'Empereur mythique Yao, la volonté de recenser les récoltes en 2238 av. J.-C.[4] ; en Égypte le pharaon Amasis organise le recensement de sa population au Ve siècle av. J.-C.[4] Ce n'est qu'au XVIIe siècle qu'on commence à vouloir analyser les données pour en rechercher des caractéristiques communes. En 1662, John Graunt publie son livre « Natural and Political Observations Made upon the Bills of Mortality » dans lequel il analyse la mortalité à Londres et essaie de prévoir les apparitions de la peste bubonique. En 1763, Thomas Bayes montre qu'on peut déterminer, non seulement des probabilités à partir des observations issues d’une expérience, mais aussi les paramètres relatifs à ces probabilités. Présenté dans le cas particulier d'une loi binomiale, ce résultat est étendu indépendamment par Laplace, conduisant à une formulation générale du théorème de Bayes. Legendre publie en 1805 un essai sur la méthode des moindres carrés qui permet de comparer un ensemble de données à un modèle mathématique. Les calculs manuels coûteux ne permettent cependant pas d'utiliser ces méthodes hors d'un petit nombre de cas simples et éclairants.
De 1919 à 1925, Ronald Fisher met au point l'analyse de la variance comme outil pour son projet d'inférence statistique médicale. Les années 1950 voient l'apparition de calculateurs encore onéreux et des techniques de calcul par lots sur ces machines. Simultanément, des méthodes et des techniques voient le jour telles que la segmentation, classification (entre autres par la méthode des nuées dynamiques), une première version des futurs réseaux de neurones qui se nomme le Perceptron, et quelques algorithmes auto-évolutifs qui se nommeront plus tard génétiques. Dans les années 1960 arrivent les arbres de décision et la méthode des centres mobiles; ces techniques permettent aux chercheurs d'exploiter et de découvrir des modèles de plus en plus précis. En France, Jean-Paul Benzécri développe l'analyse des correspondances en 1962. On reste cependant dans une optique de traitement par lots.
En 1969 paraît l'ouvrage de Myron Tribus Rational descriptions, decisions and designs[5] qui généralise les méthodes bayésiennes dans le cadre du calcul automatique (professeur à Dartmouth, il utilise assez logiquement le langage BASIC, qui y a été créé quelques années plus tôt, et son interactivité). La traduction en français devient disponible en 1973 sous le nom Décisions rationnelles dans l'incertain. Une idée importante de l'ouvrage est la mention du théorème de Cox-Jaynes démontrant que toute acquisition d'un modèle soit se fait selon les règles de Bayes (à un homomorphisme près), soit conduit à des incohérences. Une autre est que parmi toutes les distributions de probabilité satisfaisant aux observations (leur nombre est infini), il faut choisir celle qui contient le moins d'arbitraire (donc le moins d'information ajoutée, et en conséquence celle d'entropie maximale[notes 3]. La probabilité s'y voit considérée comme simple traduction numérique d'un état de connaissance, sans connotation fréquentiste sous-jacente. Enfin, cet ouvrage popularise la notation des probabilités en décibels, qui rend la règle de Bayes additive et permet de quantifier de façon unique l'apport d'une observation en la rendant désormais indépendante des diverses estimations a priori préalables (voir Inférence bayésienne).
L'arrivée progressive des micro-ordinateurs permet de généraliser facilement ces méthodes bayésiennes sans grever les coûts. Cela stimule la recherche et les analyses bayésiennes se généralisent, d'autant que Tribus a démontré leur convergence, au fur et à mesure des observations, vers les résultats des statistiques classique tout en permettant d'affiner les connaissances au fil de l'eau sans nécessiter les mêmes délais d'acquisition (voir aussi Plan d'expérience).
L'affranchissement du protocole statistique classique commence alors : il n'est plus nécessaire de se fixer une hypothèse et de la vérifier ou non a posteriori. Au contraire, les estimations bayésiennes vont construire elles-mêmes ces hypothèses au fur et à mesure que s'accumulent les observations.
L'expression « data mining » avait une connotation péjorative au début des années 1960, exprimant le mépris des statisticiens pour les démarches de recherche de corrélation sans hypothèses de départ[réf. nécessaire]. Elle tombe dans l'oubli, puis Rakesh Agrawal l'emploie à nouveau dans les années 1980 lorsqu'il entamait ses recherches sur des bases de données d'un volume de 1 Mo. Le concept d'exploration de données fait son apparition, d'après Pal et Jain, aux conférences de l'IJCAI en 1989[6]. Gregory Piatetsky-Shapiro chercha un nom pour ce nouveau concept dans la fin des années 1980, aux GTE Laboratories. « Data mining » étant sous la protection d'un copyright, il employa l'expression « Knowledge discovery in data bases » (KDD)[7].
Puis, dans les années 1990, viennent les techniques d'apprentissage automatique telles que les SVM[b 1] en 1998, qui complètent les outils de l'analyste.
Au début du XXIe siècle, une entreprise comme Amazon.com se sert de tous ces outils pour proposer à ses clients des produits susceptibles de les intéresser[8],[9].
Applications industrielles
Par objectifs

De nos jours, les techniques d'exploration de données peuvent être utilisées dans des domaines complètement différents avec des objectifs bien spécifiques. Les sociétés de vente par correspondance analysent, avec cette technique, le comportement des consommateurs pour dégager des similarités de comportement, accorder des cartes de fidélité, ou établir des listes de produits à proposer en vente additionnelle (vente croisée).
Un publipostage (mailing) servant à la prospection de nouveaux clients possède un taux de réponses de 10 % en moyenne. Les entreprises de marketing utilisent la fouille de données pour réduire le coût d'acquisition d'un nouveau client en classant les prospects selon des critères leur permettant d'augmenter les taux de réponses[10] aux questionnaires envoyés.
Ces mêmes entreprises, mais d'autres aussi comme les banques, les opérateurs de téléphonie mobile ou les assureurs, cherchent grâce à l'exploration de données à minimiser l’attrition (ou churn) de leurs clients puisque le coût de conservation d'un client est moins important que celui de l'acquisition d'un nouveau.
Les services de polices de tous les pays[11] cherchent à caractériser les crimes (répondre à la question : « Qu'est-ce qu'un crime « normal » ? ») et les comportements des criminels (répondre à la question : « qu'est-ce qu'un comportement criminel « normal » ? ») afin de prévenir le crime, limiter les risques et les dangers pour la population.
Le scoring des clients dans les banques est maintenant très connu, il permet de repérer les « bons » clients, sans facteur de risque (Évaluation des risques-clients) à qui les organismes financiers, banques, assurances, etc., peuvent proposer une tarification adaptée et des produits attractifs, tout en limitant le risque de non-remboursement ou de non-paiement ou encore de sinistre dans le cas des assurances.
Les centres d'appel utilisent cette technique[10] pour améliorer la qualité du service[12] et permettre une réponse adaptée de l'opérateur pour la satisfaction du client.
Dans la recherche du génome humain, les techniques d'exploration de données ont été utilisées pour découvrir les gènes et leur fonction[13].
D'autres exemples dans d'autres domaines pourraient être trouvés, mais ce qu'on peut remarquer dès à présent, c'est que toutes ces utilisations permettent de caractériser un phénomène complexe (comportement humain, expression d'un gène), pour mieux le comprendre, afin de réduire les coûts de recherche ou d'exploitation liés à ce phénomène, ou bien afin d'améliorer la qualité des processus liés à ce phénomène.
Par secteurs d'activités
L'industrie a pris conscience de l'importance du patrimoine constitué par ses données et cherche à l'exploiter en utilisant l'informatique décisionnelle et l'exploration des données. Les compagnies les plus avancées dans ce domaine se situent dans le secteur tertiaire. Selon le site kdnuggets.com[14] la répartition aux États-Unis, en pourcentage du total des réponses au sondage, de l'utilisation de l'exploration des données par secteurs d'activités s'effectue en 2010 comme ceci :
Recherche et groupes de réflexion
Comme le montre l'histogramme ci-dessus, l'industrie est très intéressée par le sujet, notamment en matière de standard et d'interopérabilité[notes 4] qui facilitent l'emploi d'outils informatiques provenant d'éditeurs différents. En outre, les entreprises, l'enseignement et la recherche ont grandement contribué à l'évolution et à l'amélioration (en termes de rigueur par exemple) des méthodes et des modèles ; un article publié en 2008 par l'International Journal of Information Technology and Decision Making résume une étude qui trace et analyse cette évolution[15]. Certains acteurs sont passés de la recherche à l'industrie.
Des universités telles que celles de Constance en Allemagne, de Dortmund en Caroline du Nord, aux États-Unis, de Waikato en Nouvelle-Zélande, et l'Université Lumière Lyon 2 en France, ont effectué des recherches pour trouver de nouveaux algorithmes et améliorer les anciens[source insuffisante]. Ils ont aussi développé des logiciels permettant à leurs étudiants, enseignants et chercheurs de progresser dans ce domaine, faisant ainsi bénéficier l'industrie de leur progrès.
D’autre part, de nombreux groupements interprofessionnels et d'associations se sont créés pour réfléchir et accompagner le développement de l'exploration de données. Le premier de ces groupements professionnels dans le domaine est le groupe d’intérêt de l'Association for Computing Machinery sur la gestion des connaissances et l'exploration de données, le SIGKDD[16]. Depuis 1989 il organise une conférence internationale annuelle et publie les nouveaux résultats, réflexions et développements de ses membres[17]. Ainsi, depuis 1999, cet organisme publie une revue semestrielle dont le titre est « SIGKDD Explorations »[18].
D'autres conférences sur l'exploration de données et l'informatique sont organisées, par exemple :
- DMIN - International Conference on Data Mining[19],[20],[21],[22],[23]
- DMKD - Research Issues on Data Mining and Knowledge Discovery
- ECML-PKDD - European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases
- ICDM[24] - IEEE International Conference on Data Mining[25],[26],[27],[28],[29],[30],[31],[32]
- MLDM - Machine Learning and Data Mining in Pattern Recognition
- SDM - SIAM International Conference on Data Mining
- EDM - International Conference on Educational Data Mining
- ECDM - European Conference on Data Mining
- PAKDD - The annual Pacific-Asia Conference on Knowledge Discovery and Data Mining
Ces recherches et résultats financièrement probants obligent les équipes spécialisées dans l'exploration de données à effectuer un travail méthodique dans des projets structurés.
Projets, méthodes et processus
De bonnes pratiques ont émergé au fil du temps pour améliorer la qualité des projets. Parmi celles-ci, les méthodologies aident les équipes à organiser les projets en processus. Au nombre des méthodes les plus utilisées se trouvent la méthodologie SEMMA du SAS Institute et la CRISP-DM qui est la méthode la plus employée dans les années 2010.
Méthode CRISP-DM
La méthode CRISP-DM[33] découpe le processus de fouille de données en six étapes permettant de structurer la technique et de l'ancrer dans un processus industriel. Plus qu'une théorie normalisée, c'est un processus d'extraction des connaissances métiers.
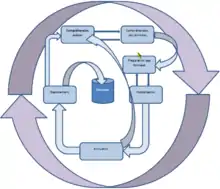
Il faut d'abord comprendre le métier[33] qui pose la question à l'analyste, formaliser le problème que l'organisation cherche à résoudre en ce qui concerne les données, comprendre les enjeux, connaître les critères de réussite du projet et mettre en place un plan initial pour réaliser cet objectif.
Ensuite, l'analyste a besoin de données appropriées. Dès que l'équipe de projet sait ce qu'il faut faire, elle doit se mettre en quête des données, des textes et tout le matériel qui lui permettra de répondre au problème. Il lui faut ensuite en évaluer la qualité, découvrir les premiers schémas apparents pour émettre des hypothèses sur les modèles cachés.
Les données que l'équipe de projet a collectées sont hétérogènes. Elles doivent être préparées[33] en fonction des algorithmes utilisés, en supprimant les valeurs aberrantes, ou valeurs extrêmes, en complétant les données non renseignées, par la moyenne ou par la méthode des K plus proches voisins, en supprimant les doublons, les variables invariantes et celles ayant trop de valeurs manquantes, ou bien par exemple en discrétisant les variables si l’algorithme à utiliser le nécessite, comme c'est par exemple le cas pour l'analyse des correspondances multiples ACM, l'analyse discriminante DISQUAL, ou bien la méthode de Condorcet.
Une fois les données prêtes, il faut les explorer[33]. La modélisation regroupe des classes de tâches pouvant être utilisées seules ou en complément avec les autres[34] dans un but descriptif ou prédictif.
La segmentation est la tâche consistant à découvrir des groupes et des structures au sein des données qui sont d'une certaine façon similaires, sans utiliser des structures connues a priori dans les données. La classification est la tâche de généralisation des structures connues pour les appliquer à des données nouvelles[notes 5].
La régression tente de trouver une fonction modélisant les données continues, c'est-à-dire non discrètes, avec le plus petit taux d'erreur, afin d'en prédire les valeurs futures. L'association recherche les relations entre des items. Par exemple un supermarché peut rassembler des données sur des habitudes d'achats de ses clients. En utilisant les règles d'association, le supermarché peut déterminer quels produits sont fréquemment achetés ensemble et ainsi utiliser cette connaissance à des fins de marketing. Dans la littérature, cette technique est souvent citée sous le nom d'« analyse du panier de la ménagère ».
Il s'agit d'évaluer ensuite[33] les résultats obtenus en fonction des critères de succès du métier et d'évaluer le processus lui-même pour faire apparaître les manques et les étapes négligées. À la suite de ceci, il doit être décidé soit de déployer, soit d'itérer le processus en améliorant ce qui a été mal ou pas effectué.
Puis vient la phase de livraison[33] et de bilan de fin de projet. Les plans de contrôle et de maintenance sont conçus et le rapport de fin de projet est rédigé. Afin de déployer un modèle prédictif, le langage PMML, basé sur le XML, est utilisé. Il permet de décrire toutes les caractéristiques du modèle et de le transmettre à d'autres applications compatibles PMML.
Autres process et méthodes
D'autres process existent:
Maladresses à éviter
Les écueils les plus communément rencontrés par les fouilleurs de données expérimentés ou non ont été décrits par Robert Nisbet, John Elder et Gary Miner dans leur ouvrage Handbook of Statistical Analysis & Data Mining Applications[b 2].
La première est le fait de poser la mauvaise question. Ce qui conduit à faire chercher au mauvais endroit. Il faut que la question initiale soit correctement posée pour que la réponse soit utile.
Ensuite, c'est se contenter d'une faible quantité de données pour un problème complexe[b 2]. Il faut avoir des données pour les explorer, et les cas intéressants pour le fouilleur sont rares à observer, il faut donc avoir à sa disposition énormément de données pour pouvoir faire des échantillons qui ont une valeur d'apprentissage et qui vont permettre de prédire une situation, c'est-à-dire répondre à une question posée, sur les données hors échantillon. De plus, si les données ne sont pas adaptées à la question posée, la fouille sera limitée : par exemple si les données ne contiennent pas de variables à prédire, la fouille sera cantonnée à la description et l'analyste ne pourra que découper les données en sous-ensembles cohérents (clusterisation) ou trouver les meilleures dimensions qui capturent la variabilité des données.
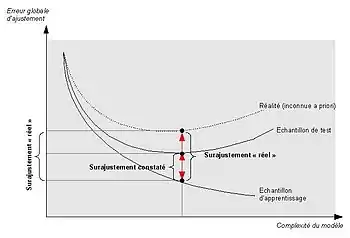
Il faut construire l'échantillon, qui permet l'apprentissage, avec précaution et ne pas échantillonner à la légère[b 2]. L'apprentissage permet de construire le modèle à partir d'un ou plusieurs échantillons. Paramétrer l'outil d'exploration de données jusqu'à ce que le modèle renvoie 100 % des cas recherchés revient à se concentrer sur les particularités et se détourner de la généralisation, nécessaire, qui permet d'appliquer le modèle sur les données hors-échantillon. Des techniques existent pour éviter le sur-ajustement ou le sur-apprentissage. Il s'agit des méthodes de ré-échantillonnage telles que le bootstrap, du jackknife ou de la validation croisée[36].
Parfois, une seule technique (arbre de décision, réseaux neuronaux...) n'est pas suffisante pour obtenir un modèle qui donne de bons résultats sur toutes les données[b 2]. Une des solutions, dans ce cas, serait constituée d'un ensemble d'outils, qu'on peut utiliser les uns après les autres et comparer les résultats sur les mêmes données ou bien unifier les forces de chaque méthode soit par l'apprentissage soit par combinaison des résultats[37].
Il faut placer les données et les résultats de la fouille en perspective dans leur contexte[b 2], et ne pas se focaliser sur les données, sans cela des erreurs d'interprétation peuvent survenir ainsi que des pertes de temps et d'argent.
Éliminer à priori les résultats qui paraissent absurdes[38], en comparaison avec ce qui est attendu, peut être source d'erreurs car ce sont peut-être ces résultats qui donnent la solution à la question posée.
Il est impossible d'utiliser et d’interpréter les résultats d'un modèle en dehors du cadre dans lequel il a été construit[b 2]. Interpréter des résultats en fonction d'autres cas similaires mais différents est aussi cause d'erreurs, mais ce n'est pas propre aux raisonnements liés à l'exploration de données. Enfin, extrapoler des résultats, obtenus sur des espaces de faibles dimensions, sur des espaces de dimensions élevées peut aussi conduire à des erreurs.
Deux citations de George Box, « Tous les modèles sont faux, mais certains sont utiles » et « Les statisticiens sont comme les artistes, ils tombent amoureux de leurs modèles », illustrent avec humour le fait que quelquefois certains analystes en fouille de données ont besoin de croire en leur modèle et de croire que le modèle qu'ils travaillent est le meilleur. Utiliser un ensemble de modèles et interpréter la distribution des résultats est nettement plus sûr[39].
Planifier
Dans un projet d'exploration de données, il est essentiel de savoir ce qui est important et ce qui ne l'est pas, ce qui prend du temps et ce qui n'en prend pas ; ce qui ne coïncide pas toujours.
| Tâches | Charge | Importance dans le projet |
|---|---|---|
| Inventaire, préparation et exploration des données | 38 % | 3 |
| Élaboration - Validation des modèles | 25 % | 2 |
| Restitution des résultats | 12 % | 4 |
| Analyse des premiers tests | 10 % | 3 |
| Définition des objectifs | 8 % | 1 |
| Documentation - présentations | 7 % | 5 |
Le cœur de l'exploration de données est constitué par la modélisation : toute la préparation est effectuée en fonction du modèle que l'analyste envisage de produire, les tâches effectuées ensuite valident le modèle choisi, le complètent et le déploient. La tâche la plus lourde de conséquences dans la modélisation consiste à déterminer le ou les algorithmes qui produiront le modèle attendu. La question importante est donc celle des critères qui permettent de choisir cet ou ces algorithmes.
Algorithmes
Résoudre un problème par un processus d'exploration de données impose généralement l'utilisation d'un grand nombre de méthodes et d'algorithmes différents plus ou moins faciles à comprendre et à employer[41]. Il existe deux grandes familles d'algorithmes : les méthodes descriptives et les méthodes prédictives.
Définition
Les méthodes descriptives[42] permettent d'organiser, de simplifier et d'aider à comprendre l'information sous-jacente d'un ensemble important de données.
Elles permettent de travailler sur un ensemble de données, organisées en instances de variables, dans lequel aucune des variables explicatives des individus n'a d'importance particulière par rapport aux autres. Elles sont utilisées par exemple pour dégager, d'un ensemble d'individus, des groupes homogènes en typologie, pour construire des normes de comportements et donc des déviations par rapport à ces normes telles que la détection de fraudes nouvelles ou inconnues à la carte bancaire ou à l'assurance maladie, pour réaliser de la compression d'informations ou de la compression d'image, etc.
Exemples
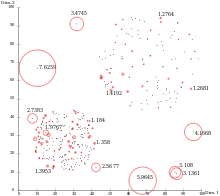
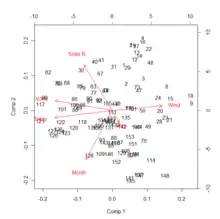
Parmi les techniques disponibles, celles qui sont issues de la statistique peuvent être exploitées. Sont regroupées sous le vocable analyses factorielles, des méthodes statistiques qui permettent de dégager des variables cachées dans un ensemble de mesures ; ces variables cachées sont appelées « facteurs ». Dans les analyses factorielles, on part du principe que si les données sont dépendantes entre elles, c'est parce qu'elles sont liées à des facteurs qui leur sont communs[43]. L’intérêt des facteurs réside dans le fait qu'un nombre réduit de facteurs explique presque aussi bien les données que l'ensemble des variables, ce qui est utile quand il y a un grand nombre de variables[b 4]. Les techniques factorielles se décomposent principalement en analyse en composantes principales, analyse en composantes indépendantes, analyse factorielle des correspondances, analyse des correspondances multiples et positionnement multidimensionnel[44].
Pour fixer les idées, l'analyse en composantes principales fait correspondre à variables quantitatives décrivant individus, facteurs, les composantes principales, de telle manière que la perte d'information soit minimum. En effet, les composantes sont organisées dans l'ordre croissant des pertes d'information, la première en perdant le moins. Les composantes sont non corrélées linéairement entre elles et les individus sont projetés sur les axes définis par les facteurs en respectant la distance qui existe entre eux. Les similitudes et les différences sont expliquées par les facteurs.



L'analyse factorielle des correspondances et l'ACM font correspondre à variables qualitatives décrivant les caractéristiques de individus, facteurs en utilisant le tableau de contingence, ou le tableau de Burt dans le cas de l'ACM, de telle manière que les facteurs soient constitués des variables numériques séparant le mieux les valeurs des variables qualitatives initiales[b 5], que deux individus soient proches s'ils possèdent à peu près les mêmes valeurs des variables qualitatives et que les valeurs de deux variables qualitatives soient proches si ce sont pratiquement les mêmes individus qui les possèdent[b 5].
On peut aussi utiliser des méthodes nées dans le giron de l'intelligence artificielle et plus particulièrement dans celui de l'apprentissage automatique. La classification[44] non supervisée est une famille de méthodes qui permettent de regrouper des individus en classes, dont la caractéristique est que les individus d'une même classe se ressemblent, tandis que ceux de deux classes différentes sont dissemblables. Les classes de la classification ne sont pas connues au préalable, elles sont découvertes par le processus. D'une manière générale, les méthodes de classification servent à rendre homogènes des données qui ne le sont pas à priori, et ainsi permettent de traiter chaque classe avec des algorithmes sensibles aux données aberrantes. Dans cette optique, les méthodes de classification forment une première étape du processus d'analyse.
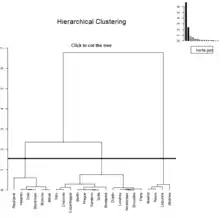
Ces techniques empruntées à l'intelligence artificielle utilisent le partitionnement de l'ensemble des informations mais aussi le recouvrement. Le partitionnement est l'objectif des algorithmes utilisant par exemple des méthodes telles que celles des k-means (les « nuées dynamiques » en français), des k-medoids[b 6] (k-médoïdes), k-modes et k-prototypes, qu'on peut utiliser pour rechercher les aberrations (outliers), les réseaux de Kohonen, qui peuvent aussi servir à la classification[45], l'algorithme EM ou l'AdaBoost. La classification hiérarchique est un cas particulier de partitionnement pour lequel les graphiques produits sont facilement compréhensibles. Les méthodes ascendantes partent des individus qu'on agrège en classes, tandis que les méthodes descendantes partent du tout et par divisions successives arrivent aux individus qui composent les classes. Ci-contre le graphique d'une classification ascendante a été tracé pour montrer comment les classes les plus proches sont reliées entre elles pour former des classes de niveau supérieur.
Le recouvrement à logique floue est une forme de recouvrement de l'ensemble des individus représentés par les lignes d'une matrice où certains d'entre eux possèdent une probabilité non nulle d'appartenir à deux classes différentes. L'algorithme le plus connu de ce type est le FCM (Fuzzy c-means)[46].
Il faut aussi mentionner l’ Iconographie des corrélations associée à l’utilisation des Interactions logiques, méthode géométrique qui se prête bien à l’analyse des réseaux complexes de relations multiples.
En bio-informatique, des techniques de classification double sont employées pour regrouper simultanément dans des classes différentes les individus et les variables qui les caractérisent.
Pour rendre compte de l'utilité de ces méthodes de recouvrement, il faut se rappeler que la classification est un problème dont la grande complexité a été définie par Eric Bell. Le nombre de partitions d'un ensemble de objets est égal à : . Il vaut donc mieux avoir des méthodes efficaces et rapides pour trouver une partition qui répond au problème posé plutôt que de parcourir l'ensemble des solutions possibles.

Enfin, quand l'analyse se porte non pas sur les individus, les items ou les objets, mais sur les relations qui existent entre eux, la recherche de règles d'associations est l'outil adapté. Cette technique est, à l'origine, utilisée pour faire l'analyse du panier d'achats ou l'analyse de séquences. Elle permet, dans ce cas, de savoir quels sont les produits achetés simultanément, dans un supermarché par exemple, par un très grand nombre de clients ; elle est également appliquée pour résoudre des problèmes d'analyse de parcours de navigation de sites web. La recherche de règles d'association peut être utilisée de manière supervisée ; les algorithmes APriori, GRI, Carma, méthode ARD ou encore PageRank se servent de cette technique[47].
Méthodes prédictives
Définition
La raison d'être des méthodes prédictives est d'expliquer ou de prévoir un ou plusieurs phénomènes observables et effectivement mesurés. Concrètement, elles vont s'intéresser à une ou plusieurs variables définies comme étant les cibles de l'analyse. Par exemple, l'évaluation de la probabilité pour qu'un individu achète un produit plutôt qu'un autre, la probabilité pour qu'il réponde à une opération de marketing direct, celles qu'il contracte une maladie particulière, en guérisse, les chances qu'un individu ayant visité une page d'un site web y revienne, sont typiquement des objectifs que peuvent atteindre les méthodes prédictives.
En exploration de données prédictive, il y a deux types d'opérations : la discrimination ou classement, et la régression ou prédiction, tout dépend du type de variable à expliquer. La discrimination s’intéresse aux variables qualitatives, tandis que la régression s’intéresse aux variables continues[b 7].
Les méthodes de classement et de prédiction permettent de séparer des individus en plusieurs classes. Si la classe est connue au préalable et que l'opération de classement consiste à analyser les caractéristiques des individus pour les placer dans une classe, la méthode est dite « supervisée[b 8] ». Dans le cas contraire, on parle de méthodes « non-supervisées », ce vocabulaire étant issu de l'apprentissage automatique. La différence entre les méthodes descriptives de classification que l'on a vues précédemment, et les méthodes prédictives de classement provient du fait que leur objectif est divergent : les premières « réduisent, résument, synthétisent les données[b 4] » pour donner une vision plus claire de l'amas de données, alors que les secondes expliquent une ou plusieurs variables cibles en vue de la prédiction des valeurs de ces cibles pour les nouveaux arrivants.
Exemples
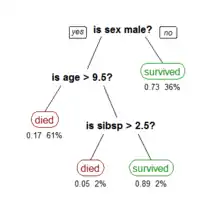
On peut référencer quelques exemples de méthodes prédictives[notes 6], et les présenter selon le domaine d'où elles proviennent.
Parmi les méthodes issues de l'intelligence artificielle, l'analyste pourra utiliser les arbres de décision[48],[49], parfois pour la prédiction, parfois pour discrétiser les données quantitatives[50], [notes 7], le raisonnement par cas, les réseaux de neurones[notes 8], les neurones à base radiale[51],[52] pour la classification et l'approximation de fonctions, ou peut-être les algorithmes génétiques, certains en appui des réseaux bayésiens[53], d'autres comme Timeweaver en recherche d'évènements rares[54].
Si l'analyste est plus enclin à utiliser les méthodes issues de la statistique et des probabilités, il se tournera vers les techniques de régressions linéaires ou non linéaires au sens large[notes 9] pour trouver une fonction d'approximation, l'analyse discriminante de Fisher, la régression logistique, et la régression logistique PLS pour prédire une variable catégorielle, ou bien le modèle linéaire généralisé (GLM), le modèle additif généralisé (GAM) ou modèle log-linéaire, et les modèles de régression multiple postulés et non postulés afin de prédire une variable multidimensionnelle.
Quant à l'inférence bayésienne et plus particulièrement les réseaux bayésiens[55],[56], ils pourront être utile à l'analyste si celui-ci cherche les causes d'un phénomène ou bien cherche la probabilité de la réalisation d'un évènement[57],[58].
S'il souhaite compléter les données manquantes, la méthode des k plus proches voisins (K-nn) reste à sa disposition[59].
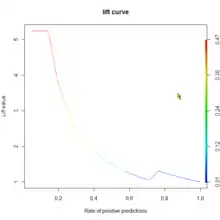
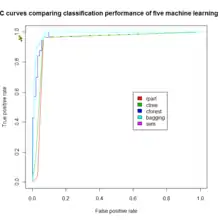
La liste des algorithmes évolue chaque jour, car ils n'ont pas tous le même objet, ne s'appliquent pas aux mêmes données en entrée et aucun n'est optimal dans tous les cas. En outre, ils s'avèrent complémentaires les uns aux autres en pratique et en les combinant intelligemment en construisant des modèles de modèles ou métamodèles, il est possible d'obtenir des gains en performance et en qualité très significatifs. L'ICDM-IEEE a fait en 2006 un classement des 10 algorithmes[47] ayant le plus d'influence dans le monde de l'exploration de données : ce classement est une aide efficace au choix et à la compréhension de ces algorithmes.
L'université Stanford a mis en concurrence à sa rentrée d'automne 2007 deux équipes sur le projet suivant : en s'appuyant sur la base de films visualisés par chaque client d'un réseau de distribution dont les abonnements sont payés par carte magnétique, déterminer l'audience la plus probable d'un film qui n'a pas encore été vu. Une équipe s'est orientée sur une recherche d'algorithmes extrêmement fins à partir des informations de la base, une autre au contraire a pris des algorithmes extrêmement simples, mais a combiné la base fournie par le distributeur au contenu de l’Internet Movie Database (IMDB) pour enrichir ses informations. La seconde équipe a obtenu des résultats nettement plus précis. Un article[60] suggère que l'efficacité de Google tient moins à son algorithme PageRank qu'à la très grande quantité d'information que Google peut corréler par croisement des historiques de requêtes, et par l'analyse du comportement de navigation de ses utilisateurs sur les différents sites.
Avec les moyens modernes de l'informatique l'une ou l'autre de ces deux solutions peut s'envisager dans chaque projet, mais d'autres techniques sont apparues qui ont prouvé leur efficacité pour améliorer la qualité des modèles et leur performance.
Qualité et performance
Un modèle de qualité est un modèle rapide, dont le taux d'erreur doit être le plus bas possible. Il ne doit pas être sensible aux fluctuations de l'échantillon pour ce qui concerne les méthodes supervisées, il doit être robuste et supporter des changements lents intervenants sur les données. En outre, le fait d'être simple, compréhensible et produire des résultats interprétables facilement, augmente sa valeur. Enfin, il est paramétrable pour être réutilisable[61].
Plusieurs indicateurs sont utilisés pour évaluer la qualité d'un modèle, et parmi ceux-ci les courbes ROC et lift, l'indice de Gini et l'erreur quadratique moyenne montrent où se situe la prédiction par rapport à la réalité et donnent ainsi une bonne idée de la valeur de cette composante de la qualité du modèle.
La robustesse et la précision[b 9],[notes 10] sont deux autres facettes de la qualité du modèle. Pour obtenir un modèle performant, la technique consiste à limiter l'hétérogénéité des données, optimiser l’échantillonnage ou combiner les modèles.
La pré-segmentation se propose de classifier la population, puis de construire un modèle sur chacune des classes dans lesquelles les données sont plus homogènes et enfin d'en agréger les résultats.
Avec l'agrégation de modèles, l'analyste applique le même modèle à des échantillons légèrement différents issus de l'échantillon initial, pour ensuite associer les résultats. Le bagging et le boosting étaient les deux techniques les plus efficaces et les plus populaires en 1999[62]. En marketing par exemple, l'algorithme Uplift utilise la technique du bagging pour produire un modèle d'identification de groupes de personnes pouvant répondre à une offre commerciale après sollicitation.
Enfin, la combinaison de modèles conduit l'analyste à appliquer plusieurs modèles sur une même population et à combiner les résultats. Des techniques telles que l'analyse discriminante et les réseaux de neurones par exemple, se marient aisément.
Outils informatiques
Logiciels
La fouille de données n'existerait pas sans outil. L'offre informatique est présente sous la forme de logiciels[63] et aussi sur quelques plateformes spécialisées[64]. De nombreux logiciels sont présents dans la sphère des logiciels commerciaux, mais il en existe aussi dans celle des logiciels libres. Il n'y a pas de logiciels meilleurs que d'autres, tout dépend de ce qu'on veut en faire[65]. Les logiciels commerciaux sont plutôt destinés aux entreprises, ou aux organismes ayant de gros volumes de données à explorer[b 10], tandis que les logiciels libres sont destinés plus particulièrement aux étudiants, à ceux qui veulent expérimenter des techniques nouvelles, et aux PME[b 10]. En 2009[66], les outils les plus utilisés sont, dans l'ordre, SPSS, RapidMiner (en), SAS, Excel, R, KXEN (en), Weka, Matlab, KNIME, Microsoft SQL Server, Oracle DM (en), STATISTICA et CORICO (Iconographie des corrélations). En 2010, R[67] est l'outil le plus utilisé parmi les utilisateurs ayant répondu au sondage de Rexer Analytics[68] et STATISTICA apparaît comme l'outil préféré de la plupart des prospecteurs de données (18 %). STATISTICA, IBM SPSS Modeler, et R ont reçu les taux de satisfaction les plus élevés à la fois en 2010 et 2009 dans ce sondage de Rexer Analytics.
Informatique en nuage
L’informatique en nuage (cloud computing) n’est pas un outil d’exploration de données, mais un ensemble de services web, délivrés par des fournisseurs via l'internet, permettant d’accueillir et/ou d’utiliser des données et des logiciels[69]. Néanmoins, il existe des services qui peuvent être utilisés dans le domaine de l’exploration de données. Oracle Data mining s’expose sur l’IaaS d’Amazon[notes 11] en proposant aux clients une Amazon Machine Image[70] contenant une base de données Oracle incluant une IHM pour la fouille de données ; une image pour R et Python est disponible aussi sur Amazon Web Services [71]. Des acteurs présents exclusivement dans le nuage et spécialisés dans le domaine de la fouille de données proposent leurs services comme Braincube[72], In2Cloud[73], Predixion[74] et Cloud9Analytics[75] entre autres.
Limites et problèmes
L'exploration des données est une technique ayant ses limites et posant quelques problèmes[76].
Limites
Les logiciels ne sont pas auto-suffisants. Les outils d'exploration des données ne proposent pas d'interprétation des résultats, un analyste spécialiste de la fouille de données et une personne connaissant le métier duquel sont extraites les données sont nécessaires pour analyser les livrables du logiciel.
En outre, les logiciels d'exploration de données donnent toujours un résultat, mais rien n'indique qu'il soit pertinent, ni ne donne une indication sur sa qualité. Mais, de plus en plus, des techniques d'aide à l'évaluation sont mises en place dans les logiciels libres ou commerciaux.
Les relations entre les variables ne sont pas clairement définies. Les outils d'exploration des données indiquent que telles et telles variables ont une influence sur la variable à expliquer, mais ne disent rien sur le type de relation, en particulier il n'est pas dit si les relations sont de cause à effet.
De plus, il peut être très difficile de restituer de manière claire soit par des graphes, des courbes ou des histogrammes, les résultats de l'analyse. Le non-technicien aura quelquefois du mal à comprendre les réponses qu'on lui apporte.
Problèmes
Pour un francophone, néophyte de surcroit, le vocabulaire est une difficulté voire un problème. Pour s'en rendre compte, il est intéressant de préciser le vocabulaire rencontré dans les littératures française et anglo-saxonne. En prenant comme référence le vocabulaire anglo-saxon[b 11], le clustering est compris en exploration de données comme une segmentation, en statistiques et en analyse des données comme une classification. La classification en anglais correspond à la classification en exploration de données, à l'analyse discriminante ou au classement en analyse de données à la française et à un problème de décision en statistique. Enfin, les decision trees sont des arbres de décision en exploration de données, et on peut entendre parler de segmentation dans ce cas dans le domaine de l'analyse des données. La terminologie n'est pas claire.[réf. nécessaire]
La qualité des données, c'est-à-dire la pertinence et la complétude des données, est une nécessité pour l'exploration des données, mais ne suffit pas. Les erreurs de saisies, les enregistrements doublonnés, les données non renseignées ou renseignées sans référence au temps affectent aussi la qualité des données. Les entreprises mettent en place des structures et des démarches d'assurance qualité des données pour pouvoir répondre efficacement aux nouvelles réglementations externes, aux audits internes, et augmenter la rentabilité de leurs données qu'elles considèrent comme faisant partie de leur patrimoine[77].
L'interopérabilité d'un système est sa capacité à fonctionner avec d'autres systèmes, créés par des éditeurs différents. Les systèmes d'exploration de données doivent pouvoir travailler avec des données venant de plusieurs systèmes de gestion de bases de données, de type de fichier, de type de données et de capteurs différents. En outre, l’interopérabilité a besoin de la qualité des données. Malgré les efforts de l'industrie en matière d'interopérabilité, il semble que dans certains domaines ce ne soit pas la règle[78].
Les données sont collectées dans le but de répondre à une question posée par le métier. Un risque de l'exploration de données est l'utilisation de ces données dans un autre but que celui assigné au départ. Le détournement des données est l'équivalent d'une citation hors de son contexte. En outre, elle peut conduire à des problèmes éthiques.
La vie privée des personnes peut être menacée par des projets d'exploration de données, si aucune précaution n'est prise, notamment dans la fouille du web et l'utilisation des données personnelles collectées sur Internet où les habitudes d'achats, les préférences, et même la santé des personnes peuvent être dévoilées. Un autre exemple est fourni par l'Information Awareness Office et en particulier le programme Total Information Awareness (TIA)[79] qui exploitait pleinement la technologie d'exploration de données et qui fut un des projets « post-11 septembre » que le Congrès des États-Unis avait commencé à financer, puis qu'il a abandonné à cause des menaces particulièrement importantes que ce programme faisait peser sur la vie privée des citoyens américains. Mais même sans être dévoilées, les données des personnes recueillies par les entreprises, via les outils de gestion de la relation client (CRM), les caisses enregistreuses, les DAB, les cartes santé, etc., peuvent conduire, avec les techniques de fouille de données, à classer les personnes en une hiérarchie de groupes, de bons à mauvais, prospects, clients, patients, ou n'importe quel rôle que l'on joue à un instant donné dans la vie sociale, selon des critères inconnus des personnes elles-mêmes[80],[81]. Dans cette optique, et pour corriger cet aspect négatif, Rakesh Agrawal et Ramakrishnan Sikrant s'interrogent sur la faisabilité d'une exploration de données qui préserverait la vie privée des personnes[82],[notes 12]. Le stockage des données nécessaire à la fouille pose un autre problème dans la mesure où les données numériques peuvent être piratées. Et dans ce cas l'éclatement des données sur des bases de données distribuées[83] et la cryptographie font partie des réponses techniques qui existent et qui peuvent être mises en place par les entreprises.
Fouilles spécialisées
Certaines entreprises ou groupes se sont spécialisés, avec par exemple Acxiom, Experian Information Solutions, D & B, et Harte-Hanks pour les données de consommation ou Nielsen N.V. pour les données d'audience.
Outre l'exploration de données (décrite plus haut) qu'on peut maintenant qualifier de classique, des spécialisations techniques de l'exploration de données telles que la fouille d'images (image mining), la fouille du web (web data mining), la fouille de flots de données (data stream mining) et la fouille de textes (text mining) sont en plein développement dans les années 2010 et concentrent l'attention de nombreux chercheurs et industriels, y compris pour les risques de diffusion de données personnelles qu'elles font courir aux individus.
Des logiciels de catégorisation des individus selon leur milieu social et leurs caractérisations de consommateurs sont utilisés par ces entreprises (ex : Claritas Prizm (créé par Claritas Inc. et racheté par Nielsen Company.
Par types de données
La fouille audio, technique récente, parfois apparentée à la fouille de données, permet de reconnaître des sons dans un flux audio. Elle sert principalement dans le domaine de la reconnaissance vocale et/ou s'appuie sur elle.
La fouille d'images[84] est la technique qui s’intéresse au contenu de l'image. Elle extrait des caractéristiques dans un ensemble d'images, par exemple du web, pour les classer, les regrouper par type ou bien pour reconnaître des formes dans une image dans le but de chercher des copies de cette image ou de détecter un objet particulier, par exemple.
La fouille de textes est l'exploration des textes en vue d'en extraire une connaissance de haute qualité. Cette technique est souvent désignée sous l'anglicisme text mining. C'est un ensemble de traitements informatiques consistant à extraire des connaissances selon un critère de nouveauté ou de similarité, dans des textes produits par des humains pour des humains. Dans la pratique, cela revient à mettre en algorithmes un modèle simplifié des théories linguistiques dans des systèmes informatiques d'apprentissage et de statistiques. Les disciplines impliquées sont donc la linguistique calculatoire, l'ingénierie du langage, l'apprentissage artificiel, les statistiques et l'informatique.
Par environnements techniques
Il s'agit d'exploiter, avec la fouille du web, l'énorme source de données que constitue le web et trouver des modèles et des schémas dans l'usage, le contenu et la structure du web. La fouille de l'usage du web (Web usage mining ou Web log mining) est le processus d'extraction d'informations utiles stockées dans les journaux des serveurs. Cette fouille exploite la fouille de textes pour analyser les documents textes. La fouille de la structure du web est le processus d'analyse des relations, inconnues à priori, entre documents ou pages stockés sur le web.
La fouille de flots de données (data stream mining)[85] est la technique qui consiste à explorer les données qui arrivent en un flot continu[86], illimité, avec une grande rapidité, et dont certains paramètres fondamentaux se modifient avec le temps : par exemple, l'analyse des flots de données émis par des capteurs automobiles[87]. Mais des exemples d'applications peuvent être trouvés dans les domaines des télécommunications, de la gestion des réseaux, de la gestion des marchés financiers, de la surveillance, et dans les domaines d'activités de la vie de tous les jours, plus proches des personnes, comme l'analyse des flux de GAB, des transactions par cartes de crédit, etc.
Par domaines d'activités
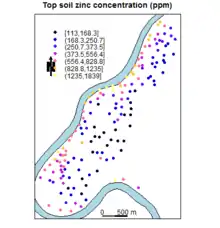
La fouille de données spatiales[88] (Spatial data mining) est la technique d'exploration de données géographiques à notre échelle sur Terre, mais aussi astronomiques ou microscopiques, dont le but est de trouver des motifs intéressants dans les données contenant à la fois du texte, des données temporelles ou des données géométriques, telles que des vecteurs, des trames ou des graphes. Les données spatiales donnent des informations à des échelles différentes, fournies par des techniques différentes, sous des formats différents, dans une période de temps souvent longue en vue de l'observation des changements. Les volumes sont donc très importants, les données peuvent être imparfaites, bruitées. De plus, les relations entre les données spatiales sont souvent implicites : les relations ensemblistes, topologiques, directionnelles et métriques se rencontrent fréquemment dans cette spécialisation. La fouille de données spatiales est donc particulièrement ardue.
On utilise la fouille de données spatiales pour explorer les données des sciences de la terre, les données cartographiques du crime, celles des recensements, du trafic routier, des foyers de cancer[89], etc.
Dans le futur
L’avenir de l'exploration de données dépend de celui des données numériques. Avec l’apparition du Web 2.0, des blogs, des wikis et des services en nuages[90], il y a une explosion du volume des données numériques et les gisements de matière première pour la fouille de données sont donc importants.
De nombreux domaines exploitent encore peu la fouille de données pour leurs besoins propres. L’analyse des données venant de la blogosphère n’en est qu’à son début. Comprendre l’« écologie de l’information[notes 13],[b 12]» pour analyser le mode de fonctionnement des médias de l’Internet par exemple ne fait que commencer.
Pour peu que les problèmes liés à la vie privée des personnes[b 13],[b 14] soient réglés, la fouille de données peut aider à traiter des questions dans le domaine médical[b 15], et notamment dans la prévention des risques hospitaliers[b 15].
Sans aller jusqu'à la science-fiction de Minority Report, les techniques de profilage sans a priori sont rendues possibles par l'exploration de données[91], pouvant poser quelques problèmes éthiques nouveaux[92]. Un documentaire de BBC Horizon[93] résume une partie de ces questions.
Enfin, avec l’apparition de nouvelles données et de nouveaux domaines, les techniques continuent de se développer[b 16].
Notes et références
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Data mining » (voir la liste des auteurs).
Notes
- Terme recommandé au Canada par l'OQLF, et en France par la DGLFLF (Journal officiel du 27 février 2003) et par FranceTerme
- en suivant le même exemple, il permet de répondre à la question : « Quel pourrait être le chiffre d'affaires dans un mois ? »
- . Ces distributions sont faciles à calculer, et on trouve parmi elles des lois déjà largement utilisées (loi normale, distribution exponentielle négative, lois de Zipf et de Mandelbrot...), par des méthodes sans rapport avec celles qui les ont établies. Le test de fitness d'une distribution au modèle du « test Psi » de calcul de l'entropie résiduelle, est asymptotiquement équivalent à la Loi du χ².
- Voir dans ce document les efforts de standardisation et d'interopérabilité effectués par l'industrie : (en) Arati Kadav, Aya Kawale et Pabitra Mitra, « Data Mining Standards » [PDF], sur datamininggrid.org (consulté le )
- Par exemple, un programme gestionnaire de messages électroniques pourrait tenter de classer un e-mail dans la catégorie des e-mails légitimes ou bien dans celle des pourriels. Les algorithmes généralement utilisés incluent les arbres de décision, les plus proches voisins, la classification naïve bayésienne, les réseaux neuronaux et les séparateurs à vaste marge (SVM)
- Dont on peut trouver, pour certaines, la description ici : Guillaume Calas, « Études des principaux algorithmes de data mining » [PDF], sur guillaume.calas.free.fr, (consulté le )
- Comme CART, CHAID, ECHAID, QUEST, C5, C4.5 et les forêts d'arbres décisionnels
- Tels que les perceptrons mono ou multicouches avec ou sans rétropropagation des erreurs
- Telles que la régression linéaire, linéaire multiple, logistique, PLS, ANOVA, MANOVA, ANCOVA ou MANCOVA.
- Voir Glossaire du data mining pour la définition de « robustesse » et « précision ».
- IaaS signifiant Infrastructure as a service dénommé Amazon Elastic Compute Cloud chez Amazon
- Puisque les modèles de l'exploration de données concernent les données agrégées d'où sont éliminées les données personnelles.
- Selon Tim Finin, Anupam Joshi, Pranam Kolari, Akshay Java, Anubhav Kale et Amit Karandikar, « The information ecology of social media and online communities », sur aisl.umbc.edu (consulté le ).
Ouvrages spécialisés
- Tufféry 2010, p. 506
- Nisbet, Elder et Miner 2009, p. 733
- Tufféry 2010, p. 44
- Tufféry 2010, p. 161
- Tufféry 2010, p. 198
- Tufféry 2010, p. 244
- Tufféry 2010, p. 297
- Nisbet, Elder et Miner 2009, p. 235
- Tufféry 2010, p. 518
- Tufféry 2010, p. 121
- Tufféry 2010, p. 158
- Kargupta et al. 2009, p. 283
- Kargupta et al. 2009, p. 357
- Kargupta et al. 2009, p. 420
- Kargupta et al. 2009, p. 471
- Kargupta et al. 2009, p. 1-281
Autres références
- « Définition de l’exploration de données Data Mining »
- « Atelier de travail Etalab du 13 octobre 2011 : Datajournalisme » (4e Workshop d'Etalab, 70 participants le 13 octobre 2011), avec vidéos en ligne, consulté 8 octobre 2013.
- (en) Kurt Thearling, « An Introduction to Data Mining », sur thearling.com (consulté le ).
- Jean-Claude Oriol, « Une approche historique de la statistique » [PDF], sur statistix.fr (consulté le )
- (en) Myron Tribus, Rational descriptions, decisions, and designs, , 478 p. (lire en ligne).
- (en) Nikhil Pal et Lakhmi Jain, Advanced techniques in knowledge discovery and data mining, Springer, , 254 p. (ISBN 978-1-85233-867-1)
- (en) Carole Albouy, « Il était une fois ... le data mining », sur lafouillededonnees.blogspirit.com (consulté le )
- (en) Patricia Cerrito, « A Data Mining Applications Area in the Department of Mathematics » [PDF], sur math.louisville.edu (consulté le )
- (en) Maryann Lawlor, « Smart Companies Dig Data », sur afcea.org (consulté le )
- Christine Frodeau, « Data mining, Outil de Prediction du Comportement du Consommateur » [PDF], sur creg.ac-versailles.fr (consulté le )
- (en) Colleen McCue, Data Mining and Predictive Analysis : intelligence gathering and crime analysis, Amsterdam/Boston, Elsevier, , 313 p. (ISBN 978-0-7506-7796-7)
- Frank audet et Malcolm Moore, « Amélioration de la qualité dans un centre d’appel » [PDF], sur jmp.com (consulté le )
- (en) Henry Abarbanel, Curtis Callan, William Dally, Freeman Dyson, Terence Hwa, Steven Koonin, Herbert Levine, Oscar Rothaus, Roy Schwitters, Christopher Stubbs et Peter Weinberger, « Data mining and the human genome » [PDF], sur fas.org (consulté le ), p. 7
- (en) « Industries / Fields for Analytics / Data Mining in 2010 », sur kdnuggets.com, (consulté le )
- (en) Yi Peng, Gang Kou, Yong Shi et Zhengxin Chen, « A Descriptive Framework for the Field of Data Mining and Knowledge Discovery », International Journal of Information Technology and Decision Making, vol. 7, no 4, , p. 639 à 682 (10.1142/S0219622008003204)
- (en) « SIGKDD : Site officiel », sur sigkdd.org (consulté le )
- (en) « ACM SIGKDD : Conferences », sur kdd.org (consulté le )
- (en) ACM, New York, « SIGKDD Explorations », sur kdd.org (consulté le )
- (en) « 5th (2009) », sur dmin--2009.com (consulté le )
- (en) « 4th (2008) », sur dmin-2008.com (consulté le )
- (en) « 3rd (2007) », sur dmin-2007.com (consulté le )
- (en) « 2d (2006) », sur dmin-2006.com (consulté le )
- (en) « 1st (2005) », sur informatik.uni-trier.de (consulté le )
- (en) « ICDM : Site officiel », sur cs.uvm.edu (consulté le )
- (en) « IEEE International Conference on Data Mining », sur informatik.uni-trier.de (consulté le )
- (en) « ICDM09, Miami, FL », sur cs.umbc.edu (consulté le )
- (en) « ICDM08, Pisa (Italy) », sur icdm08.isti.cnr.it (consulté le )
- (en) « ICDM07, Omaha, NE », sur ist.unomaha.edu (consulté le )
- (en) « ICDM06, Hong Kong », sur comp.hkbu.edu.hk (consulté le )
- (en) « ICDM05, Houston, TX », sur cacs.ull.edu (consulté le )
- (en) « ICDM04, Brighton (UK) », sur icdm04.cs.uni-dortmund.de (consulté le )
- (en) « ICDM01, San Jose, CA. », sur cs.uvm.edu (consulté le )
- (en) « CRoss Industry Standard Process for Data Mining : Process Model », sur crisp-dm.org, (consulté le )
- (en) Usama Fayyad, Gregory Piatetsky-Shapiro et Padhraic Smyth, « From Data Mining to Knowledge Discovery in Databases » [PDF], sur kdnuggets.com, (consulté le )
- (en) Ana Azevedo et M.F. Santos, « KDD, SEMMA AND CRISP-DM: A PARALLEL OVERVIEW », IADIS European Conf. Data, (lire en ligne)
- (en) « What are cross-validation and bootstrapping? », sur faqs.org (consulté le )
- (en) Jing Gao, Wei Fan et Jiawei Han, « On the Power of Ensemble: Supervised and Unsupervised Methods Reconciled », sur ews.uiuc.edu (consulté le )
- (en) Mary McGlohon, « Data Mining Disasters: a report » [PDF], sur cs.cmu.edu (consulté le ), p. 2
- (en) « An Introduction to Ensemble Methods », sur RDC (consulté le )
- (en) Dorian Pyle, Data Preparation for Data Mining, Morgan Kaufmann, , 560 p. (ISBN 978-1-55860-529-9, lire en ligne)
- (en) Kurt Thearling, « ''An Introduction to Data Mining », sur thearling.com (consulté le ), p. 17
- Stéphane Tufféry, « Les techniques descriptives » [PDF], sur data.mining.free.fr, (consulté le ), p. 5
- Jacques Baillargeon, « Analyse factorielle exploratoire » [PDF], sur uqtr.ca, (consulté le ), p. 4
- Philippe Besse et Alain Baccini, « Exploration Statistique » [PDF], sur math.univ-toulouse.fr, (consulté le ), p. 7 et suiv.
- Alexandre Aupetit, « Réseaux de neurones artificiels : une petite introduction », sur labo.algo.free.fr, (consulté le )
- (en) Nikhil R. Pal, Kuhu Pal, James M. Keller et James C. Bezdek, « Fuzzy c-Means Clustering of Incomplete Data » [PDF], sur comp.ita.br, (consulté le )
- (en) « ICDM Top 10 algorithms in data mining » [PDF], sur cs.uvm.edu (consulté le )
- (en) Wei-Yin Loh et Yu-Shan Shih, « Split Selection Methods for Classification Trees » [PDF], sur math.ccu.edu.tw, (consulté le )
- (en) Leo Breiman, « Random Forests » [PDF], sur springerlink.com, (consulté le )
- Ricco Rakotomalala, « Arbres de Décision » [PDF], sur www-rocq.inria.fr, (consulté le )
- (en) Simon Haykin, Neural Networks : A comprehensive Foundation, Prentice Hall, , 842 p. (ISBN 978-0-13-273350-2)
- M. Boukadoum, « Réseaux de neurones à base radiale » [ppt], sur labunix.uqam.ca (consulté le )
- Jean-Marc Trémeaux, « Algorithmes génétiques pour l'identification structurelle des réseaux bayésiens » [PDF], sur naku.dohcrew.com, (consulté le )
- Thomas Vallée et Murat Yıldızoğlu, « Présentation des algorithmes génétiques et de leurs applications en économie » [PDF], sur sc-eco.univ-nantes.fr, (consulté le ), p. 15
- Olivier Parent et Julien Eustache, « Les Réseaux Bayésiens » [PDF], sur liris.cnrs.fr, (consulté le )
- Gilles Balmisse, « Les Réseaux Bayésiens » [PDF], sur gillesbalmisse.com, (consulté le )
- Samos, « Les Réseaux Bayésiens » [PDF], sur samos.univ-paris1.fr, (consulté le )
- « Pour sortir de l'incertitude, entrez dans l'ère des réseaux bayésiens », Bayesia (consulté le )
- Valérie Monbet, « Les données manquantes », sur perso.univ-rennes1.fr (consulté le ), p. 27
- Didier Durand, « PageRank de Google : l'algorithme prend en compte 200 paramètres ! », sur media-tech.blogspot.com, (consulté le )
- Bertrand Liaudet, « Cours de Data Mining 3 : Modelisation Présentation Générale » [PDF], sur bliaudet.free.fr (consulté le )
- (en) David Opitz et Richard Maclin, « Popular Ensemble Methods: An Empirical Study » [PDF], sur d.umn.edu, (consulté le )
- (en) « Software Suites for Data Mining, Analytics, and Knowledge Discovery », sur kdnuggets (consulté le )
- « Plateforme de datamining pour les editeurs d'univers virtuels », sur marketingvirtuel.fr (consulté le )
- (en) Dean W. Abbott, I. Philip Matkovsky et John Elder IV, « 1998 IEEE International Conference on Systems, Man, and Cybernetics, San Diego, CA » [PDF], sur datamininglab.com, (consulté le )
- (en) « Data Mining Tools Used Poll », sur kdnuggets.com, (consulté le )
- (en) Rexer Analytics, « 2010 Data Miner Survey », sur rexeranalytics.com (consulté le )
- (en) « Rexer Analytics », Rexer Analytics (consulté le )
- Dave Wells, « What’s Up with Cloud Analytics? », sur b-eye-network.com (consulté le )
- John Smiley et Bill Hodak, « Oracle Database on Amazon EC2 : An Oracle White Paper », sur oracle.com (consulté le )
- Drew Conway, « Amazon EC2 configuration for scientific computing in Python and R », sur kdnuggets.com (consulté le )
- ipleanware.com
- « In2Clouds Solutions », In2Cloud (consulté le )
- Predixion, « Cloud Predixion Solutions », sur predixionsoftware.com (consulté le )
- « Cloud9 Solution Overview », Cloud9 (consulté le )
- (en) Jeffrey Seifer, « CRS report for congress » [PDF], sur biotech.law.lsu.edu, (consulté le )
- Laetitia Hardy, « Pourquoi la qualité des données devient incontournable au sein de l’entreprise? », sur Decideo, (consulté le )
- (en) Jeffrey Seifert, « CRS report for congress » [PDF], sur biotech.law.lsu.edu, (consulté le ), p. 27
- (en) « International Workshop on Practical Privacy-Preserving Data Mining », sur cs.umbc.edu, (consulté le )
- (en) Martin Meint et Jan Möller, « Privacy Preserving Data Mining » [PDF], sur fidis.net (consulté le )
- (en) Kirsten Wahlstrom, John F. Roddick, Rick Sarre, Vladimir Estivill-Castro et Denise de Vries, « Legal and Technical Issues of Privacy Preservation in Data Mining », sur irma-international.org, (consulté le )
- (en) Rakesh Agrawal et Ramakrishnan Sikrant, « privacy-Preserving Data mining » [PDF], sur cs.utexas.edu (consulté le )
- (en) Murat Kantarcioglu, « Introduction to Privacy Preserving Distributed Data Mining » [PDF], sur wiki.kdubiq.org (consulté le )
- Patrick Gros, « Nouvelles de l’AS fouille d’images & Émergence de caractéristiques sémantiques » [PDF], sur liris.cnrs.fr, (consulté le )
- (en) Mohamed Medhat Gaber, Arkady Zaslavsky et Shonali Krishnaswamy, « Data Streams: A Review » [PDF], sur sigmod.org, (consulté le )
- (en) Chih-Hsiang Li, Ding-Ying Chiu, Yi-Hung Wu et Arbee L. P. Chen, « Mining Frequent Itemsets from Data Streams with a Time-Sensitive Sliding Window » [PDF], sur siam.org, (consulté le )
- (en) Hillol Kargupta, Ruchita Bhargava, Kun Liu, Michael Powers, Patrick Blair, Samuel Bushra, James Dull, Kakali Sarkar, Martin Klein, Mitesh Vasa et David Handy, « VEDAS : A Mobile and Distributed Data Stream Mining System for Real-Time Vehicle Monitoring » [PDF], sur siam.org, (consulté le )
- (en) « Spatial Database and Spatial Data Mining Research Group : Site officiel », sur spatial.cs.umn.edu, (consulté le )
- (en) Shashi Shekhar et Pusheng Zhang, « Spatial Data Mining: Accomplishments and Research Needs » [PDF], sur spatial.cs.umn.edu, (consulté le )
- « IDC pronostique une explosion du volume de données produites dans le monde d'ici 10 ans », sur lemagit.fr (consulté le )
- (en) Joseph A Bernstein, « Big Idea : Seeing Crime Before It Happens »
 , sur discovermagazine.com, (consulté le ).
, sur discovermagazine.com, (consulté le ). - (en) « FBI might use profiling in terror investigations », sur msnbc.com, (consulté le ).
- The Age of Big Data
Voir aussi
Statistiques
- Analyse multivariée
- Analyse des données
- Big data
- Segmentation (marketing)
- Nielsen PRIZM (système de catégorisation des consommateurs)
Intelligence artificielle
- Apprentissage automatique
- Traitement automatique du langage naturel
- Linguistique calculatoire
- Carte auto adaptative (exemple de Réseau de neurones : carte de Kohonen (SOM/TOM))
Aide à la décision
Bibliographie
- (en) Robert Nisbet, John Elder et Gary Miner, Handbook of Statistical Analysis & Data Mining Applications, Amsterdam/Boston, Academic Press, , 823 p. (ISBN 978-0-12-374765-5)

- (en) Hillol Kargupta, Jiawei Han, Philip Yu, Rajeev Motwani et Vipin Kumar, Next Generation of Data Mining, CRC Press, , 3e éd., 605 p. (ISBN 978-1-4200-8586-0)
- Stéphane Tufféry, Data Mining et statistique décisionnelle : l'intelligence des données, Paris, éditions Technip, , 705 p. (ISBN 978-2-7108-0946-3, lire en ligne)
- (en) Phiroz Bhagat, Pattern Recognition inndustry, Amsterdam/Boston/London, Elsevier, , 200 p. (ISBN 978-0-08-044538-0)
- (en) (en) Richard O. Duda, Peter E. Hart, David G. Stork, Pattern Classification, Wiley-interscience, (ISBN 0-471-05669-3) [détail des éditions]
- (en) Yike Guo et Robert Grossman, High Performance Data Mining : Scaling Algorithms, Applications and Systems, Berlin, Springer, , 112 p. (ISBN 978-0-7923-7745-0, lire en ligne)
- (en) Ingo Mierswa, Michael Wurst, Ralf Klinkenberg, Martin Scholz et Tim Euler, « YALE: Rapid Prototyping for Complex Data Mining Tasks », Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD-06), ACM, , p. 935-940 (ISBN 1595933395, DOI 10.1145/1150402.1150531, présentation en ligne)
- Daniel Larose (trad. Thierry Vallaud), Des données à la connaissance : Une introduction au data-mining (1Cédérom), Vuibert, , 223 p. (ISBN 978-2-7117-4855-6)
- René Lefébure et Gilles Venturi, Data Mining : Gestion de la relation client : personnalisations de site web, Eyrolles, , 392 p. (ISBN 978-2-212-09176-2)
- (en) Pascal Poncelet, Florent Masseglia et Maguelonne Teisseire, Data Mining Patterns : New Methods and Applications, Idea Group Reference, , 307 p. (ISBN 978-1-59904-162-9)
- (en) Pang-Ning Tan, Michael Steinbach et Vipin Kumar, Introduction to Data Mining, Pearson Addison Wesley, , 769 p. (ISBN 978-0-321-32136-7 et 0-321-32136-7, OCLC 58729322)
- (en) Ian Witten et Eibe Frank, Data Mining : Practical Machine Learning Tools and Techniques, Morgan Kaufmann, , 371 p. (ISBN 978-1-55860-552-7, lire en ligne)
- (en) Stéphane Tufféry, Data Mining and Statistics for Decision Making, John Wiley & Sons, , 716 p. (ISBN 978-0-470-68829-8)
- (en) B. Efron, The Annals of Statistics : Bootstrap methods: Another look at the jackknife, Institute of Mathematical Statistics, (ISSN 0090-5364)
- (en) Leo Breiman, Machine Learning : Bagging predictors, Kluwer Academic Publishers Hingham, (ISSN 0885-6125)
 Portail des bases de données
Portail des bases de données  Portail des probabilités et de la statistique
Portail des probabilités et de la statistique - Portail des données