Réseau de neurones artificiels
Un réseau de neurones artificiels[1],[2], ou réseau neuronal artificiel[1], est un système dont la conception est à l'origine schématiquement inspirée du fonctionnement des neurones biologiques, et qui par la suite s'est rapproché des méthodes statistiques[3].
Pour les articles homonymes, voir Réseau de neurones (biologie) et Réseau (homonymie).
Les réseaux de neurones sont généralement optimisés par des méthodes d’apprentissage de type probabiliste, en particulier bayésien. Ils sont placés d’une part dans la famille des applications statistiques, qu’ils enrichissent avec un ensemble de paradigmes[4] permettant de créer des classifications rapides (réseaux de Kohonen en particulier), et d’autre part dans la famille des méthodes de l’intelligence artificielle auxquelles ils fournissent un mécanisme perceptif indépendant des idées propres de l'implémenteur, et des informations d'entrée au raisonnement logique formel (voir Deep Learning).
En modélisation des circuits biologiques, ils permettent de tester quelques hypothèses fonctionnelles issues de la neurophysiologie, ou encore les conséquences de ces hypothèses pour les comparer au réel.
Historique
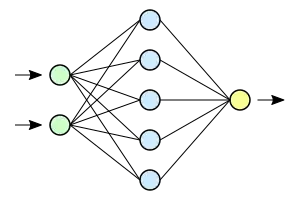
Les réseaux neuronaux sont construits sur un paradigme biologique, celui du neurone formel (comme les algorithmes génétiques le sont sur la sélection naturelle). Ces types de métaphores biologiques sont devenues courantes avec les idées de la cybernétique et biocybernétique. Selon la formule de Yann Le Cun, celui-ci ne prétend pas davantage décrire le cerveau qu'une aile d'avion, par exemple, copie celle d'un oiseau[pertinence contestée][5]. En particulier le rôle des cellules gliales n'est pas simulé.
Neurone formel
Les neurologues Warren McCulloch et Walter Pitts publièrent dès la fin des années 1950 les premiers travaux sur les réseaux de neurones, avec un article fondateur : What the frog’s eye tells the frog’s brain[6] (Ce que l'œil d'une grenouille dit à son cerveau). Ils constituèrent ensuite un modèle simplifié de neurone biologique communément appelé neurone formel. Ils montrèrent que des réseaux de neurones formels simples peuvent théoriquement réaliser des fonctions logiques, arithmétiques et symboliques complexes.
Le neurone formel est conçu comme un automate doté d'une fonction de transfert qui transforme ses entrées en sortie selon des règles précises. Par exemple, un neurone somme ses entrées, compare la somme résultante à une valeur seuil, et répond en émettant un signal si cette somme est supérieure ou égale à ce seuil (modèle ultra-simplifié du fonctionnement d'un neurone biologique). Ces neurones sont par ailleurs associés en réseaux dont la topologie des connexions est variable : réseaux proactifs, récurrents, etc. Enfin, l'efficacité de la transmission des signaux d'un neurone à l'autre peut varier : on parle de « poids synaptique », et ces poids peuvent être modulés par des règles d'apprentissage (ce qui mime la plasticité synaptique des réseaux biologiques).
Une fonction des réseaux de neurones formels, à l’instar du modèle vivant, est d'opérer rapidement des classifications et d'apprendre à les améliorer. À l’opposé des méthodes traditionnelles de résolution informatique, on ne doit pas construire un programme pas à pas en fonction de la compréhension de celui-ci. Les paramètres importants de ce modèle sont les coefficients synaptiques et le seuil de chaque neurone, et la façon de les ajuster. Ce sont eux qui déterminent l'évolution du réseau en fonction de ses informations d'entrée. Il faut choisir un mécanisme permettant de les calculer et de les faire converger si possible vers une valeur assurant une classification aussi proche que possible de l'optimale. C’est ce qu'on nomme la phase d’apprentissage du réseau. Dans un modèle de réseaux de neurones formels, apprendre revient donc à déterminer les coefficients synaptiques les plus adaptés à classifier les exemples présentés.
Perceptron
Les travaux de McCulloch et Pitts n’ont pas donné d’indication sur une méthode pour adapter les coefficients synaptiques. Cette question au cœur des réflexions sur l’apprentissage a connu un début de réponse grâce aux travaux du physiologiste canadien Donald Hebb sur l’apprentissage en 1949 décrits dans son ouvrage The Organization of Behaviour[7]. Hebb a proposé une règle simple qui permet de modifier la valeur des coefficients synaptiques en fonction de l’activité des unités qu’ils relient. Cette règle aujourd’hui connue sous le nom de « règle de Hebb » est presque partout présente dans les modèles actuels, même les plus sophistiqués.

À partir de cet article, l’idée se sema au fil du temps dans les esprits, et elle germa dans l’esprit de Frank Rosenblatt en 1957 avec le modèle du perceptron. C’est le premier système artificiel capable d’apprendre par expérience, y compris lorsque son instructeur commet quelques erreurs (ce en quoi il diffère nettement d’un système d’apprentissage logique formel).
En 1969, un coup grave fut porté à la communauté scientifique gravitant autour des réseaux de neurones : Marvin Lee Minsky et Seymour Papert publièrent un ouvrage mettant en exergue quelques limitations théoriques du perceptron, et plus généralement des classifieurs linéaires, notamment l’impossibilité de traiter des problèmes non linéaires ou de connexité[8]. Ils étendirent implicitement ces limitations à tous modèles de réseaux de neurones artificiels. Paraissant alors dans une impasse, la recherche sur les réseaux de neurones perdit une grande partie de ses financements publics, et le secteur industriel s’en détourna aussi. Les fonds destinés à l’intelligence artificielle furent redirigés plutôt vers la logique formelle[9]. Cependant, les solides qualités de certains réseaux de neurones en matière adaptative (e.g. Adaline), leur permettant de modéliser de façon évolutive des phénomènes eux-mêmes évolutifs, les amèneront à être intégrés sous des formes plus ou moins explicites dans le corpus des systèmes adaptatifs; utilisés dans le domaine des télécommunications ou celui du contrôle de processus industriels.
En 1982, John Joseph Hopfield, physicien reconnu, donna un nouveau souffle au neuronal en publiant un article introduisant un nouveau modèle de réseau de neurones (complètement récurrent)[10]. Cet article eut du succès pour plusieurs raisons, dont la principale était de teinter la théorie des réseaux de neurones de la rigueur propre aux physiciens. Le neuronal redevint un sujet d’étude acceptable, bien que le modèle de Hopfield souffrît des principales limitations des modèles des années 1960, notamment l’impossibilité de traiter les problèmes non linéaires.
Perceptron multicouche
À la même date, les approches algorithmiques de l’intelligence artificielle furent l’objet de désillusion, leurs applications ne répondant pas aux attentes. Cette désillusion motiva une réorientation des recherches en intelligence artificielle vers les réseaux de neurones (bien que ces réseaux concernent la perception artificielle plus que l’intelligence artificielle à proprement parler). La recherche fut relancée et l’industrie reprit quelque intérêt au neuronal (en particulier pour des applications comme le guidage de missiles de croisière). En 1984 (?), c’est le système de rétropropagation du gradient qui est le sujet le plus débattu dans le domaine.
Une révolution survient alors dans le domaine des réseaux de neurones artificiels : une nouvelle génération de réseaux de neurones, capables de traiter avec succès des phénomènes non linéaires : le perceptron multicouche ne possède pas les défauts mis en évidence par Marvin Minsky. Proposé pour la première fois par Paul Werbos, le perceptron multi-couche apparait en 1986 introduit par David Rumelhart, et, simultanément, sous une appellation voisine, chez Yann Le Cun. Ces systèmes reposent sur la rétropropagation du gradient de l’erreur dans des systèmes à plusieurs couches, chacune de type Adaline de Bernard Widrow, proche du perceptron de Rumelhart.
Les réseaux de neurones ont par la suite connu un essor considérable, et ont fait partie des premiers systèmes à bénéficier de l’éclairage de la théorie de la « régularisation statistique » introduite par Vladimir Vapnik en Union soviétique et popularisée en Occident depuis la chute du mur. Cette théorie, l’une des plus importantes du domaine des statistiques, permet d’anticiper, d’étudier et de réguler les phénomènes liés au surapprentissage. On peut ainsi réguler un système d’apprentissage pour qu’il arbitre au mieux entre une modélisation pauvre (exemple : la moyenne) et une modélisation trop riche qui serait optimisée de façon illusoire sur un nombre d’exemples trop petit, et serait inopérant sur des exemples non encore appris, même proches des exemples appris. Le surapprentissage est une difficulté à laquelle doivent faire face tous les systèmes d’apprentissage par l’exemple, que ceux-ci utilisent des méthodes d’optimisation directe (e.g. régression linéaire), itératives (e.g., l'algorithme du gradient), ou itératives semi-directes (gradient conjugué, espérance-maximisation...) et que ceux-ci soient appliqués aux modèles statistiques classiques, aux modèles de Markov cachés ou aux réseaux de neurones formels[11].
Réseau neuronal convolutif
Les réseaux de neurones évoluent avec un nouveau type de réseau non complètement connecté, pour alléger les modèles en nombre de paramètres, et améliorer les performances et leur capacité de généralisation. Une des première application a été la reconnaissance automatique des codes postaux US, avec le réseau LeNet-5[12]. En apprentissage automatique, un réseau de neurones convolutifs ou réseau de neurones à convolution (en anglais CNN ou ConvNet pour Convolutional Neural Networks) est un type de réseau de neurones artificiels acycliques (feed-forward), dans lequel le motif de connexion entre les neurones est inspiré par le cortex visuel des animaux. Les neurones de cette région du cerveau sont arrangés de sorte qu'ils correspondent à des régions qui se chevauchent lors du pavage du champ visuel. Leur fonctionnement est inspiré par les processus biologiques, ils consistent en un empilage multicouche de perceptrons, dont le but est de prétraiter de petites quantités d'informations. Les réseaux neuronaux convolutifs ont de larges applications dans la reconnaissance d'image et vidéo, les systèmes de recommandation et le traitement du langage naturel.
Utilité
Les réseaux de neurones, en tant que systèmes capables d'apprendre, mettent en œuvre le principe de l'induction, c’est-à-dire l'apprentissage par l'expérience. Par confrontation avec des situations ponctuelles, ils infèrent un système de décision intégré dont le caractère générique est fonction du nombre de cas d'apprentissages rencontrés et de leur complexité par rapport à la complexité du problème à résoudre. Par opposition, les systèmes symboliques capables d'apprentissage, s'ils implémentent également l'induction, le font sur base de la logique algorithmique, par complexification d'un ensemble de règles déductives (Prolog par exemple).
Grâce à leur capacité de classification et de généralisation, les réseaux de neurones sont généralement utilisés dans des problèmes de nature statistique, tels que la classification automatique de codes postaux ou la prise de décision concernant un achat boursier en fonction de l'évolution des cours. Autre exemple, une banque peut créer un jeu de données sur les clients qui ont effectué un emprunt constitué : de leur revenu, de leur âge, du nombre d’enfants à charge… et s’il s’agit d’un bon client. Si ce jeu de données est suffisamment grand, il peut être utilisé pour l’entraînement d’un réseau de neurones. La banque pourra alors présenter les caractéristiques d’un potentiel nouveau client, et le réseau répondra s’il sera bon client ou non, en généralisant à partir des cas qu’il connaît.
Si le réseau de neurones fonctionne avec des nombres réels, la réponse traduit une probabilité de certitude. Par exemple : 1 pour « sûr qu’il sera un bon client », -1 pour « sûr qu’il sera mauvais client », 0 pour « aucune idée », 0,9 pour « presque sûr qu’il sera bon client ».
Le réseau de neurones ne fournit pas toujours de règle exploitable par un humain. Le réseau reste souvent une boîte noire qui fournit une réponse quand on lui présente une donnée, mais le réseau ne fournit pas de justification facile à interpréter.
Les réseaux de neurones sont réellement utilisés, par exemple :
- pour la classification d’espèces animales par espèce étant donnée une analyse ADN.
- reconnaissance de motif ; par exemple pour la reconnaissance optique de caractères (OCR), et notamment par les banques pour vérifier le montant des chèques, par La Poste pour trier le courrier en fonction du code postal, etc. ; ou bien encore pour le déplacement automatisé de robots mobiles autonomes.
- approximation d’une fonction inconnue.
- modélisation accélérée d’une fonction connue mais très complexe à calculer avec exactitude ; par exemple certaines fonctions d’inversions utilisées pour décoder les signaux de télédétection émis par les satellites et les transformer en données sur la surface de la mer.
- estimations boursières :
- apprentissage de la valeur d’une entreprise en fonction des indices disponibles : bénéfices, endettements à long et court terme, chiffre d’affaires, carnet de commandes, indications techniques de conjoncture. Ce type d’application ne pose pas en général de problème
- tentatives de prédiction sur la périodicité des cours boursiers. Ce type de prédiction est très contesté pour deux raisons, l’une étant qu'il n'est pas évident que le cours d’une action ait de façon tout à fait convaincante un caractère périodique (le marché anticipe en effet largement les hausses comme les baisses prévisibles, ce qui applique à toute périodicité éventuelle une variation de période tendant à la rendre difficilement fiable), et l’autre que l’avenir prévisible d’une entreprise détermine au moins aussi fortement le cours de son action, si ce n'est plus encore que peut le faire son passé ; les cas de Pan Am, Manufrance ou IBM permettent de s’en convaincre.
- modélisation de l'apprentissage et amélioration des techniques de l'enseignement.
- en météorologie, pour la classification de conditions atmosphériques et la prévision statistique du temps.
- en auscultation des ouvrages hydrauliques, pour la compréhension physique des phénomènes de déplacements, sous-pressions et débits de fuite.
Limites
Les réseaux de neurones artificiels ont besoin de cas réels servant d’exemples pour leur apprentissage (on appelle cela la base d'apprentissage). Ces cas doivent être d’autant plus nombreux que le problème est complexe et que sa topologie est peu structurée. Ainsi on peut optimiser un système neuronal de lecture de caractères en utilisant le découpage manuel d’un grand nombre de mots écrits à la main par de nombreuses personnes. Chaque caractère peut alors être présenté sous la forme d’une image brute, disposant d’une topologie spatiale à deux dimensions, ou d’une suite de segments presque tous liés. La topologie retenue, la complexité du phénomène modélisé, et le nombre d’exemples doivent être en rapport. Sur un plan pratique, cela n’est pas toujours facile car les exemples peuvent être soit en quantité absolument limitée ou trop onéreux à collecter en nombre suffisant.
Il y a des problèmes qui se traitent bien avec les réseaux de neurones, en particulier ceux de classification en domaines convexes (c’est-à-dire tels que si des points A et B font partie du domaine, alors tout le segment AB en fait partie aussi). Des problèmes comme « Le nombre d’entrées à 1 (ou à zéro) est-il pair ou impair ? » se résolvent en revanche mal : pour affirmer de telles choses sur 2 puissance N points, si on se contente d’une approche naïve mais homogène, il faut précisément N-1 couches de neurones intermédiaires, ce qui nuit à la généralité du procédé.
Un exemple caricatural, mais significatif est le suivant : disposant en entrée du seul poids d'une personne, le réseau doit déterminer si cette personne est une femme ou bien un homme. Les femmes étant statistiquement un peu plus légères que les hommes, le réseau fera toujours un peu mieux qu'un simple tirage au hasard : cet exemple dépouillé indique la simplicité et les limitations de ces modèles mais il montre également comment l'étendre : l'information « port d'une jupe », si on l'ajoute, aurait clairement un coefficient synaptique plus grand que la simple information de poids.
Opacité
Les réseaux complexes de neurones artificiels ne peuvent généralement pas expliquer eux-mêmes leur façon de « penser ». Les calculs aboutissant à un résultat ne sont pas visibles pour les programmeurs qui ont créé le réseau neuronal[13]. Une « neuroscience de l'intelligence artificielle » a donc été créée pour étudier la boîte noire que constituent les réseaux de neurones, science qui pourrait permettre d’augmenter la confiance dans les résultats produits par ces réseaux ou les intelligences artificielles qui les utilisent[13].
Modèle
Structure du réseau

Un réseau de neurones est en général composé d'une succession de couches dont chacune prend ses entrées sur les sorties de la précédente. Chaque couche (i) est composée de Ni neurones, prenant leurs entrées sur les Ni-1 neurones de la couche précédente. À chaque synapse est associé un poids synaptique, de sorte que les Ni-1 sont multipliés par ce poids, puis additionnés par les neurones de niveau i, ce qui est équivalent à multiplier le vecteur d'entrée par une matrice de transformation. Mettre l'une derrière l'autre les différentes couches d'un réseau de neurones reviendrait à mettre en cascade plusieurs matrices de transformation et pourrait se ramener à une seule matrice, produit des autres, s'il n'y avait à chaque couche, la fonction de sortie qui introduit une non linéarité à chaque étape. Ceci montre l'importance du choix judicieux d'une bonne fonction de sortie : un réseau de neurones dont les sorties seraient linéaires n'aurait aucun intérêt.
Au-delà de cette structure simple, le réseau de neurones peut également contenir des boucles qui en changent radicalement les possibilités mais aussi la complexité. De la même façon que des boucles peuvent transformer une logique combinatoire en logique séquentielle, les boucles dans un réseau de neurones transforment un simple dispositif de reconnaissance d'entrées en une machine complexe capable de toutes sortes de comportements.
Fonction de combinaison
Considérons un neurone quelconque.
Il reçoit des neurones en amont un certain nombre de valeurs via ses connexions synaptiques, et il produit une certaine valeur en utilisant une fonction de combinaison. Cette fonction peut donc être formalisée comme étant une fonction vecteur-à-scalaire, notamment :
- Les réseaux de type MLP (multi-layer perceptron) calculent une combinaison linéaire des entrées, c’est-à-dire que la fonction de combinaison renvoie le produit scalaire entre le vecteur des entrées et le vecteur des poids synaptiques.
- Les réseaux de type RBF (radial basis function) calculent la distance entre les entrées, c’est-à-dire que la fonction de combinaison renvoie la norme euclidienne du vecteur issu de la différence vectorielle entre les vecteurs d’entrées.
Fonction d’activation
La fonction d’activation (ou fonction de seuillage, ou encore fonction de transfert) sert à introduire une non-linéarité dans le fonctionnement du neurone.
Les fonctions de seuillage présentent généralement trois intervalles :
- en dessous du seuil, le neurone est non-actif (souvent dans ce cas, sa sortie vaut 0 ou -1) ;
- aux alentours du seuil, une phase de transition ;
- au-dessus du seuil, le neurone est actif (souvent dans ce cas, sa sortie vaut 1).
Des exemples classiques de fonctions d’activation sont :
- La fonction sigmoïde.
- La fonction tangente hyperbolique.
- La fonction de Heaviside.
La logique bayésienne, dont le théorème de Cox-Jaynes formalise les questions d’apprentissage, fait intervenir aussi une fonction en S qui revient de façon récurrente :

Propagation de l’information
Ce calcul effectué, le neurone propage son nouvel état interne sur son axone. Dans un modèle simple, la fonction neuronale est simplement une fonction de seuillage : elle vaut 1 si la somme pondérée dépasse un certain seuil ; 0 sinon. Dans un modèle plus riche, le neurone fonctionne avec des nombres réels (souvent compris dans l’intervalle [0,1] ou [-1,1]). On dit que le réseau de neurones passe d'un état à un autre lorsque tous ses neurones recalculent en parallèle leur état interne, en fonction de leurs entrées.
Apprentissage
Base théorique
%252C_calculated_by_Artificial_Intelligence_(AI)_technology.jpg.webp)
La notion d’apprentissage, bien que connue déjà depuis Sumer, n’est pas modélisable dans le cadre de la logique déductive : celle-ci en effet procède à partir de connaissances déjà établies dont on tire des connaissances dérivées. Or il s’agit ici de la démarche inverse : par observations limitées, tirer des généralisations plausibles : c'est un procédé par induction.
La notion d’apprentissage recouvre deux réalités souvent traitées de façon successive :
- mémorisation : le fait d’assimiler sous une forme dense des exemples éventuellement nombreux,
- généralisation : le fait d’être capable, grâce aux exemples appris, de traiter des exemples distincts, encore non rencontrés, mais similaires.
Dans le cas des systèmes d’apprentissage statistique, utilisés pour optimiser les modèles statistiques classiques, réseaux de neurones et automates markoviens, c’est la généralisation qui est l’objet de toute l’attention.
Cette notion de généralisation est traitée de façon plus ou moins complète par plusieurs approches théoriques.
- La généralisation est traitée de façon globale et générique par la théorie de la régularisation statistique introduite par Vladimir Vapnik. Cette théorie, développée à l’origine en Union soviétique, s’est diffusée en Occident depuis la chute du mur de Berlin. La théorie de la régularisation statistique s’est diffusée très largement parmi ceux qui étudient les réseaux de neurones en raison de la forme générique des courbes d’erreurs résiduelles d’apprentissage et de généralisation issues des procédures d’apprentissage itératives telles que les descentes de gradient utilisées pour l’optimisation des perceptrons multi-couches. Ces formes génériques correspondent aux formes prévues par la théorie de la régularisation statistique ; cela vient du fait que les procédures d’apprentissage par descente de gradient, partant d’une configuration initiale des poids synaptiques explorent progressivement l’espace des poids synaptiques possibles ; on retrouve alors la problématique de l’augmentation progressive de la capacité d’apprentissage, concept fondamental au cœur de la théorie de la régularisation statistique.
- La généralisation est aussi au cœur de l’approche de l'inférence bayésienne, enseignée depuis plus longtemps. Le théorème de Cox-Jaynes fournit ainsi une base importante à un tel apprentissage, en nous apprenant que toute méthode d’apprentissage est soit isomorphe aux probabilités munies de la relation de Bayes, soit incohérente. C’est là un résultat extrêmement fort, et c’est pourquoi les méthodes bayésiennes sont largement utilisées dans le domaine.
Classe de problèmes solubles
En fonction de la structure du réseau, différents types de fonction sont approchables grâce aux réseaux de neurones :
Fonctions représentables par un perceptron
Un perceptron (un réseau à une unité) peut représenter les fonctions booléennes suivantes : and, or, nand, nor mais pas le xor. Comme toute fonction booléenne est représentable à l'aide de ces fonctions, un réseau de perceptrons est capable de représenter toutes les fonctions booléennes. En effet les fonctions nand et nor sont dites universelles : on peut par combinaison de l'une de ces fonctions représenter toutes les autres.
Fonctions représentables par des réseaux de neurones multicouches acycliques
- Fonctions booléennes : toutes les fonctions booléennes sont représentables par un réseau à deux couches. Au pire des cas, le nombre de neurones de la couche cachée augmente de manière exponentielle en fonction du nombre d'entrées.
- Fonctions continues : toutes les fonctions continues bornées sont représentables, avec une précision arbitraire, par un réseau à deux couches (Cybenko, 1989). Ce théorème s'applique au réseau dont les neurones utilisent la sigmoïde dans la couche cachée et des neurones linéaires (sans seuil) dans la couche de sortie. Le nombre de neurones dans la couche cachée dépend de la fonction à approximer.
- Fonctions arbitraires : n'importe quelle fonction peut être approximée avec une précision arbitraire grâce à un réseau à trois couches (théorème de Cybenko, 1988).
Algorithme
La large majorité des réseaux de neurones possède un algorithme « d’entraînement » qui consiste à modifier les poids synaptiques en fonction d’un jeu de données présentées en entrée du réseau. Le but de cet entraînement est de permettre au réseau de neurones d'« apprendre » à partir des exemples. Si l’entraînement est correctement réalisé, le réseau est capable de fournir des réponses en sortie très proches des valeurs d’origine du jeu de données d’entraînement. Mais tout l’intérêt des réseaux de neurones réside dans leur capacité à généraliser à partir du jeu de test. Il est donc possible d'utiliser un réseau de neurones pour réaliser une mémoire ; on parle alors de mémoire neuronale.
La vision topologique d’un apprentissage correspond à la détermination de l’hypersurface sur où est l’ensemble des réels, et le nombre d’entrées du réseau.



Mode supervisé ou non
Un apprentissage est dit supervisé lorsque le réseau est forcé à converger vers un état final précis, en même temps qu'un motif lui est présenté.
À l’inverse, lors d’un apprentissage non-supervisé, le réseau est laissé libre de converger vers n’importe quel état final lorsqu'un motif lui est présenté.
Surapprentissage
Il arrive souvent que les exemples de la base d'apprentissage comportent des valeurs approximatives ou bruitées. Si on oblige le réseau à répondre de façon quasi parfaite relativement à ces exemples, on peut obtenir un réseau qui est biaisé par des valeurs erronées.
Par exemple, imaginons qu'on présente au réseau des couples situés sur une droite d'équation , mais bruités de sorte que les points ne soient pas exactement sur la droite. S'il y a un bon apprentissage, le réseau répond pour toute valeur de présentée. S'il y a surapprentissage, le réseau répond un peu plus que ou un peu moins, car chaque couple positionné en dehors de la droite va influencer la décision : il aura appris le bruit en plus, ce qui n'est pas souhaitable.




Pour éviter le surapprentissage, il existe une méthode simple : il suffit de partager la base d'exemples en 2 sous-ensembles. Le premier sert à l'apprentissage et le second sert à l'évaluation de l'apprentissage. Tant que l'erreur obtenue sur le deuxième ensemble diminue, on peut continuer l'apprentissage, sinon on arrête.
Rétropropagation
La rétropropagation consiste à rétropropager l'erreur commise par un neurone à ses synapses et aux neurones qui y sont reliés. Pour les réseaux de neurones, on utilise habituellement la rétropropagation du gradient de l'erreur, qui consiste à corriger les erreurs selon l'importance des éléments qui ont justement participé à la réalisation de ces erreurs : les poids synaptiques qui contribuent à engendrer une erreur importante se verront modifiés de manière plus significative que les poids qui ont engendré une erreur marginale.
Élagage
L'élagage (pruning, en anglais) est une méthode qui permet d'éviter le surapprentissage tout en limitant la complexité du modèle. Elle consiste à supprimer des connexions (ou synapses), des entrées ou des neurones du réseau une fois l'apprentissage terminé. En pratique, les éléments qui ont la plus petite influence sur l'erreur de sortie du réseau sont supprimés. Deux exemples d'algorithmes d'élagage sont :
- Optimal brain damage (OBD) de Yann LeCun et al.
- Optimal brain surgeon (OBS) de B. Hassibi et D. G. Stork
Différents types de réseaux de neurones
L’ensemble des poids des liaisons synaptiques détermine le fonctionnement du réseau de neurones. Les motifs sont présentés à un sous-ensemble du réseau de neurones : la couche d’entrée. Lorsqu’un motif est appliqué à un réseau, celui-ci cherche à atteindre un état stable. Lorsqu’il est atteint, les valeurs d’activation des neurones de sortie constituent le résultat. Les neurones qui ne font ni partie de la couche d’entrée ni de la couche de sortie sont dits neurones cachés.
Les types de réseau de neurones diffèrent par plusieurs paramètres :
- la topologie des connexions entre les neurones ;
- la fonction d’agrégation utilisée (somme pondérée, distance pseudo-euclidienne…) ;
- la fonction de seuillage utilisée (sigmoïde, échelon, fonction linéaire, fonction de Gauss…) ;
- l’algorithme d’apprentissage (rétropropagation du gradient, cascade correlation) ;
- d’autres paramètres, spécifiques à certains types de réseaux de neurones, tels que la méthode de relaxation pour les réseaux de neurones (réseaux de Hopfield par exemple) qui ne sont pas à propagation simple (perceptron multicouche par exemple).
De nombreux autres paramètres sont susceptibles d’être mis en œuvre dans le cadre de l’apprentissage de ces réseaux de neurones par exemple :
- la méthode de dégradation des pondérations (weight decay), permettant d’éviter les effets de bord et de neutraliser le surapprentissage.
ADALINE (adaptive linear neuron)
Le réseau ADALINE est proche du modèle perceptron, seule sa fonction d'activation est différente puisqu'il utilise une fonction linéaire. Afin de réduire les parasites reçus en entrée, les réseaux ADALINE utilisent la méthode des moindres carrés.
Le réseau réalise une somme pondérée de ses valeurs d'entrées et y rajoute une valeur de seuil prédéfinie. La fonction de transfert linéaire est ensuite utilisée pour l'activation du neurone. Lors de l'apprentissage, les coefficients synaptiques des différentes entrées sont modifiées en utilisant la loi de Widrow-Hoff (en). Ces réseaux sont souvent employés en traitement de signaux[14], notamment pour la réduction de bruit.
Machine de Cauchy
Une machine de Cauchy est un réseau de neurones artificiels assez proche dans le fonctionnement d'une machine de Boltzmann. Cependant les lois de probabilités utilisées ne sont pas les mêmes[15].
Non détaillés
- Adaptive heuristic critic (AHC)
- Time delay neural network (TDNN)
- Associative reward penalty (ARP)
- Avalanche matched filter (AMF)
- Backpercolation (Perc)
- Artmap
- Adaptive logic network (ALN)
- Cascade correlation (CasCor)
- Extended Kalman filter (EKF)
- Learning vector quantization (LVQ)
- Probabilistic neural network (PNN)
- General regression neural network (GRNN)
Avec rétropropagation
Non détaillés
- Brain-State-in-a-Box (BSB)
- Fuzzy cognitive map (FCM)
- Mean field annealing (MFT)
- Recurrent cascade correlation (RCC)
- Backpropagation through time (BPTT)
- Real-time recurrent learning (RTRL)
- Recurrent extended Kalman filter (EKF)
Avec rétropropagation
Non détaillés
- Additive Grossberg (AG)
- Shunting Grossberg (SG)
- Binary adaptive resonance theory (ART1)
- Analog adaptive resonance theory (ART2, ART2a)
- Discrete Hopfield (DH)
- Continuous Hopfield (CH)
- Chaos fractal[16],[17],[18]
- Discrete bidirectional associative memory (BAM)
- Temporal associative memory (TAM)
- Adaptive bidirectional associative memory (ABAM)
- Apprentissage compétitif
Dans ce type d'apprentissage non supervisé, les neurones sont en compétition pour être actifs. Ils sont à sortie binaire et on dit qu'ils sont actifs lorsque leur sortie vaut 1. Alors que dans les autres règles plusieurs sorties de neurones peuvent être actives simultanément, dans le cas de l'apprentissage compétitif, un seul neurone est actif à un instant donné. Chaque neurone de sortie est spécialisé pour « détecter » une suite de formes similaires et devient alors un détecteur de caractéristiques. La fonction d’entrée est dans ce cas, où , et sont respectivement les vecteurs seuil, poids synaptiques et entrées. Le neurone gagnant est celui pour lequel h est maximum donc si les seuils sont identiques, celui dont les poids sont les plus proches des entrées. Le neurone dont la sortie est maximale sera le vainqueur et sa sortie sera mise à 1 alors que les perdants auront leur sortie mise à 0. Un neurone apprend en déplaçant ses poids vers les valeurs des entrées qui l'activent pour augmenter ses chances de gagner. Si un neurone ne répond pas à une entrée, aucun ajustement de poids n'intervient. Si un neurone gagne, une portion des poids de toutes les entrées est redistribuée vers les poids des entrées actives. L'application de la règle donne les résultats suivants (Grossberg) :




- si le neurone i gagne,
- si le neurone i perd.


Cette règle a pour effet de rapprocher le vecteur poids synaptique de la forme d'entrée .


Exemple : considérons deux nuages de points du plan que l’on désire séparer en deux classes. et sont les deux entrées, et sont les poids du neurone 1 que l’on peut considérer comme les coordonnées d’un point ‘poids du neurone 1’ et et sont les poids du neurone 2. Si les seuils sont nuls, hi sera la distance entre les points à classer et les points poids. La règle précédente tend à diminuer cette distance avec le point échantillon lorsque le neurone gagne. Elle doit donc permettre à chaque point poids de se positionner au milieu d’un nuage. Si on fixe initialement les poids de manière aléatoire, il se peut que l’un des neurones se positionne près des deux nuages et que l’autre se positionne loin de sorte qu’il ne gagne jamais. Ses poids ne pourront jamais évoluer alors que ceux de l’autre neurone vont le positionner au milieu des deux nuages. Le problème de ces neurones que l’on qualifie de morts peut être résolu en jouant sur les seuils. En effet, il suffit d’augmenter le seuil de ces neurones pour qu’ils commencent à gagner.






Applications : ce type de réseau et la méthode d'apprentissage correspondant peuvent être utilisés en analyse de données afin de mettre en évidence des similitudes entre certaines données.
Précisions
S’agissant d’un modèle, les réseaux de neurones sont généralement utilisés dans le cadre de simulation logicielle. IMSL et Matlab disposent ainsi de bibliothèques dédiées aux réseaux de neurones. Cependant, il existe quelques implémentations matérielles des modèles les plus simples, comme la puce ZISC.
Voir aussi
- Algorithme émergent
- Apprentissage automatique
- Apprentissage non supervisé
- Apprentissage supervisé
- Arbre de décision
- Carte auto adaptative
- Connexionnisme
- Gaz neuronal
- Intelligence artificielle
- Machine à état liquide
- Neurone formel
- Réseau bayésien
- Réseau de neurones de Hopfield
- Réseau de neurones récurrents
- Réseau neuronal convolutif
- Sciences cognitives
- Statistique
- Statistique multivariée
- Théorème d'approximation universelle
- Réseau de neurones à impulsions
Références
- (en) Warren Sturgis McCulloch and Walter Pitts. A logical calculus of the ideas immanent in nervous activity. Bulletin of Mathematical Biophysics, 5:115-133, 1943.
- (en) Frank Rosenblatt. The Perceptron : probabilistic model for information storage and organization in the brain. Psychological Review, 65:386-408, 1958.
- (en) John Joseph Hopfield. Neural networks and physical systems with emergent collective computational abilities. Proceedings of the National Academy of Sciences, 79:2554-2558, 1982.
- Yann LeCun. Une procédure d’apprentissage pour réseau à seuil asymétrique. COGNITIVA 85, Paris, 4-.
- (en) D. E. Rumelhart and J. L. Mc Clelland. Parallel Distributed Processing: Exploration in the MicroStructure of Cognition. MIT Press, Cambridge, 1986.
- (en) J. A. Anderson and E. Rosenfeld. Neuro Computing Foundations of Research. MIT Press, Cambridge, 1988.
- (en) Tom M. Mitchell, Machine Learning, [détail des éditions]
- Wulfram Gerstner, « Réseau de neurones artificiels - Une introduction à l'apprentissage automatique », sur moodlearchive.epfl.ch, (consulté le ).
Notes et références
- « réseau de neurones artificiels », Le Grand Dictionnaire terminologique, Office québécois de la langue française (consulté le ).
- [PDF] Commission d'enrichissement de la langue française, « Vocabulaire de l’intelligence artificielle (liste de termes, expressions et définitions adoptés) », Journal officiel de la République française no 0285 du [lire en ligne].
- (Gerstner 2004, p. 3)
- Ces paradigmes correspondent aux différents types d'apprentissage par réseau neuronal, notamment les apprentissages supervisés ou non et l'apprentissage par renforcement.
- École normale supérieure, « FUTURS DE L'INTELLIGENCE ARTIFICIELLE (Yann LeCun - Jean Ponce - Alexandre Cadain) », (consulté le )
- Lettvin, J.Y., Maturana, H.R., McCulloch, W.S., & Pitts, W.H. ; What the Frog's Eye Tells the Frog's Brain, (PDF, 14 pages) (1959) ; Proceedings of the IRE, Vol. 47, No. 11, pp. 1940-51.
- (en) Donald O. Hebb, The Organization of Behavior : A Neuropsychological Theory, Wiley, coll. « Wiley book in clinical psychology »,
- Marvin Lee Minsky et Seymour Papert, Perceptrons : An Introduction to Computational Geometry, Cambridge, , 292 p. (ISBN 978-0-262-63111-2)
- Bishop (2006), p. 193
- Hopfield, J. J. Proc. natn. Acad. Sci. U.S.A. 79, 2554–2558 (1982).
- Yassine Mahdi et Kamel Daoud, « Microdroplet Size Prediction in Microfluidic Systems via Artificial Neural Network Modelling for Water-In-oil Emulsion Formulation », Journal of Dispersion Science and Technology, vol. 0, no ja, , null (ISSN 0193-2691, DOI 10.1080/01932691.2016.1257391, lire en ligne, consulté le )
- (en-GB) « LeNet-5 - A Classic CNN Architecture », sur engMRK, (consulté le )
- Appenzeller Tim (2017), The AI revolution in science, Science Niews, 7 juillet
- Mohan Mokhtari, Michel Marie 'Applications de MATLAB 5 et SIMULINK 2 : Contrôle de procédés, Logique floue, Réseaux de neurones, Traitement du signal, Springer-Verlag, Paris, 1998 (ISBN 978-2-287-59651-3)
- https://bib.irb.hr/datoteka/244548.Paper_830.pdf
- Teuvo Kohonen, Content-addressable Memories, Springer-Verlag, 1987, (ISBN 978-0-387-17625-3), 388 pages
- Pribram, Karl (1991). Brain and perception: holonomy and structure in figural processing. Hillsdale, N. J.: Lawrence Erlbaum Associates. (ISBN 978-0-89859-995-4). quote of « fractal chaos » neural network
- D. Levine et al, oscillations in neural systems, publié par Lawrence Erlbaum Associates, 1999, 456 pages, (ISBN 978-0-8058-2066-9)
Bibliographie
- François Blayo et Michel Verleysen, Les réseaux de neurones artificiels, PUF, Que Sais-je No 3042, 1re éd., 1996
- Léon Personnaz et Isabelle Rivals, Réseaux de neurones formels pour la modélisation, la commande et la classification, CNRS Éditions, 2003.
- Richard P. Lippman, « An Introduction to Computing with Neural Nets », IEEE ASSP Magazine, , p. 4-22
- Neural Networks : biological computers or electronic brains - Les entretiens de Lyon – (sous la direction de École normale supérieure de Lyon), Springer-Verlag, 1990
- Jean-Paul Haton, Modèles connexionnistes pour l’intelligence artificielle, 1989.
- Gérard Dreyfus, Jean-Marc Martinez, Manuel Samuelides, Mirta Gordon, Fouad Badran et Sylvie Thiria, Apprentissage statistique : réseaux de neurones, cartes topologiques, machines à vecteurs supports, Eyrolles, 2008
- Eric Davalo, Patrick Naïm, Des Réseaux de neurones, Eyrolles, 1990
- Simon Haykin, Neural Networks : A Comprehensive Foundation, 2e éd., Prentice Hall, 1998
- Christopher M. Bishop, Neural Networks for Pattern Recognition, Oxford University Press, 1995
- (en) Christopher M. Bishop, Pattern Recognition And Machine Learning, Springer, (ISBN 0-387-31073-8) [détail des éditions]
- (en) Richard O. Duda, Peter E. Hart, David G. Stork, Pattern Classification, Wiley-interscience, (ISBN 0-471-05669-3) [détail des éditions]
- Ben Krose et Patrick van der Smagt, An Introduction to Neural Networks, 8e éd., 1996
- Claude Touzet, Les réseaux de neurones : Introduction connexionnisme, EC2, , 160 p., téléchargement PDF
- Marc Parizeau, Réseaux de neurones (Le perceptron multicouche et son algorithme de retropropagation des erreurs), Université Laval, Laval, 2004, 272 p.
- Fabien Tschirhart (dir. Alain Lioret), Réseaux de neurones formels appliqués à l'Intelligence Artificielle et au jeu, ESGI (mémoire de master de recherche en multimédia et animation numérique), Paris, 2009, 121 p. [mémoire en ligne (page consultée le 8 novembre 2010)]
 Portail des probabilités et de la statistique
Portail des probabilités et de la statistique  Portail de l'informatique théorique
Portail de l'informatique théorique  Portail des données
Portail des données