Réseau de neurones récurrents
Un réseau de neurones récurrents est un réseau de neurones artificiels présentant des connexions récurrentes. Un réseau de neurones récurrents est constitué d'unités (neurones) interconnectées interagissant non-linéairement et pour lequel il existe au moins un cycle dans la structure. Les unités sont reliées par des arcs (synapses) qui possèdent un poids. La sortie d'un neurone est une combinaison non linéaire de ses entrées.

Les réseaux de neurones récurrents sont adaptés pour des données d'entrée de taille variable. Ils conviennent en particulier pour l'analyse de séries temporelles. Ils sont utilisés en reconnaissance automatique de la parole ou de l'écriture manuscrite - plus en général en reconnaissance de formes - ou encore en traduction automatique. « Dépliés », ils sont comparables à des réseaux de neurones classiques avec des contraintes d'égalité entre les poids du réseau (voir schéma à droite). Les techniques d'entraînement du réseau sont les mêmes que pour les réseaux classiques (rétropropagation du gradient), néanmoins les réseaux de neurones récurrents se heurtent au problème de disparition du gradient pour apprendre à mémoriser des évènements passés. Des architectures particulières répondent à ce dernier problème, on peut citer en particulier les réseaux Long short-term memory. On peut étudier les comportements des réseaux de neurones récurrents avec la théorie des bifurcations, mais la complexité de cette étude augmente très rapidement avec le nombre de neurones.
Réseaux Elman et réseaux Jordan

Un réseau Elman est un réseau de 3 couches (x, y, et z dans l'illustration) complété d'un ensemble de "unités de contexte" (u dans l'illustration). La couche du milieu (cachée) est connectée à ces unités de contexte, et a des poids.[1] A chaque étape, l'entrée est retransmise et une règle d'apprentissage est appliquée. Les connexions finales fixées enregistrent une copie des valeurs précédentes des unités cachées dans les unités de contexte (puisqu'elles propagent les connexions avant que la règle d'apprentissage soit appliquée). Donc le réseau peut maintenir une sorte d'état, lui permettant d'exécuter des tâches telles que la prédiction séquentielle qui est au-delà de la puissance d'un perceptron multicouche standard.
Les réseaux Jordan sont similaires aux réseaux Elman. Les unités de contexte sont alimentées par la couche de sortie à la place de la couche cachée. Les unités de contexte dans un réseau Jordan mentionnent aussi la couche d'état. Elles ont une connexion récurrente à elles-mêmes[1].
Les réseaux Elman et Jordan sont aussi connus comme de "simples réseaux récurrents".


Variables et fonctions
- : vecteur d'entrée
- : vecteur de la couche cachée
- : vecteur de sortie
- , et : matrices et vecteur (paramètres)
- et : fonction d'activation








Problème de disparition du gradient
Les réseaux de neurones récurrents classiques sont exposés au problème de disparition de gradient qui les empêche de modifier leurs poids en fonction d'évènements passés[4]. Lors de l'entraînement, le réseau essaie de minimiser une fonction d'erreur dépendant en particulier de la sortie . Pour l'exemple donné ci-dessus, suivant la règle de dérivation en chaîne, la contribution au gradient de l'entrée est





où représente la matrice tel que le seul terme non nul est le terme égal à 1. Pour des valeurs standard de la fonction d'activation et des poids du réseau le produit décroît exponentiellement en fonction de . Par conséquent la correction de l'erreur si cela doit faire intervenir un évènement lointain diminuera exponentiellement avec l'intervalle de temps entre cet évènement et le présent. Le réseau sera incapable de prendre en compte les entrées passées.




Architectures
Long short-term memory
Un réseau Long short-term memory (LSTM), en français réseau récurrent à mémoire court et long terme ou plus explicitement réseau de neurones récurrents à mémoire court-terme et long terme, est l'architecture de réseau de neurones récurrents la plus utilisée en pratique qui permet de répondre au problème de disparition de gradient. Le réseau LSTM a été proposé par Sepp Hochreiter et Jürgen Schmidhuber en 1997[5]. L'idée associée au LSTM est que chaque unité computationnelle est liée non seulement à un état caché mais également à un état de la cellule qui joue le rôle de mémoire. Le passage de à se fait par transfert à gain constant et égal à 1. De cette façon les erreurs se propagent aux pas antérieurs (jusqu'à 1 000 étapes dans le passé) sans phénomène de disparition de gradient. L'état de la cellule peut être modifié à travers une porte qui autorise ou bloque la mise à jour (input gate). De même une porte contrôle si l'état de cellule est communiqué en sortie de l'unité LSTM (output gate). La version la plus répandue des LSTM utilise aussi une porte permettant la remise à zéro de l'état de la cellule (forget gate)[6].




Équations
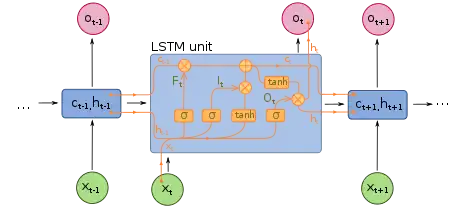

Valeurs initiales : et . L'opérateur symbolise le produit matriciel de Hadamard (produit terme à terme). Les symboles et représentent respectivement la fonction sigmoïde et la fonction tangente hyperbolique, bien que d'autres fonctions d'activation soient possibles.






Gated Recurrent Unit
Un réseau Gated Recurrent Unit (GRU), en français réseau récurrent à portes ou plus explicitement réseau de neurones récurrents à portes, est une variante des LSTM introduite en 2014. Les réseaux GRU ont des performances comparables aux LSTM pour la prédiction de séries temporelles (ex : partitions musicales, données de parole[7]). Une unité requiert moins de paramètres à apprendre qu'une unité LSTM. Un neurone n'est associé plus qu'à un état caché (plus de cell state) et les portes d'entrée et d'oubli de l'état caché sont fusionnées (update gate). La porte de sortie est remplacée par une porte de réinitialisation (reset gate).
Équations
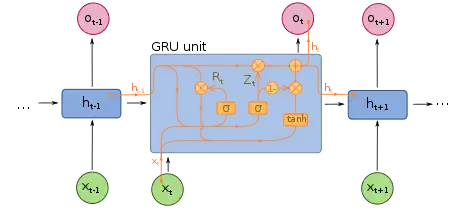
Valeur initiale : .

Notes et références
- Cruse, Holk; Neural Networks as Cybernetic Systems, 2nd and revised edition
- Jeffrey L. Elman, « Finding Structure in Time », Cognitive Science, vol. 14, no 2, , p. 179–211 (DOI 10.1016/0364-0213(90)90002-E)
- Michael I. Jordan, « Serial Order: A Parallel Distributed Processing Approach », Advances in Psychology, vol. 121, , p. 471–495 (ISBN 9780444819314, DOI 10.1016/s0166-4115(97)80111-2)
- (en) Hochreiter, Sepp, Bengio, Yoshua, Frasconi, Paolo et Schmidhuber, Jürgen, « Gradient Flow in Recurrent Nets: The Difficulty of Learning Long-Term Dependencies », A Field Guide to Dynamical Recurrent Networks, IEEE,
- (en) Hochreiter, Sepp et Schmidhuber, Jürgen, « Long Short-Term Memory », Neural Computation, vol. 9, no 8, , p. 1735-1780
- (en) Gers, Felix, Schraudolph, Nicol et Schmidhuber, Jürgen, « Learning Precise Timing with LSTM Recurrent Networks », Journal of Machine Learning Research, vol. 3, , p. 115-143
- (en) Chung, Junyoung, Gulcehre, Caglar, Cho, KyungHyun et Bengio, Yoshua, « Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling », arXiv preprint arXiv:1412.3555,
Annexes
Liens externes
Bibliographie
- (en) Ian J. Goodfellow, Yoshua Bengio et Aaron Courville, Deep Learning, MIT Press, (ISBN 0262035618, lire en ligne) [détail des éditions]
 Portail de l'informatique théorique
Portail de l'informatique théorique