Apprentissage non supervisé
Dans le domaine informatique et de l'intelligence artificielle, l'apprentissage non supervisé désigne la situation d'apprentissage automatique où les données ne sont pas étiquetées. Il s'agit donc de découvrir les structures sous-jacentes à ces données non étiquetées. Puisque les données ne sont pas étiquetées, il est impossible à l'algorithme de calculer de façon certaine un score de réussite.
L'absence d'étiquetage ou d'annotation caractérise les tâches d'apprentissage non supervisé et les distingue donc des tâches d'apprentissage supervisé.
L'introduction dans un système d'une approche d'apprentissage non supervisé est un moyen d'expérimenter l'intelligence artificielle. En général, des systèmes d'apprentissage non supervisé permettent d'exécuter des tâches plus complexes que les systèmes d'apprentissage supervisé, mais ils peuvent aussi être plus imprévisibles. Même si un système d'IA d'apprentissage non supervisé parvient tout seul, par exemple, à faire le tri entre des chats et des chiens, il peut aussi ajouter des catégories inattendues et non désirées, et classer des races inhabituelles, introduisant plus de bruit que d'ordre[1].
Apprentissage non supervisé vs. supervisé
L'apprentissage non supervisé consiste à apprendre sans superviseur. Il s’agit d’extraire des classes ou groupes d’individus présentant des caractéristiques communes[2]. La qualité d'une méthode de classification est mesurée par sa capacité à découvrir certains ou tous les motifs cachés.
On distingue l'apprentissage supervisé et non supervisé. Dans le premier apprentissage, il s’agit d’apprendre à classer un nouvel individu parmi un ensemble de classes prédéfinies: on connaît les classes a priori. Tandis que dans l'apprentissage non supervisé, le nombre et la définition des classes ne sont pas donnés a priori[3].
Exemple
Différence entre les deux types d'apprentissage.
Apprentissage supervisé
- On dispose d'éléments déjà classés
Exemple : articles en rubrique cuisine, sport, culture...
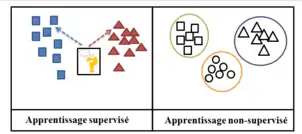
- On veut classer un nouvel élément
Exemple: lui attribuer un nom parmi cuisine, sport, culture...
Apprentissage non supervisé
- On dispose d'éléments non classés
Exemple : une fleur
- On veut les regrouper en classes
Exemple: si deux fleurs ont la même forme, elles sont en rapport avec une même plante correspondante.
Il existe deux principales méthodes d'apprentissage non supervisées[4] :
- Les méthodes par partitionnement telles que les algorithmes des k-moyennes ou k-médoïdes.
- Les méthodes de regroupement hiérarchique.
Utilisations
Les techniques d'apprentissage non supervisé peuvent être utilisées pour résoudre, entre autres, les problèmes suivants :
- le partitionnement de données (par exemple avec l'algorithme des k-moyennes, le regroupement hiérarchique),
- l'estimation de densité de distribution (distribution de mélange, estimation par noyau),
- la réduction de dimension (analyse en composantes principales, carte auto-adaptative)
L'apprentissage non supervisé peut aussi être utilisé en conjonction avec une inférence bayésienne pour produire des probabilités conditionnelles pour chaque variable aléatoire étant données les autres.
Liste des algorithmes d'apprentissage non supervisé
- K-means clustering (K-moyenne)
- Dimensionality Reduction (Réduction de la dimensionnalité)
- Principal Component Analysis (Analyse des composants principaux)
- Singular Value Decomposition (Décomposition en valeur singulière)
- Independent Component Analysis (Analyse en composantes indépendantes)
- Distribution models (Modèles de distribution)
- Hierarchical clustering (Classification hiérarchique)[5]
Regroupement ou Clustering
Le regroupement ou Clustering est la technique la plus utilisée pour résoudre les problèmes d'apprentissage non supervisé. La mise en cluster consiste à séparer ou à diviser un ensemble de données en un certain nombre de groupes, de sorte que les ensembles de données appartenant aux mêmes groupes se ressemblent davantage que ceux d’autres groupes. En termes simples, l’objectif est de séparer les groupes ayant des traits similaires et de les assigner en grappes.
Voyons cela avec un exemple. Supposons que vous soyez le chef d’un magasin de location et que vous souhaitiez comprendre les préférences de vos clients pour développer votre activité. Vous pouvez regrouper tous vos clients en 10 groupes en fonction de leurs habitudes d’achat et utiliser une stratégie distincte pour les clients de chacun de ces 10 groupes. Et c’est ce que nous appelons le Clustering[6].
Méthodes
Le clustering consiste à grouper des points de données en fonction de leurs similitudes, tandis que l’association consiste à découvrir des relations entre les attributs de ces points de données:
Les techniques de clustering cherchent à décomposer un ensemble d'individus en plusieurs sous ensembles les plus homogènes possibles
- On ne connaît pas la classe des exemples (nombre, forme, taille)
- Les méthodes sont très nombreuses, typologies généralement employées pour les distinguer Méthodes de partitionnement / Méthodes hiérarchiques
- Avec recouvrement / sans recouvrement
- Autre : incrémental / non incrémental
- D'éventuelles informations sur les classes ou d'autres informations sur les données n'ont pas d'influence sur la formation des clusters, seulement sur leur interprétation[7].
L'un des algorithmes le plus connu et utilisé en clustering est la K-moyenne.Cet algorithme va mettre dans des “zones” (Cluster), les données qui se ressemblent. Les données se trouvant dans le même cluster sont similaires.
L’approche de K-Means consiste à affecter aléatoirement des centres de clusters (appelés centroids), et ensuite assigner chaque point de nos données au centroid qui lui est le plus proche. Cela s’effectue jusqu’à assigner toutes les données à un cluster[8].
Notes et références
- « Apprentissage non supervisé »
- Guillaume Cleuziou, Une méthode de classification non-supervisée pour l’apprentissage de règles et la recherche d’information, (lire en ligne)
- « Classification »
- Pierre-Louis GONZALEZ, MÉTHODES DE CLASSIFICATION, Cnam,
- « Apprentissage Supervisé Vs. Non Supervisé »
- « Apprentissage Supervisé Vs. Non Supervisé », sur Le DataScientist, (consulté le )
- « Apprentissage non supervisé »
- « L’apprentissage non supervisé – Machine Learning »
Voir aussi
Articles connexes
- Réseau de neurones
- Partitionnement de données
- Algorithme espérance-maximisation
- Carte auto adaptative
- Intelligence artificielle
- Extraction de connaissances
- Méthode des nuées dynamiques
- Regroupement hiérarchique
- Algorithme EM
- Analyse en composantes principales
- Régression logistique
- Algorithme des k-moyennes
Bibliographie
 Portail de l’informatique
Portail de l’informatique  Portail des probabilités et de la statistique
Portail des probabilités et de la statistique  Portail des données
Portail des données