Analyse de similitudes
L'analyse de similitudes est une méthode d'analyse des données s'inscrivant dans une approche issue de la théorie des graphes et qui se base sur la recherche de similitudes ou de dissimilitudes. Cette approche permet de ne pas créer de catégories a priori, et de plutôt construire les catégories à analyser à partir de similitudes formelles entre les entités au sein d'un réseau.

En analyse de réseaux, deux entités (sommets d'un graphe) sont dites similaires ou équivalentes quand les mêmes relations les lient à d'autres entités (ou acteurs) du réseau. Il existe trois approches fondamentales pour mesurer la similarité et la distance entre entités au sein d'un réseau.
Approche par les similarités ou dissimilarités
La recherche en sciences sociales passe généralement par le recours à des catégories sociales ou des « classes sociales » déjà construites et prédéfinies par les chercheurs, sur la base d'attributs partagés : les « jeunes », les « cadres », les « pays », les « chômeurs », les « femmes », etc. Avec l'analyse de similitude, ces catégories ne sont pas fixées a priori mais rendues visibles par un ou des procédés qui permettent de classifier et de regrouper les cas analysés, selon leurs relations effectives — qui fait quoi, qui parle à qui, où, sur quoi, avec qui, etc..
La similarité en analyse de réseaux se produit quand deux sommets (ou plus, selon la structure analysée) se retrouvent dans la même classe d'équivalence. Dit autrement, des entités sociales ou des positions sociales d'une même classe d'équivalence se confondent sur la base des relations qu'ils entretiennent avec les autres, comme par exemple, des médecins qui ont des patients en suivi[1].
Il existe trois approches fondamentales afin de produire une mesure de similarité au sein d'un réseau : l'équivalence structurale, l'équivalence automorphique, et l'équivalence régulière[2]. Ces trois notions d'équivalence sont hiérarchisées : tout ensemble en équivalence structurale est également en équivalence automorphique et en équivalence régulière, tout ensemble en équivalence automorphique est en équivalence régulière, mais toutes les équivalences régulières ne sont pas nécessairement automorphiques ou structurales, et toutes les équivalences automorphiques ne sont nécessairement structurales[3].
Équivalence structurale
Deux sommets d'un réseau sont structurellement équivalents si leurs liens vers les autres sommets sont similaires.
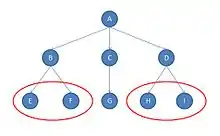
Dans l'image ci-proposée, aucun autre sommet (ou nœud) n'a exactement le même ensemble de liens que A qui appartient donc à une classe spécifique. Il en va de même pour les sommets B, C, D et G (chacun de ces sommets a son « ensemble » spécifique de liens vers d'autres sommets). Cependant, E et F, sont dans la même classe d'équivalence structurale, puisque tous les deux présentent le même schéma de liens (un lien vers B), ils sont dits en équivalence structurale. Il en va de même pour H et I, qui tous les deux présentent un lien vers D[3].
L'équivalence structurale est la plus forte forme de similarité. Dans la réalité, dans les réseaux sociaux l'équivalence pure est rare, et il est utile d'user de critères moins stricts afin de mesurer une équivalence approximative[4].
Un concept proche de celui de l'équivalence structurale est celui de l'équivalence institutionnelle : deux sommets (par exemple, deux entreprises) sont institutionnellement équivalentes si elles opèrent dans le même domaine institutionnel[5]. Alors que les sommets structurellement équivalents ont des schémas relationnels ou des positions de réseau identiques, l’équivalence institutionnelle reflète la similitude des influences institutionnelles que les sommets subissent dans les mêmes domaines et espaces, quelle que soit la similitude de leurs positions dans le réseau. Par exemple, deux banques de Chicago peuvent avoir des schémas de liens très différents (l’une peut être un sommet central et l’autre peut être en position périphérique), de sorte qu’elles ne sont pas des équivalents structuraux, mais parce qu’elles opèrent toutes deux sur le terrain de la finance et dans le même domaine défini géographiquement (Chicago), ils seront soumis aux mêmes influences institutionnelles[5].
Définition formelle par Karl Reitz et Douglas White (1989) : Soit un ensemble et une relation binaire dans . , relation d'équivalence, est une équivalence structurale, si et seulement si, pour tout tel que , implique[1] :






- , et
- , et
- , et




Similarité cosinus
La similarité cosinus de et est le nombre de voisins communs divisé par la moyenne géométrique de leurs degrés. [6] Cette valeur oscille entre 0 et 1. La valeur 1 indique que les deux sommets ont exactement le même voisinage, tandis que la valeur 0 veut dire qu'ils n'ont aucun voisin en commun. La similarité cosinus est techniquement indéfinie si un ou les deux sommets ont un degré 0, mais conformément à la convention il est dit que la similarité de cosinus est de 0, dans ces cas-là[2].


Coefficient de Pearson
Le coefficient de corrélation de Pearson, est une méthode alternative afin de normaliser le décompte des voisins communs. Cette méthode compare le nombre de voisins communs à la valeur attendue dans un réseau où les sommets sont connectés de manière aléatoire. Cette valeur est strictement comprise entre -1 et 1[2].
Distance euclidienne
La distance euclidienne est égale au nombre de voisins qui diffèrent entre deux sommets. Il s'agit davantage d'une mesure de dissimilarité, puisqu'elle est plus grande pour les sommets qui diffèrent le plus. Elle peut être normalisée en divisant par la valeur maximum. « Maximum » signifie qu'il n'y a pas de voisins communs, auquel cas la distance est égale à la somme des degrés des sommets[2].
Équivalence automorphique
Formellement « Deux sommets sont automorphiquement équivalents si tous les sommets peuvent être renommés pour former un graphe isomorphique avec l'étiquette de et interchangés. Deux sommets équivalents automorphiquement partagent exactement les mêmes propriétés indépendantes de l'étiquette. »[7]


Plus intuitivement, des entités sociales sont en équivalence automorphique s'il est possible de permuter le graphe de façon que l'échange de deux entités n'ait aucun effet sur les distances entre les autres entités au sein du graphe.

Dans l'image ci-contre, représentant une structure organisationnelle, A est au poste central, B, C et D répondent de A et agissent sur E, F et H, I ; G est isolé bien que répondant de C (et A). Bien que les acteurs B et D ne soient pas structurellement équivalents — ils ont le même répondant (A), mais pas les mêmes liens vers les autres —, ils semblent tout de même en équivalence. Les deux (B et D) répondent de A et sont en interaction avec deux entités (respectivement E F et H I). Si les sommets B et D étaient interchangés, ou encore, si on interchangeait E et H (ainsi que les autres combinaisons possibles) les distances entre les sommets dans le réseau resteraient exactement identiques. Il y a donc 5 classes d'équivalence automorphique dans ce graphe : , , , , et . Il est à noter qu'une définition moins stricte de cette équivalence réduit le nombre de classes[3].





Définition formelle par Karl Reitz et Douglas White (1989) : Soit un ensemble, et une relation binaire dans . , relation d'équivalence, est une équivalence forte ou automorphique, si et seulement si, pour tout , implique[1] :

- , et
- , et

Équivalence régulière
Formellement, « deux acteurs sont régulièrement équivalents s'ils sont également reliés à leurs équivalents ». En d'autres mots, des sommets régulièrement équivalents sont des sommets qui bien que ne partageant pas le même voisinage, partagent des voisinages qui sont eux-mêmes similaires[7].
Par exemple, deux mères sont équivalentes parce que chacune d'elles à un schéma de connexions relationnelles similaires avec son partenaire de couple, ses enfants, etc. Deux mères ne sont pas nécessairement liées au — ou à la — même partenaire, ni aux mêmes enfants, alors elles ne sont pas structuralement équivalentes. Et puisque que chaque mère peut avoir un nombre variable d'enfants et/ou de partenaires, elles ne sont pas non plus en équivalence automorphique. Mais elles sont similaires parce qu'elles ont le même type de relations avec d'autres ensembles d'entités sociales (elles aussi vues comme régulièrement équivalentes puisque similaires dans leurs types de liens vers l'entité "mère")[3].
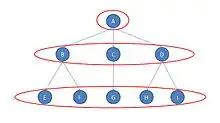
Dans le graphe présenté ci-contre, il y a trois classes d'équivalence régulière : , , [3]


Définition formelle par Karl Reitz et Douglas White (1989) : Soit un ensemble, et une relation binaire dans . , relation d'équivalence, est une équivalence régulière, si et seulement si, pour tout , implique[1] :
- et , et
- et



Visualiser les similarités et distances
Outils de partitionnement de données
Le partitionnement de données, dont le regroupement hiérarchique des sommets sur la base de la similitude de leurs profils de liens vers d'autres sommets fournit un arbre de jonction ou un dendrogramme qui permet de visualiser le degré de similarité entre des cas - et peut être utilisé pour trouver des classes d'équivalence approximatives[3].
Outils de positionnement multidimensionnel
Le recours aux analyses d'équivalences permet d'identifier et visualiser des classes ou regroupements de classes. En utilisant l'analyse des regroupements hiérarchiques, il est implicitement supposé que les similarités ou distances entre les cas reflètent d'une seule dimension sous-jacente. Il est toutefois possible qu'il y ait de nombreux « aspects » ou « dimensions » sous-tendant les similarités observées. Les facteurs ou composantes de l'analyse peuvent être appliquées à des corrélations ou des covariances entre les cas. Alternativement, le positionnement multidimensionnel peut être employé (non métrique pour des données qui sont intrinsèquement nominales ou ordinales ; métriques pour les données valuées)[3].
Le positionnement multidimensionnel représente des schémas de similarité ou de dissimilarité dans le profil de lien entre les sommets (lorsqu'appliqué à l'adjacence ou aux distances) tel une "carte" dans l'espace multidimensionnel. Cette carte permet de voir à quel point les sommets sont près, s'ils s'agglutinent dans l'espace, et à quel point la variation est forte (ou non) entre chaque dimension[3].
Blockmodeling
Le blockmodeling est une technique qui permet de classer les liens d'une matrice d'adjacence de façon à regrouper les liens de même type ; ce qui permet de réorganiser les matrices afin de déceler des similitudes[8] (cf. Matrice par blocs). La définition de 1971 par Lorrain et White est : « les sommets a et b sont structurellement équivalents, s'ils sont reliés à d'autres sommets d'une même façon »[9].

Treillis de Galois
L'usage du treillis de Galois sur des matrices bipartites de données socio-sémantiques permet de regrouper par similitudes, tout en hiérarchisant les relations[10].
Implications théoriques
L'analyse de similitudes permet aux données de caractériser elles-mêmes leurs propres structures (comme par exemple, des cliques, des hiérarchies ou une équivalence), au lieu que chercheur détermine lui-même et a priori des catégories pour l'analyse, comme c'est généralement le cas en sciences sociales[1]. Ainsi, ce n'est pas le chercheur qui détermine les catégories sociales et qui en fait ou non partie, cela s'opère a posteriori des analyses de similitudes ; les cas soumis à l'analyse sont regroupés selon leurs attributs communs, ce qui permet de détecter des régularités (ou même des "irrégularités").
Interactions corrélatives
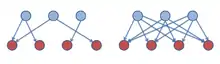
En analyse de réseaux, les classes d'équivalence sont vues comme étant en interactions corrélatives ; "c’est-à-dire celles dans lesquelles les partenaires ne sont pas des individus semblables mis dans une situation particulière, mais des individus qui se définissent par le rôle qu’ils jouent dans l’interaction"[11]. Ensemble, ils produisent un fait social[11].
Les interactions corrélatives sont inégales d'un point de vue structurel, puisque les protagonistes ont des positions complémentaires dans l'interaction et la production du fait social : « Il s'agit d'une interaction qui dans son principe est dissymétrique »[1]. Cette notion permet de parler des rapports et des rôles sociaux[1].
Exemples d'interactions corrélatives :
Comparabilité, collaboration et compétition
La collaboration et la compétition implique la comparabilité.
Usages hors des sciences sociales
Les méthodes d'analyse des similitudes relationnelles ne sont pas employées qu'en sciences sociales, c'est aussi un des procédés utilisés par la NSA[12], en forensique[13], en analyse automatique de large corpus, ou d'images[14], et aussi en biologie[15].[16]
Voir aussi
Bibliographie complémentaire
- Alain Degenne et Pierre Vergès, « Introduction à l'analyse de similitude », Revue française de sociologie, vol. 14, no 4, , p. 471-511 (DOI 10.2307/3320247, lire en ligne).
- Bouriche Boumedine, « L'analyse de similitude », dans Jean-Claude Abric (dir.), Méthodes d'étude des représentations sociales, ERES, , 296 p. (ISBN 9782749201238, présentation en ligne), p. 221-252.
Références
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Similarity (network science) » (voir la liste des auteurs).
- Degenne, Alain., Les réseaux sociaux, Paris, Armand Colin, , 294 p. (ISBN 2-200-26662-6 et 9782200266622, OCLC 57127633, lire en ligne), p. 105. Chapitre 4 : Cohésion et équivalence
- Newman, M.E.J. 2010. Networks: An Introduction. Oxford, UK: Oxford University Press.
- Hanneman, Robert A. and Mark Riddle. 2005. Introduction to social network methods. Riverside, CA: University of California, Riverside ( published in digital form at http://faculty.ucr.edu/~hanneman/ )
- (en) Cross, Robert L. Parker, Andrew, 1966- Sasson, Lisa., Networks in the knowledge economy, Oxford University Press, (ISBN 0-19-515950-0 et 9780195159509, OCLC 933870327, lire en ligne), p. 23 Chap. 1 The social structure of competition, par Ronald Burt
- Christopher Marquis et András Tilcsik, « Institutional Equivalence: How Industry and Community Peers Influence Corporate Philanthropy », Organization Science, vol. 27, no 5, , p. 1325–1341 (ISSN 1047-7039, DOI 10.1287/orsc.2016.1083, lire en ligne)
- Salton G., Automatic Text Processing: The Transformation, Analysis and Retrieval of Information by Computer, Addison-Wesley, Reading, MA (1989)
- Borgatti, Steven, Martin Everett, and Linton Freeman. 1992. UCINET IV Version 1.0 User's Guide. Columbia, SC: Analytic Technologies.
- Harrison C. White, Scott A. Boorman et Ronald L. Breiger, « Social Structure from Multiple Networks. I. Blockmodels of Roles and Positions », American Journal of Sociology, vol. 81, no 4, , p. 730–780 (ISSN 0002-9602 et 1537-5390, DOI 10.1086/226141, lire en ligne, consulté le )
- Snidjders, « Equivalence; concepts for social networks », (consulté le )
- Camille Roth et Paul Bourgine, « Epistemic Communities: Description and Hierarchic Categorization », Mathematical Population Studies, vol. 12, no 2, , p. 107–130 (ISSN 0889-8480 et 1547-724X, DOI 10.1080/08898480590931404, lire en ligne, consulté le )
- Alain Degenne, « Types d’interactions, formes de confiance et relations », (consulté le )
- Robert S. Renfro et Richard F. Deckro, « A Flow Model Social Network Analysis of the Iranian Government », Military Operations Research, vol. 8, no 1, , p. 5–16 (ISSN 1082-5983, DOI 10.5711/morj.8.1.5, lire en ligne, consulté le )
- Kamal Taha et Paul D. Yoo, « A System for Analyzing Criminal Social Networks », Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2015 - ASONAM '15, ACM Press, (ISBN 9781450338547, DOI 10.1145/2808797.2808827, lire en ligne, consulté le )
- A. McCallum, X. Wang et A. Corrada-Emmanuel, « Topic and Role Discovery in Social Networks with Experiments on Enron and Academic Email », Journal of Artificial Intelligence Research, vol. 30, , p. 249–272 (ISSN 1076-9757, DOI 10.1613/jair.2229, lire en ligne, consulté le )
- (en) Sean L. Seyler, Avishek Kumar, M. F. Thorpe et Oliver Beckstein, « Path Similarity Analysis: A Method for Quantifying Macromolecular Pathways », PLOS Computational Biology, vol. 11, no 10, , e1004568 (ISSN 1553-7358, PMID 26488417, PMCID PMC4619321, DOI 10.1371/journal.pcbi.1004568, lire en ligne, consulté le )
- Lise Getoor et Christopher P. Diehl, « Link mining », ACM SIGKDD Explorations Newsletter, vol. 7, no 2, , p. 3–12 (ISSN 1931-0145, DOI 10.1145/1117454.1117456, lire en ligne, consulté le )
 Portail de la sociologie
Portail de la sociologie  Portail des probabilités et de la statistique
Portail des probabilités et de la statistique  Portail des données
Portail des données  Portail de l'informatique théorique
Portail de l'informatique théorique