Web profond
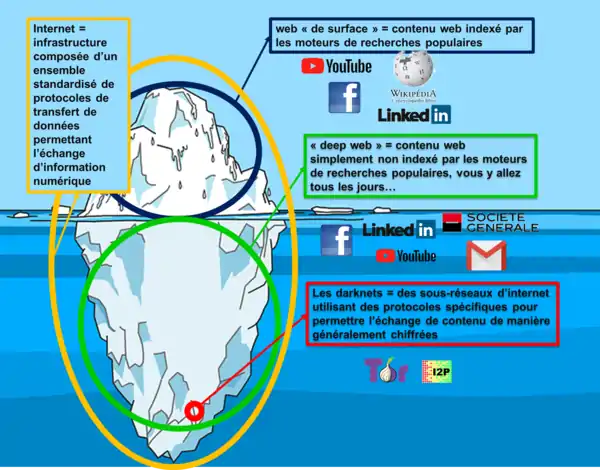
Le web profond[1] (en anglais deep web), appelé aussi toile profonde[2] ou web invisible[1] (terme imprécis)[3] décrit dans l'architecture du web la partie de la toile non indexée par les principaux moteurs de recherche généralistes[4]. Ce terme est parfois aussi utilisé de manière abusive pour désigner les contenus choquants et peu visibles que l'on trouve sur le web.
Ne doit pas être confondu avec dark web, darknet ou web opaque.
Définition du deep web (toile profonde)
En 2001, Michael K. Bergman compose l'expression deep web pour le vocabulaire des moteurs de recherche[5]. Ce terme est construit par opposition au web surfacique ou web référencé. Il représente la partie de la toile qui n'est pas référencée par les moteurs de recherche généralistes (certains moteurs, tels que BASE, prennent en compte cette partie du réseau). Le deep web décrit un fait technique indépendamment du contenu.
Tous les sites web peuvent contenir des pages dans la toile profonde. On y trouve notamment les messagerie web, les banques en ligne, ou des sites à accès restreint, voire partiellement ou intégralement payant (voir Raisons de la non-indexation).
Ne pas confondre
« Il convient de distinguer la toile profonde (deep web) de l'internet clandestin. »[6] (en anglais darknet), un réseau superposé avec des fonctions d'anonymisation. La toile profonde est un contenu indexable mais non indexé de la toile. Elle n'est pas non plus un réseau d'anonymisation (les services web auxquels on peut accéder via des outils tels Tor, Freenet, I2P…).
Confusion dans l'utilisation du mot deep web
L'expression « deep web » est régulièrement utilisée dans les médias pour parler de sites web dont le contenu ou les services seraient choquants ou illégaux[7],[8],[9]. Les médias ne parlent alors plus seulement de sites cachés ou invisibles au sens technique du référencement par les moteurs de recherche mais dans un sens plus social pour évoquer leur faible visibilité.
La confusion est régulière y compris dans la presse généraliste comme en lorsque certains journaux [10],[11] reprennent une information de l'Agence France-Presse et définissent de manière erronée le deep web comme étant « seulement accessible au moyen de réseaux spécifiques».
La confusion avec le dark web est parfois complète comme dans un article publié en sur rtl.be où l'on peut lire que « le deep web se trouve [...] sur un autre réseau, parallèle à internet. Les adresses URL des sites se terminent par .onion [...] »[12] ce qui ne correspond qu'au dark web et plus précisément à Tor.
Ressources profondes
Les robots d'indexation sont des programmes utilisés par les moteurs de recherche pour parcourir le web. Afin de découvrir de nouvelles pages, ces robots suivent les hyperliens. Les ressources profondes sont celles qui ne peuvent pas être atteintes facilement par les moteurs de recherche.
Les ressources du web profond peuvent être classées dans une ou plusieurs des catégories suivantes :
- contenu dynamique ;
- contenu non lié ;
- contenu à accès limité ;
- contenu de script ;
- format non indexable.
(voir la section Raisons de la non-indexation pour plus de précision).
Taille
Une étude de juillet 2001 réalisée par l'entreprise BrightPlanet[3] estimait que le web profond pouvait contenir 500 fois plus de ressources que le web indexé par les moteurs de recherche. Ces ressources, en plus d'être volumineuses, notamment parce que la compression des fichiers y est moins importante, sont souvent de très bonne qualité.
D'après le site spécialisé GinjFo, le deep web représenterait 96 % de l'intégralité du web alors que le web surfacique ne représenterait que 4 % du contenu[13].
En 2008, le web invisible représenterait 70 à 75 % de l'ensemble du trafic internet, soit environ un trilliard de pages web non indexées[14].
Web opaque
Une partie très importante du web est théoriquement indexable, mais non indexée de fait par les moteurs. Certains auteurs[15] parlent dans ce cas, pour le web non profond et non indexé, de « web opaque » (opaque web) ou de « web presque visible » (nearly visible web).
Pour résumer, le web profond et le web opaque sont tous deux accessibles en ligne aux internautes et non indexés par les moteurs, mais le web opaque, lui, pourrait être indexé.
Les algorithmes des moteurs étant semblables (par exemple, PageRank), les zones indexées se recoupent en partie d'un moteur de recherche à l'autre. Les ressources matérielles des robots d'indexation ne sont pas, malgré des moyens matériels importants, à même de suivre tous les liens théoriquement visibles par eux, que le web (gigantesque) contient.
Une équipe de chercheurs allemands a étudié le comportement des robots d'indexation face à des sites contenant énormément de pages. Ils ont créé un site web composé de 2 147 483 647 pages (231 - 1). Ce site web étant un arbre binaire, il est très profond : il faut au minimum 31 clics pour arriver à certaines pages. Ils ont laissé ce site en ligne, sans le modifier, pendant une année. Les résultats montrent que le nombre de pages indexées pour ce site, dans le meilleur des cas, ne dépasse pas 0,0049 %.
Afin de résoudre ce problème de volumétrie de pages à indexer pour un site donné, le moteur Google a introduit en 2005 le protocole sitemap. Il permet, grâce à la mise à disposition du robot d'un fichier sitemap, de gagner en efficacité pour l'indexation. Ce fichier est mis à la racine du site par l'administrateur du site web.
Raisons de la non-indexation
- Les sites contiennent de plus en plus de pages dynamiques : les hyperliens de navigation sont générés à la demande et diffèrent d'une visite à l'autre.
- Certains sites (ou partie de sites) ne sont pas liées par d'autres pages et ne peuvent donc pas être découvertes par les robots d'indexation (le seul moyen de les faire indexer est dès lors de demander explicitement cette indexation au moteur de recherche, ce qui est rarement fait, par ignorance de ce procédé). Ce contenu est connu comme des pages sans backlinks (ou inlinks).
- Il faut parfois remplir convenablement un formulaire de critères de recherche pour pouvoir accéder à une page précise. C'est le cas de sites exploitant des banques de données.
- Certains sites nécessitent une authentification (requérant un identifiant et un mot de passe) avant d'accéder au contenu réel : c'est le cas de certains sites payants et des sites avec des archives payantes (journaux en ligne, bases de données de météorologie, etc.).
- Les pages Web peuvent dans leur conception rendre difficile leur indexation. Elles peuvent en particulier contenir des éléments HTML frameset au lieu des éléments classiques body. Les balises consistant en un fichier robot.txt inséré dans le code d'une page permettent de protéger son copyright, de limiter les visites ou préserver le site d’accès trop fréquents. Or un robot n'est guère capable d'émettre des requêtes pertinentes ; sa visite d'indexation se réduit donc aux seules pages accessibles en suivant des URL statiques.
- L'utilisation du langage JavaScript (comme Ajax), mal compris, voire incompris par les robots[16], pour lier les pages entre elles constitue souvent un frein à leur indexation.
- Le web invisible est également constitué des ressources utilisant des formats de données incompréhensibles par les moteurs de recherche. Cela a été longtemps le cas du format PDF ou ceux de Microsoft Office (Excel, Word, Power Point…), le seul format reconnu initialement étant le langage natif du Web, l’HTML. Les grands moteurs de recherche (Google, Yahoo!, Bing…) sont capables d'indexer avec plus ou moins d'efficacité les documents utilisant ces formats[17],[18]. Google reconnaît les pages au format flash[19] depuis le début de 2008.
- Les moteurs de recherche classiques n’indexent qu’entre 5 et 60 % du contenu des sites accueillant de grandes bases de données : Internet Movie Database, PubMed, le National Climatic Data Center qui met en ligne une base de données contenant 370 000 Gio, alors que celle de la NASA est de 220 000 Gio[20].
- Les moteurs indexent partiellement les pages volumineuses : Google et Yahoo! se contentent de 500 kilooctets[21].
Web privé
Certaines pages sont inaccessibles aux robots du fait de la volonté de l'administrateur du site web. L'utilisation du fichier robots.txt notamment, mis à la racine d'un site web, permet de bloquer tout ou partie du site aux robots qui coopèrent, le site restant accessible aux internautes. Il est également possible d'utiliser l'élément meta robot dans le même but ainsi que pour empêcher de suivre des liens et interdire la mise en cache de pages (indépendamment de l'autorisation d'indexation). Ces pages sont alors parfois rangées dans une catégorie connexe à celle du web profond : le web privé (private web).
Web propriétaire
Le web propriétaire désigne les pages où il est nécessaire de s’identifier pour accéder au contenu. Le web propriétaire est compris dans le web profond.[réf. nécessaire]
Notes et références
- Terme recommandé depuis 2019 au Québec, cf. « Web invisible », Le Grand Dictionnaire terminologique, Office québécois de la langue française (consulté le ).
- Terme recommandé depuis 2017 en France par la Commission d’enrichissement de la langue française, cf. « Vocabulaire de l'informatique et de l'internet (liste de termes, expressions et définitions adoptés) NOR: CTNR1725303K », sur Légifrance (consulté le )
- (en) Michael K. Bergman, « The Deep Web: Surfacing Hidden Value », The Journal of Electronic Publishing 2001, vol. 7, no 1.
- (en) Jean-Philippe Rennard et Pierre Dal Zotto, « Darknet, darkweb, deepweb : ce qui se cache vraiment dans la face obscure d’Internet », sur The Conversation (consulté le )
- (en) Alex Wright, « Exploring a 'Deep Web' That Google Can’t Grasp », The New York Times, (lire en ligne, consulté le )
- « Vocabulaire de l'informatique et de l'internet (liste de termes, expressions et définitions adoptés) », sur www.legifrance.gouv.fr (consulté le )
- Fraudes en ligne : ne pas ignorer dark web et deep web , sur JournalDuNet.
- Plusieurs sites de vente de drogue du « Deep Web » français piratés, sur LeMonde.fr.
- Les « Red Rooms » du deep web: du mythe à la réalité, 7 juin 2018, par Valentine Leroy
- Deux plaques tournantes du "Dark web" fermées après une opération policière, sur LePoint.fr.
- Deux plaques tournantes du "Dark web" fermées après une opération policière, sur BourseDirecte.fr.
- On a (presque) acheté des armes, de la drogue et un passeport sur internet : plongée inédite au cœur du DARK WEB, sur RTL.be.
- « Web, 4% seulement du contenu est visible, où se cache le Deep Web ? - GinjFo », sur GinjFo (consulté le )
- Francis Pisani et Dominique Piotet, Comment le web change le monde : l'alchimie des multitudes, éd. Pearson, 2008 (ISBN 978-2-7440-6261-2), p. 188.
- (en) Chris Sherman et Gary Price, The Invisible Web, septembre 2001
- (en-US) « Understanding web pages better », sur Official Google Webmaster Central Blog (consulté le )
- (en) « Can A Search Engine Like Google.com Index My PDF Files? »
- (en) « Make your PDFs work well with Google (and other search engines) ».
- (en) « Webmaster Tools Help : Flash and other rich media files ».
- Jean-Paul Pinte, « Le Web invisible : l'antre du cybercrime », Pour la science, no 70, , p. 102
- Jean-Paul Pinte, « Le Web invisible : l'antre du cybercrime », Pour la science, no 70, , p. 103
Voir aussi
Liens externes
- Christophe Asselin, Web invisible, web caché, web profond
- Mettre à jour le web invisible, Le Grand Dictionnaire terminologique
- Jean-Pierre Lardy, Le web invisible, 2003, Université Claude Bernard - URFIST.
- Le web invisible [PDF], 2011, Université Nice Sophia Antipolis.
 Portail d’Internet
Portail d’Internet