Recherche d'information
La recherche d'information (RI[1]) est le domaine qui étudie la manière de retrouver des informations dans un corpus. Celui-ci est composé de documents d'une ou plusieurs bases de données, qui sont décrits par un contenu ou les métadonnées associées. Les bases de données peuvent être relationnelles ou non structurées, telles celles mises en réseau par des liens hypertexte comme dans le World Wide Web, l'internet et les intranets. Le contenu des documents peut être du texte, des sons, des images ou des données.
La recherche d'information est historiquement liée aux sciences de l'information et à la bibliothéconomie qui visent à représenter des documents dans le but d'en récupérer des informations, au moyen de la construction d’index. L’informatique a permis le développement d’outils pour traiter l’information et établir la représentation des documents au moment de leur indexation, ainsi que pour rechercher l’information. La recherche d'information est aujourd'hui un champ pluridisciplinaire, intéressant même les sciences cognitives.
La recherche d'information sur le web à l'aide d'un moteur de recherche est une technique de l'information et de la communication, désormais massivement adoptée par les usagers. Précédemment, durant l’Antiquité, des historiens connus tels que Thucydide et Hérodote ne pouvaient utiliser ce genre de méthode de recherche. Pour Hérodote, le plus important était de se rendre sur place, utiliser ses sens tels que l’ouïe et la vue. Puis, il commençait à mener son enquête en s’informant et se renseignant auprès du peuple. À l’inverse, Thucydide avait pour méthode d’écouter les rumeurs. Il consignait par écrit ces faits et avait pour but de les faire perdurer dans le temps pour en faire profiter les générations futures[2].
Introduction
Avec l'apparition des premiers ordinateurs est née l'idée d'utiliser des machines pour automatiser la recherche d'information dans les bibliothèques. Celle-ci a notamment été popularisée en 1945 par Vannevar Bush dans son célèbre article « As We May Think »[3].
Les premiers systèmes utilisés par des bibliothèques permettent d'effectuer des recherches booléennes, c’est-à-dire des recherches où la présence ou l'absence d'un terme dans un document conduit à la sélection du document. Ces recherches nécessitent plusieurs intermédiaires et surtout de gros moyens : il faut tout d'abord créer une nomenclature permettant de décrire l'ensemble des documents puis sélectionner, pour chaque document du corpus, les mots-clés permettant de le décrire. Une telle description par mots-clés (indexation matière) nécessite une grande expertise de la part du bibliothécaire, ses connaissances devant être suffisantes pour non seulement choisir les mots-clés reflétant au mieux le contenu d'un document, mais aussi pour choisir les termes permettant de le distinguer au sein du fond complet. Cette même connaissance est, de plus, partiellement nécessaire au moment de la recherche, lorsqu'il s'agit de « traduire » une question, plus ou moins précise, en un ensemble de mots-clés. Ce processus d'indexation, essentiellement manuel, est de plus insuffisamment exhaustif et précis. Il se peut par exemple que pour des problèmes de synonymie, certains documents répondant à la question d'un utilisateur puissent ne pas être retrouvés.
La description manuelle étant un processus lent ne garantissant pas de bons résultats, des recherches ont été menées pour extraire automatiquement la description d'un document à partir de son contenu. Dès les années 1970, des expériences ont montré que les techniques automatiques pouvaient fonctionner correctement sur des corpus de quelques milliers de documents[3]. L'utilisation grandissante des logiciels de traitements de texte, et par là même la mise à disposition de quantités de plus en plus importantes de textes directement interprétables par l'ordinateur va alors entraîner le développement rapide des modèles de RI. Ces deux aspects, l'indexation et la recherche sont au cœur des problèmes abordés par la RI. L'indexation et la recherche ont très rapidement évolué d'une modélisation booléenne de la recherche (un terme représente ou ne représente pas le document dans le cas de l'indexation, un document répond ou ne répond pas à la question) à des modèles vectoriels ou probabilistes.
La pertinence d'un document pour une question dans des modèles qui sont basés sur une représentation imprécise des documents et des questions s'exprime dans ce type de modèles de RI sous la forme d'un score. Ce score ne permet plus une validation automatique des systèmes de RI. En effet, pour la question « le document doit contenir le mot chèvre et élevage », un document contenant le mot « chèvre » et « élevage » est une bonne réponse, contrairement à un document qui ne les contiennent pas. Lorsque la question devient « le document doit avoir pour thème l'élevage des chèvres », un document qui parle de soin des chèvres sans utiliser le mot « élevage » sera une bonne réponse, mais aura un score moins important qu'un document qui parle directement de l'élevage des chèvres.
Il est donc impossible de prouver qu'un système de RI est performant puisque le score rend vague la notion de bonne réponse : un document répond plus ou moins bien à une question. La notion de pertinence d'un document pour une question émerge donc en même temps que les premiers systèmes de RI, avec les premières mesures permettant de comparer les différents résultats renvoyés par les systèmes de RI. Les premières mesures, encore largement employées aujourd'hui, sont la précision, le rappel, le bruit et le silence :
- Un système de RI est très précis si presque tous les documents renvoyés sont pertinents.
- Un système de RI a un bon rappel s'il renvoie la plupart des documents pertinents du corpus pour une question.
- Un système de RI est bruyant si il renvoie trop de documents dont peu sont pertinents.
- Un système de RI est silencieux si il ne renvoie pas assez de documents pertinents.
En général, les systèmes de recherche d'informations s'appuient sur ces différentes mesures et effectuent un équilibre entre eux. Il est possible, par exemple, d'affiner les requêtes à l'aide d'opérateurs de recherche complexes.
Des problématiques connexes se sont aussi greffées autour de la RI. Parmi les plus courantes et les plus utiles, l'interaction avec l'utilisateur permet d'obtenir progressivement des documents de plus en plus pertinents. Certains se sont ensuite essayés à simuler cette interaction, ou au moins une partie, en proposant des techniques permettant « d'enrichir » la question — en ajoutant par exemple des termes qui n'étaient pas dans la question originale. Cette technique est connue sous le nom d'expansion de requête[4].
De la recherche documentaire proprement dite, le domaine évolue vers des tâches proches, comme la classification qui permet de regrouper entre eux des documents ayant des thématiques proches, le classement qui a pour but de classer les documents dans un ensemble de catégories prédéfinies. Puis, à mesure que la notion de document et d'unité d'information devient plus floue, les tâches d'extraction d'information et de résumé automatique apparaissent. Actuellement, le domaine regroupe plusieurs thématiques de recherche et évolue avec l'apparition de nouveaux types de corpus, de documents et de besoins d'utilisateurs. Les conférences TREC et SIGIR donnent un aperçu de la diversité des recherches menées aujourd'hui dans le domaine général de la RI.
Précision de vocabulaire

Le Vocabulaire de la documentation (Paris, ADBS, 2004) distingue la recherche d'information de la recherche de l'information :
- recherche d'information : « Ensemble des méthodes, procédures et techniques permettant, en fonction de critères de recherche propres à l’usager, de sélectionner l’information dans un ou plusieurs fonds de documents plus ou moins structurés ».
- recherche de l'information : « Ensemble des méthodes, procédures et techniques ayant pour objet d’extraire d’un document ou d’un ensemble de documents les informations pertinentes ».
Au sens large, la recherche d'information inclut deux aspects :
- l'indexation des corpus, et
- l'interrogation du fonds documentaire ainsi constitué.
Ces deux aspects sont néanmoins très intimement liés en pratique, la manière d'indexer limitant ou influençant les possibilités de rechercher.
Composantes
Prétraitements
La première phase en recherche d'information est d'établir ces techniques permettant de passer d'un document textuel à une représentation exploitable par un modèle de RI. Cette transformation est scindée en deux étapes distinctes et correspond à l'indexation des documents :
- Il faut extraire d'un texte un ensemble de descripteurs. Ceux-ci sont la plupart du temps (après suppression des mots grammaticaux par exemple, reconnaissance des entités nommées) l'ensemble des termes qui apparaissent dans un document, souvent transformés (lemmatisation, ...)
- À l'aide de ce jeu de descripteurs, il est possible de représenter le document par un vecteur dans l'espace des termes. Il est également possible d'utiliser des connaissances a priori sur la façon dont les termes sont répartis dans les documents suivant leur importance.
Recherche
Une fois les documents transformés, il est possible de rechercher ceux qui répondent le mieux à une question d'un utilisateur et d'utiliser des modèles capables d'interagir avec l'utilisateur afin d'améliorer petit à petit les réponses du système de RI au cours d'une session — l'utilisateur indiquant à chaque fois les documents pertinents pour sa question. Ces indications peuvent aussi servir à améliorer globalement le fonctionnement du système de RI.
Mesures
En RI, la mise au point des modèles passe par une phase expérimentale qui suppose l'utilisation de métriques qui ont pour but de permettre la comparaison des modèles entre eux ou la mise au point de leurs paramètres. Ces mesures supposent connus un jeu de questions et les réponses pertinentes dans un corpus donné. Deux concepts simples, à savoir le rappel (proportion de documents pertinents renvoyés par le système parmi tous ceux qui sont pertinents) et la précision (proportion des documents pertinents parmi l'ensemble de ceux renvoyés par le système), ont été étendus pour permettre une analyse fine des performances de système de RI.
Prise en compte de l'utilisateur
L'utilisateur étant à l'origine du besoin en information, il est apparu nécessaire de compléter la simple requête par des informations supplémentaires en provenance de l'utilisateur. Le retour de pertinence est une approche qui peut par exemple prendre en compte un jugement de pertinence sur les documents présentés à l'utilisateur à l'issue de sa recherche. L'objectif est donc pour le système de savoir quels sont, parmi les documents présentés, ceux qui répondent vraiment au besoin de l'utilisateur.
Groupes sur la recherche d'information
Historiquement, la recherche d'information était faite dans les bibliothèques avec le protocole Z39.50 qui était maintenu par la Bibliothèque du Congrès. Ces travaux se poursuivent avec les protocoles SRW (Search / Retrieve via Web Services) et SRU (Search / Retrieve via URL). Il existe un important groupe de travail (SIGIR, Special Interest Group for Information Retrieval) dans l'association internationale ACM (Association for Computing Machinery), ainsi qu'une série de conférences et de campagnes d'évaluation organisées à ce sujet par le NIST : TREC (Text REtrieval Conference), qui ont traité, au fil des années, aussi bien des aspects multimédia de la recherche d'information que des problématiques liées au peuplement de bases de connaissances à partir du Web, de la recherche d'information en domaine de spécialité ou sur des plateformes de micro-blogging. Au niveau francophone, la communauté scientifique est notamment représentée par l'ARIA (Association Francophone de Recherche d'Information et Applications) et les conférences annuelles CORIA.
Modèles mathématiques de RI
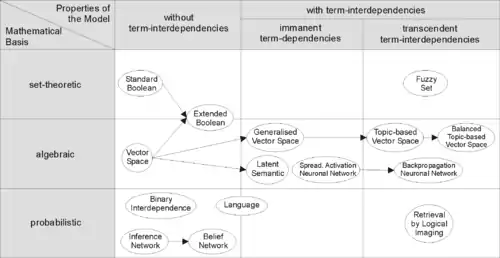
Les modèles de RI peuvent être classés selon deux aspects. La première dimension est le modèle mathématique considéré :
- L'approche ensembliste qui considère que l'ensemble des documents s'obtient par une série d'opérations (intersection, union et le passage au complémentaire). Le langage de requête SQL1 correspond à cette approche dite aussi de logique de premier niveau.
- L'approche algébrique (ou vectorielle) qui considère que les documents et les questions font partie d'un même espace vectoriel.
- L'approche probabiliste qui essaie de modéliser la notion de pertinence.
La seconde dimension prend en compte les liens pouvant exister entre les termes.
Modèles cognitifs de RI
Rechercher de l’information met en jeu pour l’usager toute une série de processus cognitifs (lecture, résolution de problème, savoirs procéduraux et savoirs déclaratifs, etc.)[réf. nécessaire]. Pour exposer le plus clairement possible ce qui se passe lors d’une RI, plusieurs chercheurs spécialisés (soit dans le domaine de l’information, soit dans le domaine des sciences cognitives) dans la recherche d’information ont proposé des modèles. Ceux-ci sont censés rendre compte de ce qui se passe concrètement et, pour certains, permettre de tirer des hypothèses sur l’origine cognitive des actes perceptibles.
Modèle de recherche d'information
Alors que la recherche d’information est une activité humaine ancienne, son étude s’est développée surtout avec l’apparition des systèmes de recherches documentaires informatisés[réf. nécessaire]. Un premier modèle est celui de l’Information Retrieval[5]. Dans ce modèle, on trouve trois éléments : l’usager, l’ensemble de documents et, entre les deux, le spécialiste de l’information (bibliothécaire ou documentaliste) qui peut interroger la base de données. Ce modèle a été conçu alors que les usagers n’avaient pas encore accès à des catalogues informatisés. Le bibliothécaire utilisait pour indexer les documents un langage fermé, de type thesaurus, et interrogeait le système en réutilisant ce même langage. Ainsi, l’usager ayant un besoin d’information, il l’exprime sous forme de question et le bibliothécaire transcrit celle-ci en requête pour interroger un système documentaire. Les documents, de l’autre côté, ont été représentés, c’est-à-dire transcrits en notices bibliographiques et indexés. Entre la requête et l’index du système s’opère alors un appariement qui fournira une réponse.
Critiques
Ce modèle a été critiqué[réf. nécessaire] pour deux raisons majeures. La première est le flou de certains termes utilisés (surtout la notion de besoin d’information) et le manque d’explication sur les connexions qui se font (comment passe-t-on d’un besoin à une question puis à une requête ?) La seconde tient à l’idée que le besoin d’information reste le même durant tout le travail. Or, toutes les études prouvent que la question initiale évolue très souvent lors d’une recherche.
Toutefois, ces critiques, même si elles sont valables dans l’absolu, sont amoindries par le fait qu’elles portent sur des points qui ne sont pas primordiaux dans ce système. Le but de ce modèle est de décrire concrètement ce qui se passe. L’aspect cognitif (et en l’occurrence, le besoin d’information), même s’il apparaît, n’est pas essentiel. C’est pour cela que les termes sont flous. De plus, même si le questionnement de l’usager va évoluer en même temps que son travail progresse, lorsqu’il interroge le bibliothécaire, à chaque fois il commence un nouveau cycle de recherche. Dès lors, la critique la plus forte serait de dire que ce modèle est maintenant obsolète, car l’intermédiaire entre le sujet et les documents n’existe plus.
Représentation en pivot
Plutôt que de voir la RI comme une confrontation entre un usager et un système de recherche d’information, des chercheurs et en premier lieu Marchionini[6],[7] ont proposé une représentation de la RI en insistant sur ce qui leur semble le cœur de celle-ci, à savoir la définition du problème selon quatre étapes :
- l’énonciation du problème
- le choix de la source d’information
- l’extraction de l’information
- l’examen des résultats
Chacune de ses actions entraîne des modifications dans la définition du problème. L’interaction entre l’usager et le système de recherche puis les documents entraîne une réévaluation des besoins et des savoirs. Dans cette représentation, la recherche n’est pas linéaire.
Évolution de cette représentation
Depuis les premiers travaux de Marchionini[6]et sa première modélisation, les données ont changé, surtout avec le développement de l’accès à internet. Une reformulation de cette représentation[8] met au centre le sujet. Celui-ci a un besoin d’information qui est flou, mais qui est perçu. Ceci va donc entraîner une série d’actions, dont l’interrogation d’une base de données. Cette interrogation se fonde sur la représentation du fonctionnement de l’interface. Les résultats vont faire évoluer la représentation du problème et entraîner d’autres actions.
Représentations basées sur l’exploration

Le postulat de base de ces représentations est que l’usager n’a pas une idée claire de ce qu’il cherche[réf. nécessaire]. Ce sont les réponses apportées par le système et les lectures de documents qui vont permettre à l’individu de préciser son besoin d’information. Bates a qualifié ce modèle de « berrypicking ». L’usager va cueillir des informations dans les documents comme on cueille des baies. Il passe d’un document à l’autre, se laisse mener par ce qu’il trouve et réfléchit, limite sa recherche au fur et à mesure, selon ce qu’il trouve.
Critiques
La critique principale[réf. nécessaire] insiste sur le fait que même si une recherche d’information est erratique, le sujet a malgré tout une idée de ce qu’il cherche. Cette question première sera peut-être profondément modifiée par la suite, mais il n’en demeure pas moins qu’une recherche part toujours de l’expression, plus ou moins claire, d’un manque. O’Day et Jeffries font évoluer la comparaison de la RI et la cueillette de baies et préfèrent voir la RI comme une course d’orientation[9]. L’usager ne sait pas vraiment ce qu’il cherche, mais il est en mesure de juger de ce qui est intéressant pour lui au regard des résultats. De plus, chaque document trouvé mène à une décision concernant la suite du travail. Enfin, si des représentations partielles apparaissent lors de la recherche, une représentation générale du but à atteindre perdure.
À côté de ces travaux qui visent plus à décrire la suite des actions qui constituent une recherche d’information, d’autres, issus de la psychologie cognitive, considèrent la RI comme une forme particulière de résolution de problèmes. La psychologie cognitive s’est intéressée à ce sujet et certaines théories ont été transférées dans l’étude de la RI.
Construction d’un espace de recherche
Lors d’une résolution de problème, le sujet doit élaborer une représentation de la situation de départ, une représentation du but et une représentation des actions licites. Dans une RI, cela correspondrait à l’écriture d’une question dans un système donné (situation de départ), à l’affichage de notices (situation-but), et à une liste des actions qui doivent être entreprises pour passer du besoin à la satisfaction. Ces trois représentations individuelles constituent l’espace de recherche. Ce dernier est à distinguer de l’espace de la tâche qui est virtuel et correspond à une résolution parfaite du problème.
Critiques
Ce modèle a été critiqué pour plusieurs raisons[réf. nécessaire]. À l’origine, la notion de résolution de problème s’appuyait sur des problèmes simples (ex. la tour de Hanoï). La situation de départ, la situation-but et les opérations licites étaient facilement exprimables. Dès que les problèmes sont des problèmes complexes et ouverts, la situation de départ et la situation-but ne sont plus aussi apparentes. La RI tient de ce type de tâche, ouverte et complexe. Au moment où commence une recherche, il est difficile de décrire complètement tous les éléments qui vont constituer la situation de départ. En effet, définir son besoin d’information est déjà une tâche complexe. La situation-but est encore plus malaisée à présenter. On peut dire comme Chen et Dhar que : « la situation-but est constituée par l’affichage de notices de documents se rapportant à la question posée et adaptés à l’usager destinataire de l’information. », mais cela ne dit pas comment se fait le lien entre la question et l’affichage de notices (est-ce que cet affichage est valable ?) ni surtout comment on peut affirmer que ces documents sont adaptés. Enfin, La liste des actions autorisées est peu maîtrisée par les utilisateurs d’un système de recherches. Plus l’usager est novice, moins il sait ce que le système accepte comme interrogation ou quelles sont les méthodes pour écrire une équation de recherche permettant de limiter le bruit et le silence. Or, ce respect des actions autorisées est une nécessité dans la présentation canonique de la résolution de problèmes.
Outils de recherche d'information
- DataparkSearch
- Lucene
- Mnogosearch
- Xapian
- Zettair
- Weblab intégrant Apache Solr
- Reportlinker
Références
- En anglais information retrieval, IR.
- B. François, Cours d’initiation à la culture antique, 5ème secondaire générale, Athénée Royal Vauban, Charleroi, 2019, p. 3-5.
- (en) Amit Singhal, « Modern Information Retrieval: A Brief Overview », Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, vol. 24, no 4, , p. 35–43 (lire en ligne)
- Aurélie Picton, Cécile Fabre, Didier Bourigault, « Méthodes linguistiques pour l’expansion de requêtes », sur https://www.cairn.info,
- M.-R. Amini, É. Gaussier, Recherche d'Information - Applications, modèles et algorithmes, Eyrolles, 2013, pp. I-XIX, 1-233, Paris
- (en) M. Agosti et P. G. Marchetti, « User navigation in the IRS conceptual structure through a semantic association function. », The Computer Journal, vol. 35, no 3, , p. 194–199 (DOI 10.1093/comjnl/35.3.194)
- Gary Marchionini, Information seeking in electronic environments, Cambridge University Press, (ISBN 0-521-44372-5) [détail des éditions]
- Zhang, J. and Marchionini, G. 2004. Coupling browse and search in highly interactive user interfaces: a study of the relation browser++. In Proceedings of the 4th ACM/IEEE-CS Joint Conference on Digital Libraries (Tucson, AZ, USA, June 7–11, 2004). JCDL '04. ACM, New York, NY, 384-384.
- O’Day, V. L., and Jeffries, R. (1993). Orienteering in an information landscape: How information seekers get from here to there. In Proceedings of ACM/InterCHI ’93
Voir aussi
Articles connexes
Liens externes
- M.-R. Amini, É. Gaussier, Recherche d'Information - Applications, modèles et algorithmes, Eyrolles, 2013, pp. I-XIX, 1-233, Paris
- M.Ihadjadene, Les systèmes de recherche d'informations: modèles conceptuels, 2004, Hermes, Paris
- M.Ihadjadene, Méthodes avancées pour les SRI, Hermes, 2004, Paris
- B. Grau, J.P. Chevallet, La recherche d'informations précises, Hermes, 2007, Paris
- M. Boughanem et J. Savoy, Recherche d'information : état des lieux et perspectives, Hermes, 2008, Paris
- P. Bellot, Recherche d'information contextuelle, assistée et personnalisée, 2011, Hermes, Paris
- T. Joachims, Information Retrieval and Language Technology (vidéos), 2003, Cornell University
- R. Ferber, Information Retrieval - Suchmodelle und Data-Mining-Verfahren für Textsammlungen und das Web, 2003, dpunkt.verlag, (ISBN 3-89864-213-5)
- C. J. Van Rijsbergen, Information Retrieval (2d edition), 1979, (ISBN 0-408-70929-4),
- Baeza-Yates, Ricardo A. and Ribeiro-Neto, Berthier, "Modern Information Retrieval", 1999, (ISBN 0-201-39829-X)
- Christopher D. Manning and Raghavan Prabhakar and Hinrich Schütze, An introduction to information retrieval, 2008
- Salaün, Jean-Michel. et Arsenault, Clément, 1962-, Introduction aux sciences de l'information, Presses de l'Université de Montréal, , 235 p. (ISBN 978-2-7606-2114-5 et 2760621146, OCLC 320584406, lire en ligne), p. 101-158
 Sciences de l’information et bibliothèques
Sciences de l’information et bibliothèques  Portail de l’informatique
Portail de l’informatique