Maximum de vraisemblance
En statistique, l'estimateur du maximum de vraisemblance est un estimateur statistique utilisé pour inférer les paramètres de la loi de probabilité d'un échantillon donné en recherchant les valeurs des paramètres maximisant la fonction de vraisemblance.
Cette méthode a été développée par le statisticien Ronald Aylmer Fisher en 1922[1],[2].
Exemple
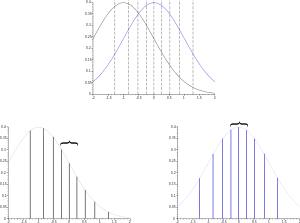
Soient neuf tirages aléatoires x1, …, x9 suivant une même loi ; les valeurs tirées sont représentées sur les diagrammes ci-contre par des traits verticaux pointillés. Nous voulons modéliser ces valeurs par une loi normale. Pour des raisons pratiques, nous avons pris les déciles de la loi normale centrée réduite (μ = 0, σ = 1) pour les xi, la méthode devrait donc faire ressortir cette loi-là.
Prenons deux lois modèles de même dispersion σ (écart type) mais ayant une position μ (moyenne, espérance) différente. Pour chacun des cas, nous déterminons les hauteurs hi correspondant à la valeur de la fonction de densité en xi. Nous définissons la vraisemblance L comme valant
- .

Dans le cas de la courbe bleue à droite, la fonction de densité est maximale à l'endroit où il y a le plus de valeurs — la zone est signalée par une accolade. Donc, logiquement, la vraisemblance est plus importante pour la courbe bleue que pour la courbe noire. De manière générale, on doit avoir une densité de valeurs xi importante là où la fonction de densité est importante ; le maximum de vraisemblance est donc pertinent pour sélectionner le paramètre position, lorsqu'il a un sens, de la loi modèle.

Prenons maintenant trois lois modèle toutes trois à la « bonne » position, mais ayant des écarts types différents. Dans le cas de la courbe verte à gauche, la dispersion est très importante, la courbe est très large et donc « ne monte pas très haut » (la surface sous la courbe devant être de 1, quelle que soit la courbe) ; les hi sont donc bas et L est faible.
Dans le cas de la courbe noire à droite, la dispersion est faible ; le sommet de la courbe est haut, mais les hi des extrémités sont eux très faibles, donc le produit L n'est pas très élevé.
La courbe bleue au centre a à la fois des hauteurs relativement élevées pour les hi du centre et des hauteurs non négligeables pour les hi des extrémités, ce qui donne un L élevé ; le maximum de vraisemblance est donc pertinent pour sélectionner le paramètre dispersion, lorsqu'il a un sens, de la loi modèle.

Pour notre exemple, si l'on trace la valeur de la vraisemblance L en fonction des paramètres μ et σ, on obtient une surface dont le maximum est en (μ = 0, σ = 1). La recherche de ce maximum est un problème d'optimisation classique.
Histoire
En 1912, au moment où Ronald Aylmer Fisher rédige son premier article consacré au maximum de vraisemblance, les deux méthodes statistiques les plus utilisées sont la méthode des moindres carrés et la méthode des moments[2]. Dans son article de 1912, il propose l'estimateur du maximum de vraisemblance qu'il appelle à l'époque le critère absolu[3],[2]. Il prend l'exemple d'une loi normale[2].
En 1921, il applique la même méthode à l'estimation d'un coefficient de corrélation[4],[2].
En 1912, un malentendu a laissé croire que le critère absolu pouvait être interprété comme un estimateur bayésien avec une loi a priori uniforme[2]. Fisher réfute cette interprétation en 1921[2]. En 1922, il utilise la loi binomiale pour illustrer son critère et montre en quoi il est différent d'un estimateur bayésien[5],[2]. C'est aussi en 1922, qu'il donne le nom de maximum de vraisemblance à sa méthode[2].
Principe
Soit une famille paramétrique de distributions de probabilités Dθ dont les éléments sont associés soit à une densité de probabilité (distribution continue) connue, soit à une fonction de masse (distribution discrète) connue, notée f(x|θ). On tire un n-échantillon simple (échantillons indépendants) x1, x2, …, xn de manière répétée de la distribution, et l'on calcule la densité de probabilité associée aux données observées

Ceci étant une fonction de θ avec x1, …, xn fixés, c'est une vraisemblance pour les n échantillons indépendants.

Lorsque θ n'est pas observable, la méthode du maximum de vraisemblance utilise les valeurs de θ qui maximisent L(θ) estimateur de θ : c'est l'estimateur du maximum de vraisemblance de θ noté . Par exemple dans le cas du produit discret, on effectue un tirage de n valeurs, il faut donc trouver le paramètre qui maximise la probabilité d'avoir tiré ce tirage (échantillon).

Cette méthode se distingue de la recherche d'un estimateur non biaisé de θ, ce qui ne donne pas nécessairement la valeur la plus probable pour θ.
L'estimateur du maximum de vraisemblance s'il existe, est unique.
Définitions
Soit une variable aléatoire réelle, de loi discrète ou continue, dont on veut estimer un paramètre . On note cette famille de lois paramétriques. Alors on définit une fonction telle que :





- représente la densité de X (où apparaît) et représente une probabilité discrète (où apparaît).


On appelle vraisemblance de au vu des observations d'un n-échantillon indépendamment et identiquement distribué selon une loi de la famille , le nombre :



On cherche à trouver le maximum de cette vraisemblance pour que les probabilités des réalisations observées soient aussi maximum. Ceci est un problème d'optimisation. On utilise généralement le fait que si L est dérivable (ce qui n'est pas toujours le cas) et si L admet un maximum global en une valeur , alors la dérivée première s'annule en et la dérivée seconde est négative. Réciproquement, si la dérivée première s'annule en et que la dérivée seconde est strictement négative en , alors est un maximum local de . Il est alors nécessaire de vérifier qu'il s'agit bien d'un maximum global. La vraisemblance étant positive et le logarithme népérien une fonction croissante, il est équivalent et souvent plus simple de maximiser le logarithme népérien de la vraisemblance (le produit se transforme en somme, ce qui est plus simple à dériver). On peut facilement construire la statistique qui est l'estimateur voulu.



Ainsi en pratique :
- La condition nécessaire
ou
permet de trouver la valeur . - est un maximum local si la condition suffisante est remplie au point critique :
ou




Pour simplifier, dans les cas de lois continues, où parfois la densité de probabilité est nulle sur un certain intervalle, on peut omettre d'écrire la vraisemblance pour cet intervalle uniquement.
Généralisation
Pour une variable aléatoire réelle X de loi quelconque définie par une fonction de répartition F(x), on peut considérer des voisinages V de (x1, …, xn) dans , par exemple une boule de rayon ε. On obtient ainsi une fonction de vraisemblance dont on cherche un maximum . On fait ensuite tendre la taille de V vers 0 dans pour obtenir l'estimateur de maximum de vraisemblance.





On retombe sur les fonctions de vraisemblance précédentes quand X est à loi discrète ou continue.
Si la loi de X est quelconque, il suffit de considérer la densité par rapport à une mesure dominante .

Une famille de loi est dominée par la mesure si .


Si X est une variable continue de dimension 1, alors on peut utiliser la mesure de Lebesgue sur (ou sur un intervalle de comme mesure dominante. Si X est une variable discrète de dimension 1, on peut utiliser la mesure de comptage sur (ou sur un sous-ensemble de ). On retrouve alors les définitions de la vraisemblance données pour les cas discrets et continus.


Propriétés
L'estimateur obtenu par la méthode du maximum de vraisemblance est :
- convergent[6],[7].
- asymptotiquement efficace, il atteint la borne de Cramér-Rao[6].
- asymptotiquement distribué selon une loi normale[8],[6],[9].
En revanche, il peut être biaisé en échantillon fini.
Intervalles de confiance
Comme l'estimateur du maximum de vraisemblance est asymptotiquement normal, on peut construire un intervalle de confiance tel qu'il contienne le vrai paramètre avec une probabilité [10] :



avec le quantile d'ordre de la loi normale centrée réduite et l'écart-type estimé de . On a alors





Tests
Test de Wald
Comme l'estimateur du maximum de vraisemblance est asymptotiquement normal, on peut appliquer le test de Wald[11].
On considère l'hypothèse nulle :

contre l'hypothèse alternative

L'estimateur est asymptotiquement normal :

avec l'écart-type estimé de l'estimateur

On définit la statistique de test :

On rejette alors l'hypothèse nulle avec un risque de première espèce lorsque la valeur absolue de la statistique de test est supérieure au quantile d'ordre de la loi normale centrée réduite :


avec la fonction quantile de la loi normale centrée réduite.

La p-value s'écrit alors[12] :

avec w la valeur de la statistique de test dans les données.
Test du rapport de vraisemblance
Si on appelle le vecteur des paramètres estimés, on considère un test du type[13] :

contre

On définit alors l'estimateur du maximum de vraisemblance et l'estimateur du maximum de vraisemblance sous . On définit enfin la statistique du test :



On sait que sous l'hypothèse nulle, la statistique du test du rapport de vraisemblance suit une loi du avec un nombre de degrés de liberté égal au nombre de contraintes imposées par l'hypothèse nulle (p) :


Par conséquent, on rejette le test au niveau lorsque la statistique de test est supérieure au quantile d'ordre de la loi du à p degrés de libertés.
On peut donc définir la valeur limite (p-value)[note 1] de ce test :

Exemples
Loi de Poisson
On souhaite estimer le paramètre d'une loi de Poisson à partir d'un n-échantillon :


L'estimateur du maximum de vraisemblance est :







Il est tout à fait normal de retrouver dans cet exemple didactique la moyenne empirique, car c'est le meilleur estimateur possible pour le paramètre (qui représente aussi l'espérance d'une loi de Poisson).
Loi exponentielle
On souhaite estimer le paramètre d'une loi exponentielle à partir d'un n-échantillon.

L'estimateur du maximum de vraisemblance est :







Là encore, il est tout à fait normal de retrouver l'inverse de la moyenne empirique, car on sait que l'espérance d'une loi exponentielle correspond à l'inverse du paramètre .
Loi normale
L'estimateur du maximum de vraisemblance de l'espérance et la variance d'une loi normale est[14] :

















L'estimateur de la variance est un bon exemple pour montrer que le maximum de vraisemblance peut fournir des estimateurs biaisés. En effet, un estimateur sans biais est donné par : . Néanmoins, asymptotiquement, quand n tend vers l'infini, ce biais, qui est de tend vers 0 et l'estimateur est alors asymptotiquement sans biais.


Loi uniforme
Dans le cas de l'estimation de la borne supérieure d'une loi uniforme, la vraisemblance ne peut pas être dérivée[15].

On souhaite estimer le paramètre a d'une loi uniforme à partir d'un n-échantillon.

La vraisemblance s'écrit :

Cette fonction n'est pas dérivable en . Sa dérivée s'annule sur tout l'intervalle . Il est clair que pour trouver le maximum de cette fonction il ne faut pas regarder là où la dérivée s'annule.


La valeur de L sera maximale pour , car est décroissante pour .



Cet exemple permet de montrer également que le logarithme de la vraisemblance n'est pas toujours bien défini (sauf si on accepte que ).

Applications
La méthode du maximum de vraisemblance est très souvent utilisée. Elle est notamment utilisée pour estimer le modèle de régression logistique ou le modèle probit. Plus généralement, elle est couramment utilisée pour estimer le modèle linéaire généralisé, classes de modèle qui inclut la régression logistique et le modèle probit.
Bibliographie
- (en) Larry Wasserman, All of Statistics : A Concise Course in Statistical Inference, New York, Springer-Verlag, , 461 p. (ISBN 978-0-387-40272-7, lire en ligne)
- (en) Colin Cameron et Pravin Trivedi, Microeconometrics : Methods And Applications, Cambridge University Press, , 1056 p. (ISBN 978-0-521-84805-3, lire en ligne)
Notes et références
Notes
- On rappelle que la p-value est définie comme la plus petite valeur du risque de première espèce () pour laquelle on rejette le test (Wasserman 2004, p. 156)
Références
- (en) John Aldrich, « R.A. Fisher and the making of maximum likelihood 1912-1922 », Statistical Science, vol. 12, no 3, , p. 162-176 (lire en ligne, consulté le )
- (en) Stephen Stigler, « The Epic Story of Maximum Likelihood », Statistical Science, vol. 22, no 4, (lire en ligne, consulté le ).
- (en) Ronald Fisher, « On an absolute criterion for fitting frequency curves », Messenger of Mathematics, no 41, , p. 155-160
- (en) Ronald Fisher, « On the "probable error" of a coefficient of correlation deduced from a small sample », Metron, no 1,
- (en) Ronald Fisher, « On the mathematical foundations of theoretical statistics », Philos. Trans. Roy. Soc. London Ser. A,
- Wasserman 2004, p. 126
- Cameron et Trivedi 2005, p. 119
- Wasserman 2004, p. 129, théorème 9.18
- Cameron et Trivedi 2005, p. 121
- Wasserman 2004, p. 129, théorème 9.19
- Wasserman 2004, p. 153, définition 10.3
- Wasserman 2004, p. 158, théorème 10.13
- Wasserman 2004, p. 164
- Wasserman 2004, p. 123, exemple 9.11
- Wasserman 2004, p. 124, exemple 9.12
Voir aussi
- Le maximum a posteriori est une généralisation quand la distribution a priori n'est pas uniforme.
- Vraisemblance empirique (en)
- Information de Fisher
- Fonction de vraisemblance
- Méthode delta
 Portail des probabilités et de la statistique
Portail des probabilités et de la statistique