SPARQL[1] est un langage de requêtes pour interroger des données qui sont stockées en respectant le modèle RDF. Le Resource Description Framework (RDF) est un modèle de données que nous allons décrire dans ce chapitre. Nous allons également donner les clés pour lire un document Turtle, ce qui nous servira à décrire les exemples de requêtes SPARQL dans les prochains chapitres.
Le format RDF/XML n'est utilisé dans la logique d'une base de données que comme un format d'échange entre des bases de données (format de dump). Le format RDF/XML n'est en principe pas écrit directement par un être humain, car trop verbeux. Par contre, le format RDF/Turtle est bien moins verbeux et plus simple à écrire pour les développeurs. Que ce soit du Turtle ou du XML, un document RDF n'est en principe jamais écrit directement par l'utilisateur final de la base de données.
Comme en SQL, SPARQL 1.1 offre les moyens d'écrire et de lire des données à travers de simples requêtes sans se soucier des formats divers qui servent à la maintenance de la base de données.
Représentation RDF des données
Définitions
Un document structuré en RDF
Un document structuré en RDF (Resource Description Framework) est un modèle de graphe destiné à décrire de façon formelle les ressources Web et leurs métadonnées, de façon à permettre le traitement automatique (par des machines) de telles descriptions.
Un document structuré en RDF est constitué d'un ensemble de triplets.
Un triplet RDF
Un triplet RDF est une association :
(sujet, prédicat, objet)
- Le sujet représente la ressource à décrire ;
- Le prédicat représente un type de propriété applicable à cette ressource ;
- L'objet représente une donnée ou une autre ressource : c’est la valeur de la propriété.
Le sujet d'un triplet peut-être:
- un IRI (Internationalized Resource Identifier)
- ou un nœud anonyme.
Le prédicat d'un triplet est nécessairement un IRI.
L'objet d'un triplet peut être :
- un IRI
- ou un nœud anonyme
- ou un littéral.
Le concept de nœud anonyme semble intéressant et simplifie sur papier la représentation d'un document RDF (comme avec le schéma plus bas). Cependant, ce concept est souvent implémenté de manière différente dans les logiciels, ce qui entraîne des problèmes de compatibilité et remet en question l’interopérabilité des documents RDF.
En attendant que ce problème soit réglé, il faut éviter d’utiliser des nœuds anonymes et donner un IRI arbitraire unique.
Un graphe RDF
Un graphe RDF, ainsi formé de triplets, est un multigraphe orienté étiqueté. Chaque triplet correspond alors à un arc orienté dont le label est le prédicat, le nœud source est le sujet et le nœud cible est l'objet.
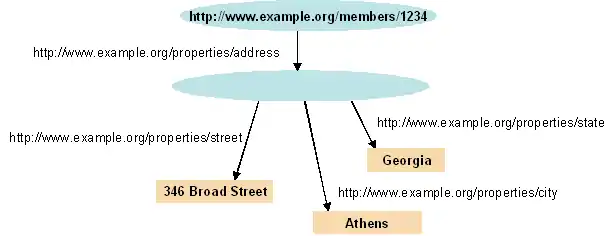
La sémantique d'un document RDF peut être exprimée en théorie des ensembles et en théorie des modèles, en se donnant des contraintes sur le monde qui peuvent être décrites en RDF. RDF hérite alors de la généricité et de l'universalité de la notion d'ensemble. Cette sémantique peut être aussi traduite en formule de logique du premier ordre, positive, conjonctive et existentielle :
- {sujet, objet, prédicat} ⇔ prédicat(objet, sujet)
ce qui est équivalent à :
- ∃ objet, ∃ sujet tq prédicat(objet, sujet)
Syntaxes
Les documents RDF peuvent être écrits en différentes syntaxes, y compris en XML (Extensible Markup Language). Mais RDF en soi n’est pas un dialecte XML. Il est possible d’avoir recours à d'autres syntaxes pour exprimer les triplets. Par exemple avec N3, Turtle, N-Quads, etc.
RDF est simplement une structure de données constituée de nœuds et organisée en graphe. Bien que RDF/XML — sa version XML proposée par le W3C — ne soit qu'une syntaxe (ou sérialisation) du modèle, elle est souvent appelée RDF. Un abus de langage qui désigne à la fois le graphe de triplets et la présentation XML qui lui est associée.
Dans ce cours, nous utiliserons le format Turtle pour nos exemples, car le W3C lui-même utilise cette syntaxe pour ses exemples dans ses recommandations.
Exemples
Exemple 1 : description RDF d'une personne nommée Eric Miller
L'exemple suivant est tiré du site du W3C (Resource Description Framework (RDF) Model and Syntax Specification) qui décrit une ressource avec les déclarations "il y a une personne qui a comme identifiant http://www.w3.org/People/EM/contact#me, dont le nom est Eric Miller, dont l'adresse email est em@w3.org, et qui a le titre de Docteur".
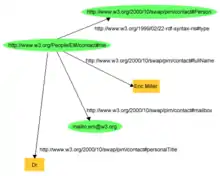
La ressource, sous forme d'IRI, "http://www.w3.org/People/EM/contact#me" est ici le sujet.
L'objet est :
- "Eric Miller" (avec le prédicat "quel est son nom"),
- em@w3.org (avec le prédicat "quel est son email"), et
- "Dr." (avec le prédicat "quel est son titre").
Le sujet ne peut être qu'une IRI.
Les prédicats sont aussi des IRIs. Par exemple, l'IRI pour chaque prédicat est :
- "quel est son nom" est http://www.w3.org/2000/10/swap/pim/contact#fullName,
- "quel est son email" est http://www.w3.org/2000/10/swap/pim/contact#mailbox,
- "quel est son titre" est http://www.w3.org/2000/10/swap/pim/contact#personalTitle.
De plus, le sujet a le type personne, c'est-à-dire :
- L'IRI du prédicat type est http://www.w3.org/1999/02/22-rdf-syntax-ns#type
- L'IRI de la classe Person est http://www.w3.org/2000/10/swap/pim/contact#Person
Par conséquent, les "sujet, prédicat, objet" suivants, c'est-à-dire les triplets RDF suivants peuvent être exprimés:
- http://www.w3.org/People/EM/contact#me, http://www.w3.org/2000/10/swap/pim/contact#fullName, "Eric Miller"
- http://www.w3.org/People/EM/contact#me, http://www.w3.org/2000/10/swap/pim/contact#personalTitle, "Dr."
- http://www.w3.org/People/EM/contact#me, http://www.w3.org/1999/02/22-rdf-syntax-ns#type, http://www.w3.org/2000/10/swap/pim/contact#Person
- http://www.w3.org/People/EM/contact#me, http://www.w3.org/2000/10/swap/pim/contact#mailbox, em@w3.org
Exemple 2: L'abréviation postale de New York
Certains concepts en RDF sont tirés de la logique et de la linguistique, où les structures sujet-prédicat et sujet-prédicat-objet ont des significations semblables, mais distinctes. Cet exemple démontre :
En langue française, la déclaration "New York a l'abréviation postale NY" aurait "New York" comme sujet, "a l'abréviation postale" comme prédicat et "NY" comme objet.
Codé comme un triplet RDF, le sujet et le prédicat devraient être nommés par des ressources IRI. L'objet pourrait être une ressource ou un élément littéral. Par exemple, dans la Notation3 sous forme de RDF, la déclaration pourrait ressembler à :
<urn:x-states:New%20York> <http://purl.org/dc/terms/alternative> "NY" .
Dans cet exemple, "urn:x-states:New%20York" est l'IRI d'une ressource qui représente l'État américain New York, "http://purl.org/dc/terms/alternative" est l'IRI du prédicat (dont voici la définition), et "NY" est une chaîne littérale. Notez que les IRI choisies ici ne sont pas standard, et n'ont pas besoin de l'être, tant que leur signification est lisible et accessible.
N-Triples est l'un des formats standards de sérialisation du RDF. Le triplet ci-dessus peut également être représenté de manière équivalente avec le standard RDF/XML, comme ci-dessous :
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dcterms="http://purl.org/dc/terms/">
<rdf:Description rdf:about="urn:x-states:New%20York">
<dcterms:alternative>NY</dcterms:alternative>
</rdf:Description>
</rdf:RDF>
Toutefois, en raison des restrictions sur la syntaxe de QNames (comme dcterms:alternative ci-dessus), certains graphes RDF ne sont pas représentables avec RDF/XML.
Exemple 3 : un article de Wikipédia sur Tony Benn
D'une manière similaire, étant donné que "http://en.wikipedia.org/wiki/Tony_Benn" identifie une ressource particulière (indépendamment du fait que l'IRI est un lien hypertexte, ou encore que la ressource est "en réalité" l’article Wikipédia sur Tony Benn) pour signifier que le titre de cette ressource est "Tony Benn" et que son éditeur est "Wikipédia", on aurait deux assertions qui pourraient être exprimées comme des déclarations RDF valides. Dans le format N-Triples de RDF, ces déclarations pourraient ressembler aux éléments suivants :
<http://en.wikipedia.org/wiki/Tony_Benn> <http://purl.org/dc/elements/1.1/title> "Tony Benn" .
<http://en.wikipedia.org/wiki/Tony_Benn> <http://purl.org/dc/elements/1.1/publisher> "Wikipedia" .
Et ces déclarations pourraient être exprimées en RDF/XML, comme :
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Description rdf:about="http://en.wikipedia.org/wiki/Tony_Benn">
<dc:title>Tony Benn</dc:title>
<dc:publisher>Wikipedia</dc:publisher>
</rdf:Description>
</rdf:RDF>
Pour une personne qui parle français, la même information peut être représentée simplement ainsi :
Le titre de cette ressource, qui est publiée par Wikipédia, est "Tony Benn".
RDF intègre les informations d'une manière formelle pour qu'une machine puisse les comprendre. L'objectif de RDF est de fournir un encodage et le mécanisme d'interprétation et de représentation des ressources pour des logiciels. Autrement dit, afin que des logiciels puissent accéder et utiliser des informations qui, sinon, ne pourraient pas être utilisées.
Les deux versions des écritures de RDF, ci-dessus, sont verbeux car les ressources doivent être uniques pour permettre d’identifier exactement les ressources décrites. Le prédicat doit être unique afin de réduire les chances de confondre la notion de titre ou d'Éditeur par un logiciel. Si le logiciel reconnaît "http://purl.org/dc/elements/1.1/title" (une définition spécifique pour le concept d'un titre établi par le Dublin Core Metadata Initiative), il doit aussi savoir que ce titre est différent d'un titre foncier ou d'un titre honorifique, ou tout simplement des lettres t-i-t-r-e concaténées.
L'exemple suivant montre comment représenter cette information en combinant plusieurs termes RDF. Ici, nous ajoutons le thème principal de la page Wikipédia, qui est une "personne" dont le nom est "Tony Benn" :
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Description rdf:about="http://en.wikipedia.org/wiki/Tony_Benn">
<dc:title>Tony Benn</dc:title>
<dc:publisher>Wikipedia</dc:publisher>
<foaf:primaryTopic>
<foaf:Person>
<foaf:name>Tony Benn</foaf:name>
</foaf:Person>
</foaf:primaryTopic>
</rdf:Description>
</rdf:RDF>
Types de données
IRIs
Un IRI est utilisé dans un triplet pour faire référence à un sujet, mais aussi pour l'objet, qui peut être une référence.
IRI ou Internationalized Resource Identifier (en français « Identificateur de ressource internationalisé ») est un type d'adresse informatique prenant en compte les divers alphabets utilisés dans les différentes langues du monde.
Les adresses IRI suivent une norme datant de 1998, généralisant et internationalisant les adresses URI (Uniform Resource Identifier), qui sont elles-mêmes un sur-ensemble des plus connues URL (Uniform Resource Locator) utilisées pour les adresses Web.
Un IRI est absolu quand il se compose :
- des lettres décrivant le protocole pour atteindre cette référence (par exemple http pour le protocole Web)
- suivie de «://»
- puis du nom de domaine
- ensuite, chaque nœud du chemin est séparé par « / »
- pour finir par le nom du document qui contient la référence (par exemple : http://mydoc.com/rep1/rep2/mydoc.htm)
- si la référence est une sous-partie d'un document, on ajoute « # » suivi du nom de l'ancre de la référence dans le document. Par exemple, http://mydoc.com/rep1/rep2/mydoc.htm#address pointe vers la référence qui décrit l'adresse dans le document.
L'utilisation des IRI absolus implique une notation très verbeuse. Pour éviter de réécrire la même racine de certaines IRI, on peut créer des préfixes et écrire des IRI relatifs. Par exemple, avec l'IRI <http://mydoc.com/rep1/rep2/mydoc.htm#address>, on peut définir un préfixe en Turtle ou en SPARQL comme ceci "PREFIX mydoc : <http://mydoc.com/rep1/rep2/mydoc.htm#>" et ainsi écrire la même IRI comme ceci mydoc:address
Un IRI est relatif quand il se compose :
- d'un préfixe
- du séparateur ":"
- du reste du chemin de l'IRI
Dans un document RDF au format Turtle ou dans une requête SPARQL, les IRI absolus sont entourés par '<' et '>' et la définition des préfixes est écrite au début du document.
On utilise souvent les mêmes préfixes par convention. Voici les préfixes les plus courants :
- rdf: http://www.w3.org/1999/02/22-rdf-syntax-ns#
- rdfs: http://www.w3.org/2000/01/rdf-schema#
- owl: http://www.w3.org/2002/07/owl#
- xsd: http://www.w3.org/2001/XMLSchema#
- dc: http://purl.org/dc/elements/1.1/
- foaf: http://xmlns.com/foaf/0.1/
Si vous ne connaissez pas un préfixe dans un exemple, vous pouvez utiliser le site http://prefix.cc
Exemple d'un document RDF au format Turtle sans préfixe qui contient un seul triplet :
<http://books.example/org1> <http://books.example/affiliates> <http://books.example/auth1> .
Exemple du même document RDF au format Turtle avec préfixe :
@prefix doc: <http://books.example/> . doc:org1 doc:affiliates doc:auth1 .
On peut également définir un préfixe par défaut si on n'indique pas le nom du préfixe :
@prefix : <http://books.example/> .
:org1 :affiliates :auth1 .
Littéraux
Un littéral peut être l’objet d'un triplet RDF, mais il ne peut pas être le sujet, ni le prédicat.
La syntaxe générale pour les littéraux est composée :
- d'une chaîne de caractères (entre guillemets, "...", ou entre des apostrophes, '...')
- d'une balise optionnelle de langue (language tag) (introduite par @)
- d'une balise optionnelle pour décrire le type de données du littéral. Le type prend la forme d'un IRI relatif ou absolu (introduit par ^^).
Par souci de commodité, les entiers peuvent être écrits directement (sans les guillemets et sans un type de données explicite). Voir le tableau ci-dessous :
| Datatype | Exemple dans SPARQL | Définition |
|---|---|---|
| xsd:string | "du texte unicode" | Séquence de caractères |
| xsd:boolean | true false |
true ou false |
| xsd:integer | -1 0 |
contient au minimum 18 digits ; le maximum de digits dépend de la plateforme |
| xsd:decimal | -1.23 12678967.543233 |
contient au minimum 18 digits ; le maximum de digits dépend de la plateforme |
| xsd:double | -1E4 1267.43233E12 |
IEEE double-precision 64-bit |
| xsd:date | "2002-10-10"^^xsd:date | yyyy-mm-dd |
| xsd:dateTime |
"2002-10-10T12:00:00Z"^^xsd:dateTime |
standard ISO 8601 (yyyy-mm-ddThh:mm:ss+01:00 en France) |
| xsd:time | "13:20:00"^^xsd:time | standard ISO 8601 (hh:mm:ss) |
Pour faciliter l'écriture des valeurs littérales qui contiennent elles-mêmes des guillemets, ou qui sont longues et contiennent des caractères « retour à la ligne », SPARQL fournit le moyen de construire un littéral entouré de trois apostrophes ou trois guillemets.
Par exemple, dans SPARQL, on peut écrire en théorie :
- "chat" est équivalent à "chat"^^xsd:string
- 'chat'@fr est équivalent à 'chat'^^xsd:string@fr , vous remarquerez le tag langue français
- "xyz"^^<http://example.org/ns/userDatatype>
- "abc"^^appNS:appDataType
- '''The librarian said, "Perhaps you would enjoy 'War and Peace'."'''
- 1, est équivalent à "1"^^xsd:integer
- 1.3 est équivalent à "1.3"^^xsd:decimal
- 1.300 est équivalent à "1.300"^^xsd:decimal
- 1.0e6 est équivalent à "1.0e6"^^xsd:double
- true est équivalent à "true"^^xsd:boolean
- false est équivalent à "false"^^xsd:boolean
Les types autorisés dans SPARQL sont liés à l'implémentation du logiciel. Il ne faut pas hésiter à tester la prise en compte d'un nouveau type en lecture et écriture avant d’utiliser en production ce nouveau type.
Format Turtle
Voici un exemple de document RDF au format Turtle :
@prefix dt: <http://example.org/datatype#> .
@prefix ns: <http://example.org/ns#> .
@prefix : <http://example.org/ns#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
:x ns:name "cat"@en .
:x ns:color “color”^^dt:color.
:y ns:p "42"^^xsd:integer .
:y ns:p "abc"^^dt:specialDatatype .
Le format Turtle est très instructif, car il y a de nombreuses similitudes avec une requête SPARQL comme :
- la définition des préfixes au début du document
- la syntaxe sous forme de triplets
- le point à la fin de chaque triplet
Un document RDF/Turtle donne de bonnes indications pour fabriquer une requête SPARQL (et offre des copier-coller bien pratique).
Vous remarquerez le "@" devant le mot clé prefix, ainsi que le point à la fin de chaque définition de préfixes. Ces détails sont importants, car ils sont source d'erreurs quand on fabrique une requête SPARQL à partir d'exemple RDF/Turtle.
Le sujet des triplets est souvent le même. Pour éviter de le répéter, on insère le caractère ";" devant un prédicat pour indiquer que le sujet est le même que le précédent triplet. Quand le sujet et le prédicat sont les mêmes, on peut utiliser une virgule devant un objet pour éviter de les recopier.
Voici le même exemple avec les raccourcis :
@prefix dt: <http://example.org/datatype#> .
@prefix ns: <http://example.org/ns#> .
@prefix : <http://example.org/ns#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
:x ns:name "cat"@en ;
ns:color "color"^^dt:color.
:y ns:p "42"^^xsd:integer , "abc"^^dt:specialDatatype .