Compression de données
La compression de données ou codage de source est l'opération informatique consistant à transformer une suite de bits A en une suite de bits B plus courte pouvant restituer les mêmes informations, ou des informations voisines, en utilisant un algorithme de décompression. C'est une opération de codage qui raccourcit la taille (de transmission, de stockage) des données au prix d'un travail de compression. Celle-ci est l'opération inverse de la décompression.
Un algorithme de compression sans perte restitue après décompression une suite de bits strictement identique à l'originale. Les algorithmes de compression sans perte sont utilisés pour les archives, les fichiers exécutables ou les textes.
Pour la compression de données sans pertes, on distingue principalement le codage entropique et le codage algorithmique. Le codage entropique est fondé sur des a priori quant à la source. On doit, par exemple, pour le codage de Huffman, transmettre une table de probabilités des symboles de la source. D'autres exemples sont les codages par dictionnaire comme LZ77, LZ78 et LZW. Le codage algorithmique, lui, ne nécessite de transmettre d'autres informations que le résultat du codage (et la méthode de compression utilisée).
Avec un algorithme de compression avec perte, la suite de bits obtenue après décompression est plus ou moins voisine de l'original selon la qualité désirée. Les algorithmes de compression avec perte sont utiles pour les images, le son et la vidéo.
Les formats de données tels que Zip, RAR, gzip, ADPCM, MP3 et JPEG utilisent des algorithmes de compression de données.
Gagner 5 % en efficacité de compression par rapport aux grands algorithmes courants peut typiquement multiplier par 100 le temps nécessaire à la compression[1].
La théorie de la compression de données utilise des concepts issus de la théorie de l'information : celle d'entropie au sens de Shannon.
Types de compression
Compression sans perte
La compression est dite sans perte lorsqu'il n'y a aucune perte de données sur l'information d'origine. Il y a autant d'information après la compression qu'avant, elle est seulement réécrite d'une manière plus concise (c'est par exemple le cas de la compression gzip pour n'importe quel type de données ou du format PNG pour des images synthétiques destinées au Web[2]). La compression sans perte est dite aussi compactage.
L'information à compresser est vue comme la sortie d'une source de symboles qui produit des textes finis selon certaines règles. Le but est de réduire la taille moyenne des textes obtenus après la compression tout en ayant la possibilité de retrouver exactement le message d'origine (on trouve aussi la dénomination codage de source en opposition au codage de canal qui désigne le codage correcteur d'erreurs).
Il n'existe pas de technique de compression de données sans perte universelle, qui pourrait compresser n'importe quel fichier : si une technique sans perte compresse au moins un fichier, alors elle en « grossit » également au moins un autre.
Compression avec pertes
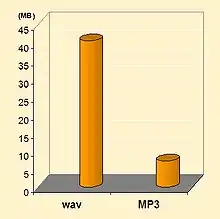
La compression avec pertes ne s'applique qu'aux données « perceptibles », en général sonores ou visuelles, qui peuvent subir une modification, parfois importante, sans que cela soit perceptible par un humain. La perte d'information est irréversible, il est impossible de retrouver les données d'origine après une telle compression. La compression avec perte est pour cela parfois appelée compression irréversible ou non conservative.
Cette technique est fondée sur une idée simple : seul un sous-ensemble très faible de toutes les images possibles (à savoir celles que l'on obtiendrait par exemple en tirant les valeurs de chaque pixel par un générateur aléatoire) possède un caractère exploitable et informatif pour l'œil. Ce sont donc ces images-là qu'on va s'attacher à coder de façon courte. Dans la pratique, l'œil a besoin pour identifier des zones qu'il existe des corrélations entre pixels voisins, c'est-à-dire qu'il existe des zones contiguës de couleurs voisines. Les programmes de compression s'attachent à découvrir ces zones et à les coder de la façon aussi compacte que possible. La norme JPEG 2000, par exemple, arrive généralement à coder des images photographiques sur 1 bit par pixel sans perte visible de qualité sur un écran, soit une compression d'un facteur 24 à 1.
Puisque l'œil ne perçoit pas nécessairement tous les détails d'une image, il est possible de réduire la quantité de données de telle sorte que le résultat soit très ressemblant à l'original, voire identique, pour l'œil humain. L'enjeu de la compression avec pertes est de réduire la quantité de données d'un fichier tout en préservant la qualité perceptible et en évitant l'apparition d'artefacts.
De même, seul un sous-ensemble très faible de sons possibles est exploitable par l'oreille, qui a besoin de régularités engendrant elles-mêmes une redondance (coder avec fidélité un bruit de souffle n'aurait pas grand intérêt). Un codage éliminant cette redondance et la restituant à l'arrivée reste donc acceptable, même si le son restitué n'est pas en tout point identique au son d'origine.
On peut distinguer trois grandes familles de compression avec perte :
- par prédiction, par exemple l'ADPCM ;
- par transformation. Ce sont les méthodes les plus efficaces et les plus utilisées. (JPEG, JPEG 2000, l'ensemble des normes MPEG…) ;
- compression basée sur la récurrence fractale de motifs (Compression fractale).
Les formats MPEG sont des formats de compression avec pertes pour les séquences vidéos. Ils incluent à ce titre des codeurs audio, comme les célèbres MP3 ou AAC, qui peuvent parfaitement être utilisés indépendamment, et bien sûr des codeurs vidéos — généralement simplement référencés par la norme dont ils dépendent (MPEG-2, MPEG-4), ainsi que des solutions pour la synchronisation des flux audio et vidéo, et pour leur transport sur différents types de réseaux.
Compression presque sans perte
Les méthodes de compression sans perte significative sont un sous-ensemble des méthodes de compression avec perte, parfois distinguées de ces dernières. La compression sans perte significative peut être vue comme un intermédiaire entre la compression conservative et la compression non conservative, dans le sens où elle permet de conserver toute la signification des données d'origine, tout en éliminant une partie de leur information.
Dans le domaine de la compression d'image, la distinction est faite entre la compression sans perte (parfaite au bit près ou bit-perfect) et la compression sans perte significative (parfaite au pixel près ou pixel-perfect). Une image compressée presque sans perte (à ne pas confondre avec une image compressée avec peu de pertes) peut être décompressée pour obtenir les pixels de sa version non-compressée à l'identique. Elle ne peut en revanche pas être décompressée pour obtenir sa version non compressée intégralement à l'identique (les métadonnées peuvent être différentes).
Techniques de compression presque sans perte
Parmi les algorithmes de compression presque sans perte, on retrouve la plupart des algorithmes de compression sans perte spécifiques à un type de données particulier. Par exemple, JPEG-LS permet de compresser presque sans perte du Windows bitmap et Monkey's Audio permet de compresser sans perte les données audio du wave PCM : il n'y a pas de perte de qualité, l'image et le morceau de musique sont exactement ceux d'origine.
Les algorithmes tels que Lempel-Ziv ou le codage RLE consistent à remplacer des suites de bits utilisées plusieurs fois dans un même fichier. Dans l'algorithme de codage de Huffman plus la suite de bits est utilisée souvent, plus la suite qui la remplacera sera courte.
Les algorithmes tels que la transformée de Burrows-Wheeler sont utilisés avec un algorithme de compression. De tels algorithmes modifient l'ordre des bits de manière à augmenter l'efficacité de l'algorithme de compression, mais sans compresser par eux-mêmes.
Codage RLE
Les lettres RLE signifient run-length encoding. Il s'agit d'un mode de compression parmi les plus simples : toute suite de bits ou de caractères identiques est remplacée par un couple (nombre d'occurrences ; bit ou caractère répété).
Exemple: AAAAAAAAZZEEEEEER donne : 8A2Z6E1R, ce qui est beaucoup plus court.
Compression CCITT
C'est une compression d'images utilisée par les télécopieurs (ou fax), standardisée par des recommandations de l'Union internationale des télécommunications (anciennement appelée CCITT). Elle est de type RLE (on code les suites horizontales de pixels blancs et de pixels noirs) et peut-être bidirectionnelle (on déduit une ligne de la précédente). Il existe plusieurs types de compressions (« groupes ») suivant l'algorithme utilisé et le nombre de couleurs du document (monochrome, niveau de gris, couleur).
Deux compressions existent, celle du Groupe 3 (recommandation ITU T.4) et celle du Groupe 4 (recommandation ITU T.6), utilisées pour les fax :
- Le Groupe 3 utilise comme indiqué une compression RLE, mais les symboles représentant les longueurs sont définis par le CCITT en fonction de leur fréquence probable et ceci pour diminuer la taille des messages à transmettre par les fax.
- La compression du Groupe 4, elle, représente une ligne par les différences avec la ligne précédente. Ainsi un carré noir sur une page blanche n'aura que la première ligne du carré à transmettre, les suivantes étant simplement la « différence », c'est-à-dire rien. Et la page complète revient à envoyer 3 lignes et un symbole de « répéter la précédente » pour toutes les autres.
Ceci est théorique : en pratique, il faudra transmettre plus de symboles, mais envoyer une page blanche est tout de même beaucoup plus rapide avec le Groupe 4 qu'avec le Groupe 3.
Codage de Huffman
L'idée qui préside au codage de Huffman est voisine de celle utilisée dans le code Morse : coder ce qui est fréquent sur peu de place, et coder en revanche sur des séquences plus longues ce qui revient rarement (entropie). En morse le « e », lettre très fréquente, est codé par un simple point, le plus bref de tous les signes.
L'originalité de David A. Huffman est qu'il fournit un procédé d'agrégation objectif permettant de constituer son code dès lors qu'on possède les statistiques d'utilisation de chaque caractère.
Le Macintosh d'Apple codait les textes dans un système inspiré de Huffman : les 15 lettres les plus fréquentes (dans la langue utilisée) étaient codées sur 4 bits, et la 16e combinaison était un code d'échappement indiquant que la lettre était codée en ASCII sur les 8 bits suivants. Ce système permettait une compression des textes voisine en moyenne de 30 % à une époque où la mémoire était extrêmement chère par rapport aux prix actuels (compter un facteur 1 000).
Le défaut du codage Huffman est qu'il doit connaître la fréquence des caractères utilisés dans un fichier avant de choisir les codes optimaux. Et il doit donc lire tout le fichier avant de comprimer. Une autre conséquence est que pour décompresser il faut connaître les codes et donc la table, qui est ajoutée devant le fichier, aussi bien pour transmettre que stocker, ce qui diminue la compression, surtout pour les petits fichiers. Ce problème est éliminé par le codage Huffman adaptatif, qui modifie sa table au fil des choses. Et peut donc démarrer avec une table de base. En principe, il commence avec les caractères à même probabilité.
Code Baudot

Le code Baudot est un exemple de compression concret, simple et représentatif. Ce code utilise une base de 5 bits pour coder les caractères alors que la table des caractères, étalée sur 6 bits, contient éléments. Cette dernière est séparée en deux jeux de éléments et deux caractères Inversion Lettres (code 31) et Inversion Chiffres (code 27) permettent de commuter entre les deux ensembles. Si les caractères étaient utilisés de manière aléatoire, ce système n'aurait aucun intérêt et entraînerait même un surplus de données avec une moyenne de bits par caractère. Cependant, les lettres sont codées sur le premier jeu de caractère tandis que les chiffres et caractères spéciaux sur le second. Or la nature des caractères utilisés n'est pas aléatoire. En effet, lorsque l'on écrit un texte cohérent, les chiffres sont séparés des lettres et les ponctuations sont rares.



Ainsi, on écrira :
le prix moyen d'une encyclopédie est de 112,45 euros (52 caractères)
L E [SP] P R I X [SP] M O Y E N [SP] D [FIGS] ' [LTRS] U N E [SP] E N C Y C L O P E D I E [SP] E S T [SP] D E [SP] [FIGS] 1 1 2 , 4 5 [SP] [LTRS] E U R O S
( bits)

Alors qu'il est peu probable que l'on ait à taper :
1e pr1 m0yen d'une en5yc10p3d1 e5t 2 cent12,45 eur0s (52 caractères)
[FIGS] 1 [LTRS] E [SP] P R [FIGS] 1 [SP] [LTRS] M [FIGS] 0 [LTRS] Y E N [SP] D [FIGS] ' [LTRS] U N E [SP] E N [FIGS] 5 [LTRS] Y C [FIGS] 1 0 [LTRS] P [FIGS] 3 [LTRS] D [FIGS] 1 [SP] [LTRS] E [FIGS] 5 [LTRS] T [SP] [FIGS] 2 [SP] [LTRS] C E N T [FIGS] 1 2 , 4 5 [SP] [LTRS] E U R [FIGS] 0 [LTRS] S
( bits)

Sans compression, c'est-à-dire en codant chaque caractère sur 6 bits, ces chaînes de caractère auraient le même poids de bits.

Ici on remarque qu'en utilisant le code Baudot le premier texte a été compressé de manière bénéfique contrairement au second. En effet, alors que la première chaîne était prévisible, la seconde ne l'était clairement pas.
Le code Baudot joue donc sur la probabilité de la répartition des caractères au sein d'un texte intelligible.
Codage arithmétique
Le codage arithmétique est assez similaire au codage de Huffman en ceci qu'il associe aux motifs les plus probables les codes les plus courts (entropie). Contrairement au codage de Huffman qui produit au mieux des codes de 1 bit, le codage arithmétique peut produire des codes vides. Le taux de compression obtenu est par conséquent meilleur.
Lempel-Ziv 1977 (LZ77)
La compression LZ77 remplace des motifs récurrents par des références à leur première apparition.
Elle donne de moins bons taux de compression que d'autres algorithmes (PPM, CM), mais a le double avantage d'être rapide et asymétrique (c'est-à-dire que l'algorithme de décompression est différent de celui de compression, ce qui peut être exploité pour avoir un algorithme de compression performant et un algorithme de décompression rapide).
LZ77 est notamment la base d'algorithmes répandus comme Deflate (ZIP, gzip) ou LZMA (7-Zip, xz)
Lempel-Ziv 1978 et Lempel-Ziv-Welch (LZ78 et LZW)
LZW est basée sur la même méthode, mais Welch a constaté que, en créant un dictionnaire initial de tous les symboles possibles, la compression était améliorée puisque le décompresseur peut recréer le dictionnaire initial et ne doit donc pas le transmettre ni envoyer les premiers symboles. Elle a été brevetée par UNISYS et ne pouvait donc être utilisée librement dans tous les pays jusqu'à l'expiration du brevet en 2003. Elle sert dans les modems, mais UNISYS s'est engagé à vendre une licence à tout fabricant avant d'être acceptée comme norme de compression internationale pour les modems.
La compression Lempel-Ziv-Welch est dite de type dictionnaire. Elle est basée sur le fait que des motifs se retrouvent plus souvent que d'autres et qu'on peut donc les remplacer par un index dans un dictionnaire. Le dictionnaire est construit dynamiquement d'après les motifs rencontrés.
Prédiction par reconnaissance partielle (PPM)
La prédiction par reconnaissance partielle se base sur une modélisation de contexte pour évaluer la probabilité des différents symboles. En connaissant le contenu d'une partie d'une source de données (fichier, flux…), un PPM est capable de deviner la suite, avec plus ou moins de précision. Un PPM peut être utilisé en entrée d'un codage arithmétique par exemple.
La prédiction par reconnaissance partielle donne en général de meilleurs taux de compression que des algorithmes à base de Lempel-Ziv, mais est sensiblement plus lente.
Pondération de contextes (CM)
La pondération de contextes consiste à utiliser plusieurs prédicteurs (par exemple des PPM) pour obtenir l'estimation la plus fiable possible du symbole à venir dans une source de données (fichier, flux…). Elle peut être basiquement réalisée par une moyenne pondérée, mais les meilleurs résultats sont obtenus par des méthodes d'apprentissage automatique comme les réseaux de neurones.
La pondération de contextes est très performante en termes de taux de compression, mais est d'autant plus lente que le nombre de contextes est important.
Actuellement, les meilleurs taux de compression sont obtenus par des algorithmes liant pondération de contextes et codage arithmétique, comme PAQ.
Transformée de Burrows-Wheeler (BWT)
Il s'agit d'un mode de réorganisation des données et non un mode de compression. Il est principalement destiné à faciliter la compression de texte en langue naturelle, mais il est également utilisable pour compresser n'importe quelles données binaires. Cette transformation, qui est complètement réversible, effectue un tri sur toutes les rotations du texte source, ce qui tend à regrouper les caractères identiques ensemble en sortie, ce qui fait qu'une compression simple appliquée aux données produites permet souvent une compression très efficace.
Techniques de compression avec pertes
La compression avec pertes ne s'applique que sur des données perceptuelles (audio, image, vidéo), et s'appuie sur les caractéristiques du système visuel ou du système auditif humain pour ses stratégies de réduction de l'information. Les techniques sont donc spécifiques à chaque média. Ces techniques ne sont pas utilisées seules mais sont combinées pour fournir un système de compression performant.
Sous-échantillonnage
En image et en vidéo, il est fréquent d'effectuer un sous-échantillonnage spatial des composantes de chrominance. Le système visuel humain étant plus sensible aux variations de luminance que de couleur, la suppression d'une partie importante de l'information couleur n'est que peu visible[3].
Quantification
La quantification est l'étape la plus importante dans la réduction de l'information. C'est sur la quantification que l'on joue lorsque l'on souhaite atteindre un débit cible, généralement en utilisant un modèle débit-distorsion.
Lors d'un codage par transformation (ondelettes ou DCT par exemple), la quantification s'applique sur les coefficients dans l'espace transformé, en réduisant leur précision.
Taux de compression
Le taux de compression est relié au rapport entre la taille du fichier comprimé et la taille du fichier initial . Le taux de compression est généralement exprimé en pourcentage. Un taux de 50 % signifie que la taille du fichier comprimé est la moitié de . La formule pour calculer ce taux est :






Exemple : =550 Mo, =250 Mo

L'algorithme utilisé pour transformer en est destiné à obtenir un résultat de taille inférieure à . Il peut paradoxalement produire parfois un résultat de taille supérieure : dans le cas des compressions sans pertes, il existe toujours des données incompressibles, pour lesquelles le flux compressé est de taille supérieure ou égale au flux d'origine.






















Bases de données et compression
Certaines bases de données permettent de compresser les données des tables et des index sans pour autant obliger de décompresser les données afin de les exploiter en lecture séquentielles (scan) comme en accès par recherche (seek).
C'est le cas en particulier de Microsoft SQL Server qui permet de compresser en mode "ROW" (élimination des espaces vides), comme en mode "PAGE" (dictionnaire partiel).
On retrouve ces principes dans Oracle et DB2.
PostgreSQL ne possède pas de technique de compression à l'exception du stockage des LOBs (Large OBjects, tel que image, son, vidéo, longs texte ou binaires de documents électroniques) qui sont, par défaut, compressés via TOAST (The Oversized-Attribute Storage Technique).
Notes et références
- Algorithme zopfli : https://code.google.com/p/zopfli/.
- Ces deux types de compressions gzip et PNG sont libres et non soumis à un brevet.
- Douglas A. Kerr, Chrominance Subsampling in Digital Images 2009.
- On retranche 256⁰ = 1 de la somme car aucun flux compressé ne peut être de taille nulle.
Voir aussi
Bibliographie
- Istok Kespret, Compresser vos données avec LHA, PKZIP, ARJ… - (éd. Micro Application, coll. « Le livre de », 1994) - 348 p. - (ISBN 2-7429-0172-8)
- Jean-Paul Guillois, Techniques de compression des images - (éd. Hermès - Lavoisier, coll. « IC2 », 1996) - 252 p. - (ISBN 2-86601-536-3)
Articles connexes
- Modélisation de Markov dynamique
- Liste de logiciels de compression de données
- Format de données
- Taux de compression de données
- Quotient de compression
- Quantification vectorielle
- Compression audio
- Compression vidéo
- Compression de courbe
- Compression d'image
- Algorithme de Douglas-Peuker
- Compression compacte
- Théorème des répétitions maximales
Liens externes
 Portail de l’informatique
Portail de l’informatique