Alphabet ougaritique
L'alphabet ougaritique est une forme d'alphabet attesté dans la ville d'Ougarit, (Syrie) entre le XVe et le début du XIIIe siècle av. J.-C.
| Ougaritique | |
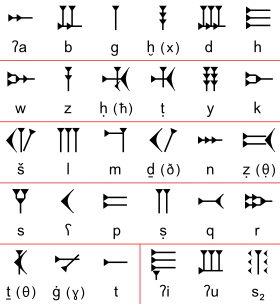 L'alphabet ougaritique | |
| Caractéristiques | |
|---|---|
| Type | Abjad |
| Langue(s) | Ougaritique, hourrite |
| Historique | |
| Époque | Vers 1500 av. J.-C. |
| Codage | |
| Unicode | U+10380 à U+1039F |
| ISO 15924 | Ugar
|
Alors que la plupart des tablettes sont écrites en cunéiforme syllabique notant la langue akkadienne (langue sémitique) ou hittite (langue indo-européenne), quelques-unes le sont dans une nouvelle écriture cunéiforme, dite « alphabet ougaritique », servant à noter une langue sémitique cananéenne (ainsi que des textes hourrites). Cette écriture est parmi les tout premiers abjads connus, avec les écritures sinaïtiques. Il atteste pour la première fois de l'ordre des lettres encore utilisé de nos jours dans la plupart des alphabets modernes (alphabet latin, alphabet grec, alphabet étrusque mais aussi alphabets sémitiques comme les alphabets phénicien et hébreu), l'ordre dit « levantin ».
Composition de l'alphabet
L'existence d'un classement alphabétique nous est connue par plusieurs tablettes abécédaires. Des tablettes plus rares, trouvées à Beth Šemeš, classent cependant les lettres dans l'ordre sud-arabique. L'abécédaire ougaritique le plus courant donne vingt-sept lettres (suivies de trois additionnelles) dans cet ordre (transcription traditionnelle des langues sémitiques) :
ʾa, b, g, ḫ, d, h, w, z, ḥ, ṭ, y, k, š, l, m, ḏ, n, ṯ̣, s, ʿ, p, ṣ, q, r, ṯ, ǵ, t, ʾi, ʾu, s̀
Note : la lettre transcrite par ṯ̣ l'est par ẓ dans l'article de O'Connor (cf. bibliographie infra).
La première lettre n'est pas la voyelle /a/ mais le coup de glotte (une consonne) suivi de la voyelle /a/, car cet abjad — qui n'écrivait normalement pas les voyelles — ne servait pas à noter ce coup de glotte seul : en effet, ʾi et ʾu (coup de glotte suivi de /i/ ou /u/) semblent avoir été ajoutés à la fin de l'alphabet, donc tardivement. Il est possible qu'à l'invention de cet abjad il désignât le coup de glotte vocalisé (quel que soit le timbre de la voyelle) et ne se soit spécialisé que plus tard pour le coup de glotte suivi de /a/ et non pas d'une autre voyelle, d'où l'ajout des deux autres formes dans une période plus tardive.
La présence de quelques graphèmes syllabiques (dont ʾi et ʾu ajoutés à la suite) est un emprunt au modèle akkadien, d'où la présence d'un s̀, servant à transcrire une consonne non sémitique de valeur inconnue et vraisemblablement utilisée pour les textes écrits en hourrite. Le tracé de certains caractères varie selon les sources de documentation. Il n'y a en effet pas de modèle archétypal réel et les inscriptions peuvent être de styles très différents.
Codage informatique
L'ougaritique a été ajouté aux caractères d'Unicode à partir de la quatrième version (avril 2003). Il se trouve dans le bloc du même nom qui s'étend des emplacements U+10380 à U+1039F. Ces caractères étant situés hors du plan multilingue de base (PMB), tous les systèmes d'exploitation et les navigateurs ne sont pas capables de les afficher ou de les manipuler.
En 2012, peu de polices de caractères contiennent les œils nécessaires[1] :
- Aegean,
- ALPHABETUM Unicode,
- Andagii,
- Code2001,
- Everson,
- Free Sans,
- MPH 2B Damase,
- Ugaritic 3.03 Unicode.
Voici les caractères prévus par Unicode (leur affichage correct dépend de votre système) :
| nom d'Unicode | glyphe | Unicode | valeur | entité HTML |
|---|---|---|---|---|
| Lettre ougaritique alpa | 𐎀 | 10380 | ʾa | 𐎀 |
| Lettre ougaritique bêta | 𐎁 | 10381 | b | 𐎁 |
| Lettre ougaritique gamla | 𐎂 | 10382 | g | 𐎂 |
| Lettre ougaritique kha | 𐎃 | 10383 | ḫ | 𐎃 |
| Lettre ougaritique delta | 𐎄 | 10384 | d | 𐎄 |
| Lettre ougaritique ho | 𐎅 | 10385 | h | 𐎅 |
| Lettre ougaritique wo | 𐎆 | 10386 | w | 𐎆 |
| Lettre ougaritique dzêta | 𐎇 | 10387 | z | 𐎇 |
| Lettre ougaritique hota | 𐎈 | 10388 | ḥ | 𐎈 |
| Lettre ougaritique tèt | 𐎉 | 10389 | ṭ | 𐎉 |
| Lettre ougaritique yod | 𐎊 | 1038A | y | 𐎊 |
| Lettre ougaritique kaf | 𐎋 | 1038B | k | 𐎋 |
| Lettre ougaritique chîn | 𐎌 | 1038C | š | 𐎌 |
| Lettre ougaritique lambda | 𐎍 | 1038D | l | 𐎍 |
| Lettre ougaritique mém | 𐎎 | 1038E | m | 𐎎 |
| Lettre ougaritique dhal | 𐎏 | 1038F | ḏ | 𐎏 |
| Lettre ougaritique noûn | 𐎐 | 10390 | n | 𐎐 |
| Lettre ougaritique zou | 𐎑 | 10391 | ẓ | 𐎑 |
| Lettre ougaritique samka | 𐎒 | 10392 | s | 𐎒 |
| Lettre ougaritique ’aïn | 𐎓 | 10393 | ʕ | 𐎓 |
| Lettre ougaritique pou | 𐎔 | 10394 | p | 𐎔 |
| Lettre ougaritique çadé | 𐎕 | 10395 | ṣ | 𐎕 |
| Lettre ougaritique qopa | 𐎖 | 10396 | q | 𐎖 |
| Lettre ougaritique racha | 𐎗 | 10397 | r | 𐎗 |
| Lettre ougaritique thanna | 𐎘 | 10398 | ṯ | 𐎘 |
| Lettre ougaritique ghaïn | 𐎙 | 10399 | ǵ | 𐎙 |
| Lettre ougaritique to | 𐎚 | 1039A | t | 𐎚 |
| Lettre ougaritique i | 𐎛 | 1039B | ʾi | 𐎛 |
| Lettre ougaritique ou | 𐎜 | 1039C | ʾu | 𐎜 |
| Lettre ougaritique ssou | 𐎝 | 1039D | s2 | 𐎝 |
| Séparateur ougaritique de mots | 𐎟 | 1039F | - | 𐎟 |
Notez bien: Ces noms d'Unicode ne sont pas utilisés dans les textes ougaritiques eux-mêmes, et ont été créés à partir des noms de lettres dans différentes écritures (alphabet grec, abjad arabe, etc). Le code 1039E n’est pas attribué.
Notes et références
- Cf. les pages site d'Alan Wood ou du site www.fileformat.info.
Bibliographie
- John Healey, « The Early Alphabet », dans Reading the Past, ouvrage collectif, British Museum Press, 1990 ;
- M. O'Connor, article « Epigraphic Semitic Scripts », dans The World's Writing Systems, ouvrage collectif sous la direction de Peter T. Daniels et William Bright, Oxford University Press, 1996 ;
- Charles Higounet, L'écriture, collection « Que sais-je ? », numéro 653, Presses universitaires de France, 11e édition de 2003 ;
- Marguerite Yon, La Cité d'Ougarit sur le tell de Ras Shamra, ERC, Paris, 1997 (en vente à l'Association pour la défense de la pensée française à Paris) ;
- « Le royaume d'Ougarit, aux origines de l'alphabet », hors-série de Les Dossiers d'archéologie, éditions Faton ;
- Emmanuel de Roux, « L’alphabet du royaume d’Ougarit », Le Monde, (lire en ligne)
- Stanislav Segert, A Basic Grammar of the Ugaritic Language: With Selected Texts and Glossary, University of California Press, 1984
Voir aussi
Articles connexes
- Ougarit
- Cunéiforme
- Ougaritique (langue)
- Alphabet protocananéen, Alphabet protosinaïtique
- Textes ougaritiques (en)
Liens externes
- Les caractères Ougarit dans Brian Colless (version 1)
- Les caractères Ougarit dans Brian Colless (version 2)
- Les caractères Ougarit
- Les caractères Ougarit dans l'Unicode (plage Ugaritic, U+10380 à U+1039F)
- fichier *.kmap permettant la saisie des caractères ougaritiques pour le logiciel yudit (fichier binaire compilé *.my disponible).
 Portail de l’écriture
Portail de l’écriture  Portail du Proche-Orient ancien
Portail du Proche-Orient ancien