Projet génome humain
Le projet génome humain (en anglais, Human Genome Project ou HGP) est un programme lancé fin 1988 dont la mission était d'établir le séquençage complet de l'ADN du génome humain. Son achèvement a été annoncé le [1]. Le nouveau projet lancé dans la foulée en , ENCODE (Encyclopedia of DNA Elements), donne des résultats importants sur l'ADN non codant humain.
Pour les articles homonymes, voir HGP et Génome humain.
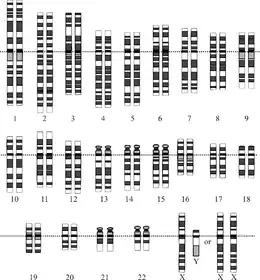
Le génome humain est l'ensemble de l'information génétique portée par l'ADN sur les 23 paires de chromosomes présent dans le noyau plus l'ADN mitochondrial (hérité de la mère uniquement). Il porte l'ensemble de l'information génétique humaine, estimée à 100 000 gènes avant le séquençage et qui s'est révélée contenir finalement de 20 000 à 25 000 gènes[2]. Cette entreprise de grande ampleur est le résultat d'une coopération scientifique internationale qui s'est étalée sur près de quinze ans. Elle a donné lieu sur le final à une compétition acharnée entre le consortium public international et une société privée, Celera Genomics[3].
Des scientifiques pensent être capables de concevoir le premier génome humain en 2026[4]. D'autres prennent leurs distances avec les affirmations présomptueuses, rappellent le peu de retombées en termes de maîtrise génétique, et mesurent l'énormité de l'ignorance humaine dans le domaine[5]. Le projet Génome Humain n'était plus présenté en 2011 que comme un « préalable » à de réelles avancées, attendues donc pour plus tard[6].
Historique
Genèse du projet
L'idée du projet est lancée début 1985. Trois scientifiques vont indépendamment proposer ce projet. Tout d'abord Renato Dulbecco, prix Nobel 1975 pour la découverte des oncogènes évoque cette possibilité au cours de conférences. Il publiera ensuite une tribune dans le journal américain Science[7]. Puis, Robert Sinsheimer, le chancelier de l'université de Californie à Santa Cruz (Californie), organise une conférence sur la question en [8], mais ne trouve pas de financements. Le projet sera initialement soutenu par le Department of Energy (DOE) américain en 1986, et son directeur de la biologie, Charles DeLisi, qui financera un certain nombre d'études de faisabilité et de développements précoces.
Deux années de discussions animées sur l'opportunité du séquençage suivront dans la communauté scientifique, avant que, fin 1988, la décision de lancer le projet en grand ne soit prise sur recommandation du National Research Council américain. Simultanément, en Suisse est créée HUGO, la Human Genome Organisation, qui a pour objectif de coordonner les efforts de tous les pays au niveau mondial.
Le projet débute en 1989 pour une durée prévue de 15 ans, avec un budget global estimé à 3 milliards de dollars. Il comprendra l'étude non seulement du génome humain, mais aussi celui d'organismes modèles comme le colibacille ou la drosophile. Le pilotage en est finalement confié au National Institutes of Health et son premier directeur sera James Watson, co-découvreur de la structure de la double-hélice d'ADN. La publication de la séquence « brute » sera finalement faite en février 2001[9], trois ans avant l'échéance prévue.
Course avec Celera
En 1998, Craig Venter qui dirige alors le The Institute for Genomic Research (TIGR), une fondation privée sans but lucratif, annonce qu'il fonde une compagnie privée, Celera Genomics, avec le soutien de Perkin-Elmer, une grande société d'instrumentation scientifique. Leur objectif est de séquencer le génome humain en trois ans seulement, par une approche hautement robotisée. Celera compte rentabiliser son investissement massif (environ 300 millions de dollars) en vendant l'accès au génome à des sociétés pharmaceutiques.
Cette annonce provoque un tollé dans la communauté scientifique qui considère le génome humain comme un patrimoine commun de l'humanité, dont l'appropriation par des intérêts privés est intolérable. Il s'ensuivra dès lors une course de trois ans entre Celera et le consortium international public, dirigé par Francis Collins, qui a succédé à James Watson. Celle-ci se terminera par un match nul en juin 2000. Le 26 juin, Bill Clinton annonce officiellement la fin du séquençage « brut » du génome depuis la Maison-Blanche.
Polémique
La publication officielle des deux séquences « brutes », celles du consortium international et celle de Celera intervient en . Pour reconstruire le génome à partir des fragments d'ADN séquencés, Celera annonce avoir utilisé non seulement ses propres données, mais aussi celles publiées en ligne au fur et mesure par le consortium international. La communauté scientifique s'indigne de ce procédé et affirme que la méthode utilisée par Venter et ses collègues de Celera n'aurait pu fonctionner sans ce pillage.
Trois ans après, l'équipe de Celera republiera sa séquence, obtenue cette fois sans l'aide des données du consortium international, pour démontrer la faisabilité de son approche.
Séquence terminée
Les séquences publiées en 2001 étaient des ébauches, ce que l'on appelle alors des séquences brutes, il y restait encore un grand nombre de trous et d'imperfections. La séquence complète a été terminée en 2004 par le consortium international public.
Centres de séquençage du consortium international
- Institut Whitehead pour la recherche biomédicale, Cambridge (Massachusetts), États-Unis
- Université Washington à Saint-Louis, États-Unis
- Baylor College of Medicine, Houston, États-Unis
- DOE Joint Genome Center, Walnut Creek, États-Unis
- Centre Sanger, Hinxton, Royaume-Uni
Ces cinq centres ont produit un peu plus de 80 % de la séquence. L'ensemble du consortium international comportait onze autres centres :
- Genoscope-Centre national de séquençage, Évry, France
- Beijing Human Genome Center, Pékin, Chine
- Gesellschaft für Biotechnologische Forschung, Brunswick, Allemagne
- Genome Therapeutics Corporation, Waltham, États-Unis
- Institute for Molecular Biotechnology, Iéna, Allemagne
- Keio University, Tokyo, Japon
- Max Planck Institute for Molecular Genetics, Berlin, Allemagne
- RIKEN Genomic Sciences Center, Saitama, Japon
- Stanford DNA Sequencing and Technology Development Center, Palo Alto, États-Unis
- University of Washington Genome Center, Seattle, États-Unis
- University of Washington Multimegabase Sequencing Center, Seattle, États-Unis
Objectifs
Les objectifs du PGH original n'étaient pas seulement de séquencer l'ensemble des 3 milliards de paires de bases du génome humain avec un taux d'erreur minimal, mais aussi d'identifier tous les gènes dans cette grande quantité de données. Cette partie du projet n'est pas encore finie malgré un compte préliminaire indiquant environ 20 500 gènes dans le génome humain, ce qui est beaucoup moins que prévu par la plupart des scientifiques.
Accord des Bermudes
En 1995, les différents scientifiques à la tête du projet de séquençage du génome humain se retrouvent pour une réunion aux Bermudes sous l'égide du Wellcome Trust. Ils prennent deux décisions politiques majeures qui vont influencer le cours du projet. Tout d'abord, ils décident du caractère public du génome, qui est considéré comme patrimoine de l'humanité. Tout fragment de séquence déchiffré doit être immédiatement publié sur Internet. Ensuite, l'objectif de précision finale est fixé à 99,99 % soit au plus une erreur tous les 10 000 nucléotides.
Améliorations technologiques
Un autre but du PGH était de développer des méthodes plus rapides et efficaces pour le séquençage de l'ADN et l'analyse des séquences, ainsi que de transférer ces technologies à l'industrie. Entre 1989 et 2001, le débit de la technologie de séquençage s'est améliorée d'environ un facteur 100. Ceci est dû en particulier à l'utilisation de traceurs fluorescents, de lasers et de séparation par électrophorèse capillaire.
Un autre aspect critique a été l'amélioration considérable des performances des ordinateurs qui ont permis l'assemblage des dizaines de millions de fragments individuels d'ADN qui ont été décodés un par un.
Analyse du génome
La séquence de l'ADN humain est stockée dans des bases de données en libre accès sur Internet. Le Centre national des États-Unis pour l'information sur les biotechnologies (U.S. National Center for Biotechnology Information) (ainsi que des organisations sœurs en Europe et en Asie) accueille la séquence du génome dans une base de données connue sous le nom de Genbank, avec des séquences de gènes et de protéines connus et hypothétiques. D'autres organisations comme l'université de Californie à Santa Cruz et ENSEMBL présentent des données additionnelles ainsi que des notes, et mettent à la disposition des outils pour les visualiser et les rechercher. Des programmes informatiques ont été développés pour analyser la séquence, car les données brutes sont difficiles à interpréter seules.
Le processus permettant d'identifier les limites entre les gènes et d'autres caractéristiques sur la séquence d'ADN brute est appelé annotation du génome, et appartient au domaine de la bio-informatique. Alors que des experts biologistes constituent les meilleurs annotateurs, leur capacité de traitement est limitée et les programmes informatiques sont de plus en plus utilisés pour répondre aux immenses besoins de traitement de données des projets de séquençage génomique.
Diversité entre individus
Tous les humains ont des séquences de gène uniques, donc les données publiées par le PGH ne représentent pas la séquence exacte du génome individuel de chaque individu. C'est le génome combiné d'un petit nombre de donneurs anonymes. Le génome du PGH est un échafaudage pour un futur travail consistant à identifier les différences entre les individus. La plus grande partie du travail actuel pour identifier les différences entre les individus concerne des polymorphismes nucléotidiques.
Enjeux
La connaissance est importante pour la recherche fondamentale effectuée dans le domaine public mais les enjeux économiques sont tout aussi importants. L'industrie pharmaceutique espère beaucoup des développements en matière de diagnostic ou de thérapie, basés sur les données du génome. Ceci soulève toutefois le problème de l'appropriation de certaines parties de l'information génétique de l'Homme par des compagnies privées. Le séquençage du génome pose en effet la question de la brevetabilité du vivant, l'UNESCO a déclaré le que le génome humain est partie intégrante du patrimoine de l'humanité, et ne saurait donc être la propriété de quiconque.
Une séquence d'ADN en tant que telle ne peut pas être brevetée. Toutefois un procédé diagnostique ou thérapeutique utilisant un ou des gènes humains peut l'être. La société américaine Myriad genetics a ainsi obtenu un brevet sur un test de dépistage de la prédisposition au cancer du sein chez la femme, basé sur l'identification de mutations dans deux gènes humains appelés BRCA1 et BRCA2[10].
Projets subséquents
Une fois complété, le projet génome humain a été le point de départ de divers autres projets en génomique humaine. Début 2008 a démarré le projet 1 000 génomes, un projet de recherche internationale qui s'est donné pour objectif au départ de séquencer les génomes d'un millier de personnes réparties dans plusieurs groupes ethniques dans le monde. Le but premier étant d'améliorer la cartographie génétique du génome humain[11].
Parallèlement furent mis sur pied des projets de recherche nationaux impliquant la recherche en génomique mais dont le but, cette fois, est l'amélioration de la santé publique. Ces projets, parmi lesquels on retrouve le projet génome Estonie, le projet CARTaGENE et d'autres, nécessitent l'utilisation de bases de données biologiques et de biobanque.
Avec l'amélioration des technologies dans le domaine du séquençage et du traitement de données, les projets, qu'ils soient d'envergure nationale ou internationale, deviennent de plus en plus ambitieux. En 2012 a été annoncé le projet britannique 100 000 génomes. Ce projet du gouvernement britannique vise à séquencer le génome de 100 000 patients suivis par le National Health Service dans le but de mettre en relation certaines maladies dont les maladies rares, certains types communs de cancer de même que certaines maladies infectieuses avec les divers gènes susceptibles de jouer un rôle quelconque dans leur apparition et leur développement[12].
En 2013 a été annoncé le projet génome Qatar, toujours dans l'optique de faire progresser la médecine par le biais de la génomique[13]. Le programme de ce projet se donne pour objectif de séquencer les génomes de 350 000 habitants du Qatar[14].
En février 2016, le consortium GenomeAsia 100K annonce à son tour le projet 100 000 génomes asiatiques avec un objectif similaire mais en séquençant cette fois les génomes de 100 000 personnes asiatiques réparties dans au moins 19 pays dont 12 en Asie du Sud-Est et au moins 7 autres pays dans le Nord et l'Est du continent asiatique[15].
Quatre mois plus tard, en , fut annoncé le projet de synthèse du génome humain, un projet encore plus ambitieux qui consiste cette fois, non plus à lire ou décrypter le génome mais à le construire, nécessitant d'assembler par voie chimique tous les fragments (les nucléotides) qui le constituent[16].
Le champ de la génomique est cependant bien plus vaste que celui de la génomique humaine. Plusieurs équipes de recherche dans le monde travaillent à séquencer les génomes des différentes espèces qu'elles soient virales, bactériennes, végétales ou animales (voir Projet de séquençage de génomes).
Travaux portant sur des humains anciens
Une étude publiée en 2008 portant sur l'analyse de l'ADN mitochondriale obtenu à partir de fragments d'un tibia et d'un crâne d'un homme de Cro-Magnon découverts dans la grotte de Paglicci (en) en Italie (Paglicci 23 (en)) et datés de 28 000 ans a permis de mettre au jour une continuité généalogique avec les Européens d'aujourd'hui du fait que la séquence ADNmt obtenue y est encore courante en Europe[17].
En janvier 2010 une équipe a rapporté avoir séquencé 79 % du génome d'un homme d'une population pré-inuit appartenant à la culture de Saqqaq à partir de cheveux préservés dans le pergélisol dont l'âge a été évalué à environ 4 000 ans[18].
En février 2012 une autre équipe annonça avoir séquencé le génome complet d'Ötzi[19]. Le séquençage de ce génome a permis d'apporter plusieurs précisions concernant cet homme ayant vécu à une époque charnière entre le Néolithique et l'âge du bronze, le Chalcolithique (voir Ötzi - génétique).
Notes et références
- Site de la Revue pour l'histoire du CNRS.
- (en) « Finishing the euchromatic sequence of the human genome » Nature 2004;431:931-945. DOI:10.1038/nature03001.
- Main basse sur le génome par F. Dardel & R. Leblond, éditions Anne Carrière, Paris, 2008, (ISBN 2-84337-506-1).
- « Les scientifiques ciblent 2026 pour le premier génome synthétique », Transhumanisme et intelligence artificielle, (lire en ligne, consulté le )
- Jean-Gabriel Ganascia, Le mythe de la singularité : Faut-il craindre l'intelligence artificielle ?, Paris, Seuil, , 144 p. (ISBN 978-2-02-130999-7 et 2-02-130999-1)
- « Le projet Génome Humain », sur sequencage-genome.com,
- (en) R. Dulbecco « A Turning Point in Cancer Research: Sequencing the Human Genome » Science, 1986 ; 231(4742):1055-6. DOI:10.1126/science.3945817.
- (en) R. Sinsheimer, « The Santa Cruz Workshop, May 1985 », Genomics, 1989 ; 5:954.
- (en) International Human Genome Sequencing Consortium, Eric S. Lander, Lauren M. Linton, Aristides Patrinos pour l'Office of Science, US Department of Energy, Michael J. Morgan pour le Wellcome Trust et al. « Initial sequencing and analysis of the human genome. International human genome sequencing consortium », Nature, 2001 ; 409:890-921. DOI:10.1038/35057062.
- « Myriad Genetics obtient gain de cause devant l'Office européen des brevets », Le Monde, 21 novembre 2008.
- « The 1000 Genomes Project Consortium, A map of human genome variation from population-scale sequencing », Nature (2010) 467, 1061–1073.
- (en) « DNA mapping to better understand cancer, rare diseases and infectious diseases », UK Government, (consulté le ).
- About Qatar Genome Programme.
- WuXi NextCODE join Qatar Genome Project to power precision medicine development.
- « GenomeAsia 100K To Sequence 100,000 Asian Genomes », Asian Scientist (en), 18 février 2016.
- « The Genome Project–Write » Jef D. Boeke et al., Science, 2 juin 2016.
- (en) David Caramelli et col, « A 28,000 Years Old Cro-Magnon mtDNA Sequence Differs from All Potentially Contaminating Modern Sequences », PLOS ONE, (DOI 10.1371/journal.pone.0002700).
- « Ancient human genome sequence of an extinct Palaeo-Eskimo », Morten Rasmussen et al., Nature, vol. 463, pp 757-762, 11 février 2010 ».
- (en) Andreas Keller et col, « New insights into the Tyrolean Iceman's origin and phenotype as inferred by whole-genome sequencing », Nature communications, vol. 3, no 698, (DOI 10.1038/ncomms1701).
Voir aussi
Articles connexes
- Gène | Génétique | Génotype | Génome | Génomique
- Clonage
- Organisme génétiquement modifié
- Atlas of Genetics and Cytogenetics in Oncology and Haematology
- Étude d'association pangénomique
- Projet cerveau humain
- Spectrum 10K
Projets de recherche en génomique humaine
Liens externes
- Genoscope - Centre national de séquençage.
- Richard C. Lewontin, Le Rêve du génome humain, 1992.
- Barry Commoner, La déliquescence du mythe de l’ADN, 2002
- (en) ENSEMBL : accéder à la séquence du génome.
- (en) Animations résumant les méthodes et les étapes du séquençage du génome humain.
- Le programme génome humain et la médecine, une histoire française (Histrecmed 2019)
 Portail de la biologie cellulaire et moléculaire
Portail de la biologie cellulaire et moléculaire  Portail de la médecine
Portail de la médecine