Fouille du web
La fouille du Web est l'application des techniques d'exploration de données en vue de découvrir des constantes, schémas ou modèles, dans les ressources d'internet ou les données le concernant. Selon ces cibles, la fouille du web peut être divisée en trois types : la fouille de l'usage du web, la fouille du contenu du web, la fouille de la structure du web[1].
Fouille de l'usage du web

La fouille de l'usage du web (Web usage mining ou Web log mining) est le processus d'extraction d'informations utiles stockées dans les logs des serveurs web (l'historique des transactions des utilisateurs) ou bien les informations données par les intervenant du web (FAI, Panélistes, ..). En analysant ces flux de clics, on cherche à découvrir des informations sur le comportement de l'utilisateur sur internet. L'analyse de l'usage du web se développe en trois étapes distinctes[2], dont la première peut être décomposée en quatre sous-étapes[3] :
- Le prétraitement
- La mise au propre des données (Data cleaning)
- L'identification des transactions
- L'intégration des données en provenance de plusieurs sources
- La transformation
- La Modélisation des données et la recherche des motifs intéressants
- L'analyse des motifs intéressants
Ces trois étapes, à savoir le pré-traitement, la découverte des motifs, l'analyse des motifs, telles qu'elles sont décrites dans l'architecture WEBMINER[2], correspondent aux phases de préparation des données, de modélisation et d'évaluation de la méthode CRISP_DM[3].
Les fichiers Logs
La matière première de la fouille de l'usage du web est constituée des fichiers «logs». Outre les formats propriétaires, il en existe deux formats : le CLF[4] (« Common log format ») et le XLF[5] (« Extended log format »)[6].
|
|
Il existe des outils d'analyse des fichiers logs comme Webtrends, Web Analytics qui permettent d'exploiter ces fichiers[7].
Le prétraitement
- Le Data Cleaning
La mise au propre des données consiste à enlever toutes les données qui ne sont pas utiles à l'analyse. On supprime de l'ensemble des données à fouiller les références aux fichiers CSS, images, et audio, ainsi que le nombre d'octets transférés et la version des protocoles utilisés. Les Web crawlers et les Spiders ne sont pas des acteurs dont le comportement est intéressant à analyser - puisqu'ils explorent systématiquement toutes les pages d'un site - mais heureusement laissent des traces -pour les mieux éduqués d'entre eux- qui permettent de supprimer les données les concernant[8].
- L'identification des Pageview
Une Pageview[9] est l'ensemble des objets contenus dans une page et avec lesquels l'utilisateur a interagi. Cette étape consiste donc à identifier, à partir des fichiers logs, tous les évènements déclenchés par l'utilisateur (clicks, vue détaillée, ajout au panier, etc.) mettant en jeu des objets des pages du site, en essayant de reconstituer les Pageviews. Chaque Pageview est représentée par un identifiant, et contient des informations comme le type de page (page d'information, d'index, de produit, ..) et des informations sur les objets visités[10].
- L'identification du visiteur
Ce n'est pas tant l'identité de la personne physique qui est intéressant ici - ce qui poserait certainement des problèmes éthiques - mais plutôt celle du visiteur virtuel. Il est nécessaire de savoir si un visiteur revient sur un site après une première visite, par exemple, mais aussi de séparer des logs de deux visiteurs différents. Ceci se fait à l'aide de cookies déposés sur le poste du visiteur par le site, si l'utilisateur accepte de coopérer. Bien souvent les utilisateurs n'acceptent pas les cookies et on doit utiliser des méthodes heuristiques pour séparer les enregistrements issus des logs[11].
- L'identification des sessions
Il s'agit de segmenter l'activité du visiteur en différentes sessions qui correspondent à une seule visite du site. Là encore cela peut se faire soit à l'aide de cookies, soit par des méthodes heuristiques.
- La complétion du chemin de navigation
Parce que tout n'est pas mémorisé dans les logs des serveurs - comme lorsque le visiteur revient sur une page déjà vue en utilisant le bouton Retour de son navigateur qui utilise l'historique stocké sur son poste - il est nécessaire de détecter les sauts entre deux pages non contiguës et de compléter le chemin de navigation entre ces deux pages. Une manière de faire est de suivre le chemin le plus court entre les deux pages.
La modélisation des données
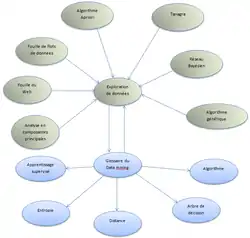
Toujours pour suivre séquentiellement le processus illustré par l'image en haut à gauche, nous allons modéliser les données et introduire les notions de matrice PFM et matrice UPM. Soient n Pageviews et m transactions composées de sous-ensembles de P telles que où les sont des pageviews de et est le poids accordé à [12],[13].






Fouille du contenu du web
La fouille du contenu du web (« Web content mining ») est le processus d'extraction d'informations contenues dans les documents stockés sur internet. Ces documents peuvent être des fichiers textes, audios, vidéos, etc. Ce type d'exploration met en œuvre des techniques de traitement automatique du langage naturel (« natural language processing (NLP) ») et de recherche d'information[14] (« Information Retrieval (IR) »). Dans ce cadre, le web sémantique est un effort d'évolution globale du Net pour une lecture facilitée des données, en particulier par les agents extérieurs aux entrepôts de données. Les techniques d'exploration de données les plus utilisées sont la classification, la segmentation (« Clustering ») et l'association. Il s'agit donc plus d'exploration descriptive que d'exploration prédictive.
Fouille de la structure du web
La fouille de la structure du web (« Web structure mining ») est le processus d'analyse des relations, inconnues à priori, entre documents ou pages stockés sur internet. Il y a plusieurs techniques de fouille : la classification, le « Clustering », le « Ranking ».
Classification
Dans la classification, il s'agit de prévoir la classe[15] d'une page internet en fonction de mots sur la page, les relations entre pages, les ancres, d'autres attributs des pages et des liens[16].
Clustering
Le but de la classification non supervisée[17] est de trouver des classes naturelles non prévues à l'avance. On peut regrouper des objets, des collections d'objets reliés entre eux, ou d'autres sous-graphes. On peut par exemple ainsi trouver des hubs et des sites miroirs.
Ranking
L'idée est qu'une page est importante si beaucoup d'autres pages pointent vers elle, et qu'elle est encore plus importante si des pages importantes pointent vers elle. Inversement, si une page pointe vers d'autres pages importantes, sa fiabilité et sa crédibilité en sont augmentées. La représentation de ces liens est inspirée par celle en vigueur dans l'étude des réseaux sociaux, et dans celle des citations de documents. La difficulté est de formaliser le concept de page «importante». Dans ce but, l'outil mathématique utilisé pour représenter la structure du web est le graphe (orienté ou non) dans lequel les sommets représentent les pages web et les arcs (arêtes) les liens entrants ou sortants. Les deux références dans l'Analyse de liens sont PageRank et HITS ; ce sont deux algorithmes qui utilisent les concepts de Centralité (« Centrality »), de Prestige (« Prestige »), de Concentrateur (« Hub ») et d'Autorité (« Authority »).
Centralité
Une page est centrale[18] (localement) si elle a plus de liens entrants ou sortants que ses voisines. Si on représente le web par un arc non orienté, le degré de centralité d'une page - noté est le nombre d'arêtes du nœud divisé par le nombre total d'arêtes possibles, soit



Si la structure (locale) du web est représentée par un graphe orienté, alors on compte seulement les arcs sortant de : .
Une autre approche de la centralité est la proximité : une page est centrale si la distance entre elle et ses voisines est courte. Si est le plus petit nombre de liens entre les pages et , alors la centralité de proximité est donnée par :




La centralité d'intermédiation (ou d'intermédiarité) mesure l'importance des pages par lesquelles on doit passer pour voyager d'une page à une autre. Si on veut aller de la page à la page , et qu'il faille passer par , alors est centrale par rapport à et , et on mesure cette importance par la formule :




Prestige
Toujours inspirée[18] par l'analyse des réseaux sociaux, la notion de prestige est une autre manière de mesurer l'importance d'une page ou d'un document. Une page prestigieuse est une page à laquelle un grand nombre d'autres pages se lient - elle reçoit un grand nombre de liens. La mesure du prestige d'une page ou d'un document est définie par son degré d'entrées :


On voit ainsi que, dans la représentation du web par un graphe orienté, le degré de centralité est mesuré par les liens sortants, alors que celui de prestige est mesuré par les liens entrants.
Le degré de prestige d'une page ne considère que les pages directement liées à . Le prestige de proximité considère l'ensemble des pages reliées directement ou indirectement à la page . Si on note cet ensemble, alors on mesure le prestige de proximité de la page par:



Si une page prestigieuse se lie à la page , par le fait, celle-ci hérite d'une partie du prestige de la première. c'est le prestige de rang ou de classe « Rank prestige », défini par :



.
On[18] remarque donc que si alors où où si , sont reliées , 0 sinon. On en déduit que est un vecteur propre de .





Concentrateur et autorité
Un concentrateur[19] (« Hub ») est une page servant d'index, de répertoire guidant les utilisateurs vers les pages d'autorité[20]. Dans la représentation du Web par un graphe orienté, un concentrateur a énormément d'arcs sortants. Typiquement, un portail wiki et une catégorie sont des concentrateurs. Une autorité[19] (« Authority ») est une page dont le contenu est de qualité ou fait autorité sur le sujet de son contenu, et ainsi les webmasters croient en son contenu et lient leurs pages à celle-ci. Une autorité a énormément de liens entrants.
Soit donc un graphe orienté, et la matrice de contiguïté définie par si , 0 sinon. Le score d'autorité et le score de concentrateur sont définis par










PageRank et HITS
PageRank est l'algorithme de « ranking » des pages internet utilisé par Google, HITS (pour « Hypertext Induced Topic Search ») est celui utilisé par Clever d'IBM. Le premier algorithme s'inspire des notions de centralité et de prestige[18], tandis que le second utilise les concepts de concentrateur et d'autorité[19].
Algorithme HITS
L'algorithme HITS construit les scores a et h par itérations successives. Si et représentent les scores à la itération, on a et avec , et , d'où l'algorithme convergeant suivant[21] :
_____________________________
Algorithme HITS: par itérations
_____________________________
Faire














Tant que et
Retourner



Robot d'indexation
Les robots d'indexation (nommés aussi « Spider » ou « Web Crawler ») sont des outils qui parcourent l'internet de façon méthodique et automatique. Ils peuvent copier des sites entiers sur le disque dur d'une machine - pour en faire un site miroir par exemple -, ils servent à vérifier les liens, à indexer, les moteurs de recherche les utilisent.
Ces araignées du Web peuvent se spécialiser dans la recherche de pages dans certaines catégories[22] préalablement définies. Un classifier[23] est construit en utilisant des pages échantillons étiquetées pour indiquer à quelles catégories elles appartiennent. Le classifier ainsi formé peut aider le « Web Crawler » à choisir les pages pouvant appartenir aux catégories auxquelles on s’intéresse. Le classifier utilisé par Soumen Chakrabarti[22] utilise la méthode naïve bayésienne.
Les « Spider » peuvent aussi rechercher des pages orientées dans des domaines, sur des sujets spécifiques. Ce sont les « Topical Crawler »[24]. L'idée est que des pages reliées contiennent des indications sur leur contenu réciproque, et d'une manière plus générale, que des pages «proches» ont des contenus similaires, soit lexicalement, soit sémantiquement.
Exemples
- Aleph Search Clear de la société aleph-networks.
Problèmes éthiques
Les problèmes éthiques sont identiques à ceux posés par l'exploration de données[25], c'est-à-dire essentiellement des problèmes liés à la vie privée, et à l'utilisation détournée (de leur objectif initial et sorties de leur contexte) des données récoltées.
Notes et références
Notes
Références
- (en) Patricio Galeas, « Patricio.Galeas.org Web site » (consulté le )
- (en) Bamshad Mobasher, « Web Usage Mining Architecture » (consulté le )
- (en)[PDF]José M. Domenech, Javier Lorenzo, « A Tool for Web Usage Mining » (consulté le )
- (en) W3C, « Common log Format » (consulté le )
- (en) W3C, « Extended log Format » (consulté le )
- Tufféry 2010, p. 640
- (en) List of Web Analytics Software
- (en)[PDF]Anália Loureço, Ronnie Alves, Orlando Belo, « When the Hunter Becomes the Prey – Tracking down Web Crawlers in Clickstreams » (consulté le )
- (en) W3C, « Definitions du W3c » (consulté le )
- (en)[PDF]Bamshad Mobasher, « Automatic personalization based on web usage mining » (consulté le ), p. 146
- (en)[PDF]Robert Cooley, Bamshad Mobasher, Jaideep Srivastava, « Data Preparation for Mining World Wide Web Browsing Patterns, paragraphe 5.2 » (consulté le )
- (en)[PDF]S. Orlando, « Web Usage Mining adapté de présentations de B. Berendt, Bamshad Mobasher et M. Spiliopoulou » (consulté le )
- (en)[PDF]Bamshad Mobasher, « Web Usage Mining chapitre 12 du livre de Bing liu, Springer, 2010 » (ISBN 978-3-642-07237-6, consulté le )
- (en)[PDF]Jaideep Srivastava, « Web Mining :Accomplishments & Future Directions » (consulté le )
- (en)[PDF]Lise Getoor, « Link Mining: A New Data Mining Challenge » (consulté le )
- (en)[PDF]Qing Lu, Lise Getoor, « link-based classification » (consulté le )
- (en)[PDF]Miguel Gomes da Costa Júnior, Zhiguo Gong, « Web Structure Mining: An Introduction » (consulté le )
- Liu 2010, p. 238-245
- (en)[PDF]Jon M. Kleinberg, « Authoritative Sources in a Hyperlinked Environment » (consulté le )
- (en)[PDF]Magdalini Eirinaki, « Web Mining : A Roadmap » (consulté le ), p. 6
- Liu 2010, p. 257-258
- (en)[PDF]Soumen Chakrabarti, Byron E. Dom, David Gibson, Jon Kleinberg, Ravi Kumar, Prabhakar Raghavan, Sridhar Rajagopalan, Andrew Tomkins, « Mining the Link Structure of the World Wide Web » (consulté le )
- Liu 2010, p. 288-293
- (en)[PDF]P. Srinivasan, F. Menczer, G. Pant, « A General Evaluation Framework for Topical Crawlers » (consulté le )
- (en)[PDF]Lita van Wel, Lambèr Royakkers, « Ethical issues in web data mining » (consulté le )
Voir aussi
Articles connexes
Bibliographie
- Bing Liu, Web Data Mining, Berlin, Springer, , 532 p. (ISBN 978-3-642-07237-6).

- Stéphane Tufféry, Data Mining et statistique décisionnelle : l'intelligence des données, Paris, éditions Technip, , 705 p. (ISBN 978-2-7108-0946-3, lire en ligne)
Liens externes
 Portail de l’informatique
Portail de l’informatique  Portail des probabilités et de la statistique
Portail des probabilités et de la statistique  Portail des données
Portail des données