Estimation stochastique en mécanique des fluides
L'estimation stochastique est une méthode qui permet de reconstruire le champ complet d'un écoulement: à partir de données résolues spatialement (par exemple champ PIV[1]) et de données résolues en temps (par exemple signal de pression instationnaire), on estime le champ de vitesse à tout instant et en tout point. Pour cela, on utilise une régression multi linéaire, pouvant utiliser l'apprentissage automatique[2].
Contexte
Pour comprendre un écoulement turbulent en mécanique des fluides, il y a deux stratégies possibles:
- Effectuer des visualisations expérimentales. Par exemple, une expérience en soufflerie permet de visualiser le champ de vitesse (vélocimétrie par image de particules PIV) et de récupérer certaines grandeurs d'intérêts (signaux de vitesse ou de pression).
- Effectuer un calcul numérique. L'objectif est de résoudre les équations de Navier-Stokes en choisissant une modélisation plus ou moins fine de la turbulence.
Chacune des approches présente des avantages et des inconvénients:
- L'approche expérimentale présente l'avantage d'être le reflet de la réalité et de ne pas reposer sur un modèle mathématique. Toutefois, il est difficile de caractériser entièrement l'écoulement. Par exemple, la PIV permet uniquement d'observer l'écoulement sur certaines fenêtres d'observation avec une résolution en temps dépendant de la cadence du LASER[1]. Un autre exemple concerne l'acquisition de signaux temporels: en plus d'être limité à des mesures ponctuelles, les méthodes de mesures peuvent être intrusives (fil chaud).
- L'approche numérique présente l'avantage d'être flexible: une fois le champ calculé, l'information peut-être visualisée n'importe où. Toutefois, les résultats dépendent fortement du degré de modélisation retenue. Dans le cas d'un calcul RANS, presque toute la turbulence est modélisée, au détriment d'une bonne résolution spatiale et temporelle. Dans le cas d'une DNS, toute la turbulence est résolue, d'un point de vue spatial et temporel, mais cela nécessite un très grand coût ordinateur[3].
De façon générale, il est donc difficile de récupérer à la fois l'information spatiale et l'information temporelle d'un écoulement.
Origine de la méthode
L'estimation stochastique a été introduite par Adrian en 1975[4]. Dans son article, il propose d'approximer le champ de vitesse d'un écoulement par une moyenne d'ensemble conditionnée par un ensemble de réalisations ponctuelles. Ces réalisations peuvent être homogènes au champ de vitesse ou non. En développant la moyenne conditionnelle sous la forme d'une série de Taylor, le champ est approximé par une combinaison polynomiale des réalisations dans le champ.
Si l'estimation stochastique est le nom particulier donné dans le cadre de la mécanique des fluides, la méthode est bien plus générale et fait partie de la classe des régressions en apprentissage automatique.
Applications dans la littérature scientifique
L'estimation stochastique a été utilisée pour étudier de la turbulence isotrope[5], des couches limites turbulentes[6], des jets axisymmétriques[7], des marches descendante[8], des cavités ouvertes[9] ou pour des stratégies de contrôle[10].
Exemple classique de reconstruction
Déroulé de l'expérience
Soit une expérience organisée en deux campagnes d'essais.
- Dans une première campagne, le dispositif expérimental permet de récupérer le champ de vitesse résolu en espace à des temps donnés. Il permet aussi de récupérer le champ de pression résolu en temps à des positions données. C'est la campagne d’entraînement
- Dans la deuxième campagne, le dispositif expérimental permet uniquement de récupérer le champ de pression résolu en temps à des positions données. C'est la campagne de validation
Hypothèse
Pour l'étude, les données sont supposées fluctuantes c'est-à-dire de moyenne temporelle nulle. Par hypothèse d'ergodicité (le nombre d'échantillons considérés est représentatif du processus continu),cela équivaut à une moyenne d'ensemble nulle. Cette hypothèse n'est pas nécessaire mais est souvent faite pour ne pas avoir de champ moyen dans à prendre en compte dans le développement de Taylor.
Objectifs
L'objectif est d'estimer le champ complet (i.e. résolu en temps et en espace) à partir uniquement des données résolues en temps (ici les mesures de pression). Ces données instationnaires sont appelées événements.
Les estimations portent des noms spécifiques selon la provenance des événements:
- Si l'estimation utilise les événements de la campagne d'entraînement, on utilise le terme de reconstruction. L'estimation porte sur le champ de vitesse complet de la campagne d'entraînement.
- Si l'estimation utilise les événements de la campagne de validation, on utilise le terme de prédiction. L'estimation porte sur le champ de vitesse complet de la campagne de validation.
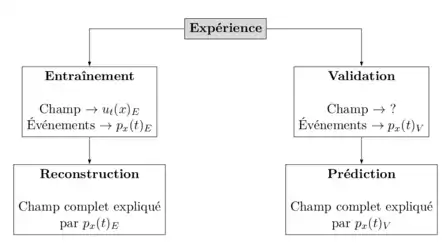
Méthode
L'estimation stochastique consiste à expliquer le champ de vitesse complet d'une campagne par les événements d'une même campagne. Il s'agit ni plus ni moins d'une régression dont les coefficients sont déterminés par moindres carrés sur les données d'entraînement. Le processus est le suivant:
- Apprentissage. Comment les événements de la campagne d'entraînement expliquent les clichés PIV de la campagne d'entraînement?
- Corrélations. Calcul des corrélations (moments d'ordre plus ou moins élevé) entre les données d'entraînement prises aux temps PIV.
- Moindres carrés. Calcul des coefficients de la régression
- Estimation stochastique. Reconstruction ou prédiction en utilisant la régression
Principe mathématique
Dans la suite, l'événement désigne aussi bien que avec décrivant les capteurs retenus placés en . Par ailleurs, on suppose connaître échantillons pour chaque grandeur.







L'idée de l'estimation stochastique est d'approximer le champ complet par une moyenne conditionnelle entre le champ complet réel et les événements de pression[4]. Cette estimation s'écrit donc:

Par développement de Taylor autour de 0 (car les grandeurs sont fluctuantes), on peut écrire à l'ordre 1 (LSE pour Linear Stochastic Estimation) et à l'ordre 2 (QSE pour Quadratic Stochastic Estimation)[11]:


Les coefficients de la régression sont les dans le cas linéaire et dans le cas quadratique. Ils sont calculés par moindres carrés c'est-à-dire qu'ils sont solution du problème de minimisation: .



La solution générale est donnée par[12]:

Avec:
- le vecteur des coefficients de régression.
- le vecteur vitesse.
- une matrice qui contient les événements. Dans le cas quadratique, le produit des événements est considéré comme un nouvel événement.



À noter que la solution s'écrit également avec la pseudo-inverse de .


Illustration
La figure suivante illustre le principe d'estimation stochastique en ne considérant qu'un seul capteur de pression.
- Le premier encadré correspond à l'expérience. Les carrés bleus sont les champs de vitesse résolus en espace à des temps précis (temps PIV) tandis que la flèche correspond au signal de pression récupéré en un point de l'écoulement mais résolu en temps.
- Le second encadré correspond à de la reconstruction. L'objectif est de calculer les carrés rouges i.e. les champs de vitesse résolus en espace à des temps autres que les temps PIV. Ces champs de vitesse sont entièrement déterminés par le signal de pression de l'expérience, pourvu que les corrélations entre les carrés bleus et le signal aient été calculés.
- Le troisième encadré correspond à de la prédiction. On utilise les corrélations calculés avec les données du premier encadré mais cette fois, les carrés verts seront calculés uniquement à partir du signal de validation.

Références
- Adrian, R. J. (Ronald J.),, Particle Image Velocimetry, Cambridge University Press, 2011, ©2011, 558 p. (ISBN 978-0-521-44008-0 et 0521440084, OCLC 676923150, lire en ligne)
- Lemberger, Pirmin., Morel, Médéric., Raffaëlli, Jean-Luc. et Delattre, Michel., Big data et machine learning : manuel du data scientist, Paris, Dunod, dl 2015, cop. 2015, 219 p. (ISBN 978-2-10-072074-3 et 2100720740, OCLC 904592655, lire en ligne)
- Wilcox, David C., Turbulence modeling for CFD : CD-ROM, DCW Industries, , 522 p. (ISBN 978-1-928729-08-2 et 1928729088, OCLC 77138203, lire en ligne)
- (en) Adrian R.J., « On the role of conditional averages in turbulence theory. », University of Missouri--Rolla,
- (en) Ronald J. Adrian, « Conditional eddies in isotropic turbulence », Physics of Fluids,
- (en) Guezennec, « Stochastic estimation of coherent structures in turbulent boundary layers », Physics of Fluids,
- (en) J. P. Bonnet, « Stochastic estimation and proper orthogonal decomposition: Complementary techniques for identifying structures », Experiments in Fluids,
- (en) Daniel R. Cole, « Applications of stochastic estimation in the axisymmetric sudden expansion », Physics of Fluids,
- (en) Nathan E. Murray, « Estimation of the Flowfield from surface Pressure Measurements in an Open Cavity », AIAA Journal,
- (en) Jeremy T. Pinier, « Proportional Closed-Loop Feedback Control of Flow Separation », AIAA Journal,
- (en) Ronald J. Adrian, « Stochastic estimation of conditional structure: a review », Applied Scientific Research, vol. 53, no 3, , p. 291–303 (ISSN 1573-1987, DOI 10.1007/BF00849106, lire en ligne, consulté le )
- « Introduction à la régression multiple »
 Portail de la physique
Portail de la physique