Assimilation de données
En météorologie, l'assimilation de données est le procédé qui consiste à corriger, à l'aide d'observations, l'état de l'atmosphère d'une prévision météorologique.
Principe
La prévision numérique de l'évolution de l'atmosphère dépend grandement des conditions initiales qui lui sont fournies. Or il est difficile de déterminer, à un instant donné, l'état de l'atmosphère, c’est-à-dire l’ensemble des variables atmosphériques (pression, température, humidité, etc.) sur l’ensemble du volume, avec une bonne résolution et une bonne précision.
Les seules informations disponibles à un moment donné sont les observations météorologiques de différentes natures (radio-sondages, stations météorologiques, bouées océaniques, etc.). Mais ces informations ne sont pas suffisantes. En effet le modèle atmosphérique requiert de l'ordre de valeurs (pour tous les champs physiques considérés, en tous les points du modèle). Or les observations sont de l'ordre de . Une simple interpolation ne suffit pas dans ces conditions. On a alors recours à une méthode appelée "assimilation de données".


L'assimilation de données est une méthode "prédicteur/correction". Une prévision, calculée au pas de temps précédent et valable à l'instant considéré, est utilisée comme prédicteur. Les observations disponibles permettent de corriger cette ébauche pour estimer au mieux l'état réel de l'atmosphère.
Exemple simple (hors météorologie)
On souhaite connaître la température dans une pièce disposant d'une source de chaleur ponctuelle de 20 °C.

La source est arrêtée. Au temps , il fait 15 °C dans toute la pièce. La source de chaleur s'active, et l'observateur sort de la pièce.

La prévision consiste à dire qu'il fera, au bout d'un certain temps 20 °C au point d'application de la source, puis de plus en plus froid en s'en écartant : il s'agit ici de la prévision valable dans l'ensemble de la pièce.

L'observateur revient 3 heures après. Un thermomètre fixé dans la pièce indique 17 °C dans un point assez éloigné de la source où il est supposé en faire 18 °C. L'assimilation part de l'idée que cette information va corriger la prévision précédente. Par exemple en supposant que localement, une aération fait baisser cette température. Ou encore que la décroissance de la température au-delà de la source de chaleur se fait plus rapidement. Nous obtenons ainsi une analyse de la situation.
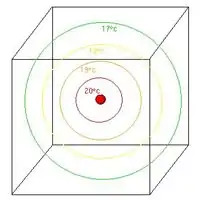 fig.2 Prévision de la température. |
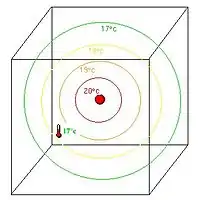 fig.3 Une observation indiquant 17 °C. |
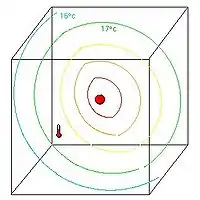 fig.4 Correction locale. |
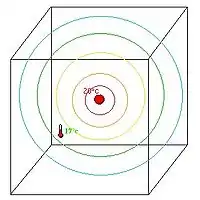 fig.5 Correction globale. |
Le thermomètre n'est pas très précis, par exemple une erreur de +/- 0,5 °C. La connaissance de l'erreur d'observation due au manque de précision du thermomètre réduira l'impact de cette observation lors de notre assimilation. La connaissance de l'erreur de prévision (par exemple le manque d'information sur l'isolation exacte de la pièce), va jouer dans l'autre sens. Ces différents aspects seront exposés plus loin après la formulation mathématique.
Formulation mathématique
On veut connaître l'état d'un système qui n'évolue pas dans le temps représenté par un vecteur (souvent de dimension infinie). On échantillonne spatialement à l'aide d'un opérateur qui donne le vecteur de dimension .




On fait des mesures à certains endroits sur le système. On rassemblera ces informations dans le vecteur des observations de dimension . On lui associe un vecteur d'erreur d'observation dont on ne connait, en général, que l’espérance et la variance (ou plutôt leur estimation). On peut donc construire une matrice de covariance . On compare les observations à l'état réel du système à l'aide de la fonction d'observation (qui peut être linéaire ou non):






On utilise un modèle qui nous permet d'évaluer l'état du système de manière approchée. L'estimation de par le modèle est appelée vecteur d'ébauche noté . On associe ce vecteur avec une erreur et une matrice de covariance .



L'assimilation de données consiste à donner la meilleure approximation de l'état du système à partir de l'ébauche et des observations. Le vecteur résultant est le vecteur d'analyse . On cherche aussi la matrice de covariance d'erreur .


Première solution du problème
On considère dans un premier temps l'opérateur linéaire quitte à le linéariser s'il ne l'est pas. On cherche à minimiser l'erreur commise a posteriori de en minimisant .


On cherche la solution à l'aide d'une régression linéaire (voir Méthode des moindres carrés), appelée un Ansatz[1] en assimilation de données :

On suppose que les erreurs d'observation et de l'ébauche sont sans biais, quitte à retrancher le biais s'il existe. Si nous voulons que l'erreur de l'analyse reste sans biais, on a . On obtient alors :


où s'appelle le vecteur innovation

.

On cherche maintenant le gain optimal pour minimiser . L'analyse BLUE Best linear unbiased estimator permet d'obtenir le gain optimal

.

Système dépendant du temps
Supposons maintenant que l'état du système évolue dans le temps. On souhaite effectuer une succession d'analyses à tous les instants possibles. Nous avons des prévisions provenant du modèle aux dates et des observations à plusieurs dates dont . On note le vecteur de prévision (correspondant à dans le paragraphe précédent), le vecteur des observations et le vecteur d'analyse .





Les différentes méthodes de résolution
Les méthodes séquentielles
On peut d'abord résoudre ce problème à l'aide de méthode dites séquentielles. Dans ce type de méthode, il y a d'abord l'étape de prévision où l'on obtient , puis l'étape d'analyse où l'on combine l'information des observations et de la prévision pour avoir . On peut résumer ce problème sous le jeu d'équation suivant :

Ici est l'erreur modèle du passage au temps à du au modèle. est l'erreur de prévision accumulée lors de la succession des étapes. On associe à la matrice de covariance .




Le filtre de Kalman avec les notations de l'assimilation de données
On suppose pour ce filtre que les opérateurs et sont linéaires et que les erreurs d'observation et de prévision sont sans biais. On peut démontrer que les erreurs d'analyse sont alors sans biais.


Voici l'algorithme du filtre de Kalman dans le cadre de l'assimilation de données.
1. Initialisation
Estimer
Estimer la matrice de covariance
2. Boucle sur les différentes dates d'observation
a. Analyse
Calcul du gain avec la méthode BLUE
Estimation de
Calcul de la matrice de covariance
b. Prévision
Calculer la nouvelle prévision
Calculer la matrice de covariance











Le filtre de Kalman étendu
Le filtre de Kalman étendu reprend exactement le même principe que le filtre de Kalman. Il est juste nécessaire de linéariser les opérateurs et autour de l'état . On applique ensuite exactement le même algorithme que précédemment. Ce filtre fonctionne bien si l'échantillonnage des observations est assez élevé ou si les non linéarités du modèle ne sont pas trop grandes.

Le filtre particulaire
Dans ce cas, nous ne cherchons pas les matrices et mais la densité de probabilité de . Il faut d'abord poser ce problème sous cette forme appelée filtre bayésien.
On notera , l'ensemble des observations passées entre les instants et . On considère maintenant que l'opérateur d'observation n'est pas nécessairement linéaire et dépend aussi de l'erreur . A priori, nous connaissons et . En réalité, correspond à .






L'idée du filtre particulaire est de calculer les distributions de probabilité à l'aide d'un échantillonnage de l'espace de l'état du système. On crée des particules à partir des points choisis pour l’échantillonnage et leur état va évoluer à l'aide du modèle.
Voici l'algorithme du filtre particulaire bootstrap.
1. Initialisation
Échantillonner à l'aide de particules
Assigner un poids identique aux différentes particules
2. Boucle sur les différentes dates d'observation
a. Prévision
Propager les particules à l'aide du modèle
b. Analyse
Calculer les nouveaux poids des particules
Normaliser les poids pour obtenir la distribution de
c. Re-échantillonnage
Le filtre va privilégier une particule si on ne le ré-échantillonne pas (phénomène appelé dégénérescence).
On ré-échantillonne avec des poids identiques.






En général cette méthode est efficace pour des modèles fortement non linéaires mais si la dimension de l'état du système est trop grande alors le filtre ne fonctionne plus (en général plus grand que 8). On peut aussi trouver des variantes où l'on ré-échantillonne seulement les particules qui ont un poids trop élevé.
Le filtre de Kalman d'ensemble
Le filtre d'ensemble utilise lui aussi la notion de particule mais il ne générera que les moments d'ordre 1 et 2 de l'analyse. L'analyse est la même que le filtre de Kalman mais des particules sont créées pour propager les erreurs dues à l'observation.
Ce filtre fonctionne avec un modèle non linéaire mais il faut linéariser la fonction d'observation pour calculer le gain.
Voici l'algorithme:
1. Initialisation
Estimer
Estimer la matrice de covariance
Créer N particules estimant à l'aide la matrice de covariance
2. Boucle sur les différentes dates d'observation
a. Observation
Créer un jeu d'observation de biais nulle autour de la valeur observée
Calculer la matrice de covariance associée
b. Analyse
Calcul du gain avec la méthode BLUE
Ici linéarisé
Estimation de
Ici non linéarisé
Calculer la moyenne
Calcul de la matrice de covariance
c. Prévision
Calculer les nouvelles prévisions
Calculer la matrice de covariance








Filtres réduits
Il est possible d'associer des filtres pour réduire la dimensionnalité du système. Il existe plusieurs filtres comme le filtre RRSQRT[2], SEEK[3] ou encore SEIK[4].
Les méthodes d'analyse variationnelle
La méthode d'assimilation variationnelle est utilisée pour obtenir les valeurs aux points de grille du modèle les plus près de la réalité. Elle implique de trouver un ensemble de points du modèle dont la description par une fonction se rapproche le plus des valeurs aux points observés sans introduire d'instabilité dans le modèle numérique. Elle consiste donc à chercher l'état le plus vraisemblable à partir des connaissances disponibles sur les lois de probabilités des erreurs d'observation.
Ceci se fait en minimisant par itération la fonction coût, le plus souvent la somme des moindres carrés des déviations entre l'analyse et l'observation pondérée par la qualité de ces dernières. Ce processus peut être fait en 3 ou 4 dimensions.
Assimilation à 3 dimensions (3D-Var)
La méthode à trois dimensions, communément appelée 3D-Var, se fait à un pas de temps fixe dans les trois dimensions cartésiennes X, Y et Z. Comme pour le filtre de Kalman, le 3D-Var consiste à minimiser la distance au sens des moindres carrés entre l'état estimé et les différentes sources d'informations telles que la prévision précédente et les observations au temps initial. Le nouvel état analysé est, en général, utilisé comme point de départ de la prévision suivante.
La fonction coût s'exprime comme[5] :

Où :
- est la matrice de covariance de l'erreur de bruit de fond ;
- est la matrice de covariance de l'erreur d'observation.


Assimilation à 4 dimensions (4D-Var)
À quatre dimensions, l'analyse se fait à plusieurs pas temps entre le temps initial et un temps futur de prévision. Il s'agit donc d'une extension de la méthode 3D-Var qui ne vise pas à obtenir l'état optimal à un instant donné, mais la trajectoire optimale sur une fenêtre de temps donnée. Les observations sont donc prises en compte aussi bien dans leur distribution spatiale que temporelle et le 4D-Var propage donc l'information apportée par les observations à l'instant initial de la fenêtre d'assimilation[6].
Cette amélioration du 3D-Var permet d'ajouter la connaissance de l'évolution du système comme information pour l'analyse. Bien qu'elle demande une beaucoup plus grande puissance de calcul que la méthode précédente, elle est devenue la plus utilisée dans les systèmes de prévision opérationnels atmosphériques du CEPMMT en 1997, de Météo-France en 2000, et de nombreux autres centres météorologiques internationaux[6].
Combinaison des méthodes variationnelles et séquentielles
Les techniques variationnelles sont plus efficaces pour trouver une bonne analyse et les techniques séquentielles permettent une caractérisation des erreurs. Ainsi, de nouvelles méthodes sont inventées pour combiner ces deux aspects.
Notes et références
- (en) « Cours Marc Bocquet »
- A. J. Segers Data assimilation in atmospheric chemistry models using Kalman filtering
- (en) D. T. Pham, « A singular evolutive extended Kalman filter for data assimilation in oceanography », J. Marine Systems, , p. 323-340
- (en) D. T. Pham, « Stochastic methods for sequential data assimilation in strongly non-linear systems », Monthly weather review, , p. 1194-1207
- « 3D-Var », Méthode variationnelle, Centre européen de recherche et de formation avancée en calcul scientifique (consulté le ).
- « 4D-Var », Méthode variationnelle, Centre européen de recherche et de formation avancée en calcul scientifique (consulté le ).
Lien externe
- Marc Bocquet, , notes de cours de l'ENSTA et l'École nationale des ponts et chaussées.
 Portail de la météorologie
Portail de la météorologie