Vers les systèmes monopuces (SoC)
Si l’on désire aller plus loin dans l'intégration de systèmes dans un FPGA, il faut commencer à penser aux microprocesseurs et aux micro contrôleurs. Dans un FPGA vous pouvez insérer un micro contrôleur existant (je veux dire disponible sur le marché en temps que circuit) ou concevoir un processeur complètement dédié.
Nous allons commencer par une architecture dédiée et très simple qui comporte un jeu d'instructions réduit (quatre instructions) mais conçu de manière très intelligente. Il est en effet assez rare de rencontrer un système de 4 instructions capable de réaliser un programme qui réalise autre chose qu'une addition et c’est bien le cas ici, comme nous le montrerons avec un calcul de PGCD.
Étude du miniprocesseur embarqué "MCPU"
Tim Boescke, cpldcpu@opencores.org a publié en 2001-2004 un miniprocesseur (appelé MCPU par la suite) de quatre instructions (MCPU chez opencores) destiné à tenir dans un CPLD. Ses quatre instructions (on parle de jeu d'instructions) sont les suivantes :
| Opcode (binaire) | Mnemonic | Description |
|---|---|---|
00AA AAAA | NOR | Accu = Accu NOR mem[AA AAAA] |
01AA AAAA | ADD | Accu = Accu + mem[AA AAAA] + MAJ retenue |
10AA AAAA | STA | mem[AA AAAA] = Accumulateur |
11DD DDDD | JCC | Positionne le PC à DD DDDD quand retenue = 0 + RAZ retenue |
Évidemment on a utilisé dans ce tableau
- RAZ pour Remise à zéro
- MAJ pour mise à jour
- Accu pour Accumulateur
- PC pour compteur ordinal
Seul l’adressage direct est implanté dans cette architecture et c’est bien suffisant pour un début.
Ce qui fait le grand intérêt de cette architecture c’est qu’il est possible de définir par dessus ces instructions des macros instructions de manière assez subtile :
| Macro | Assembleur | Description |
|---|---|---|
| CLR | NOR allone | Accu = 0 (allone doit contenir 0xFF) |
| LDA mem | NOR allone, ADD mem | Accu = mem[AA AAAA], allone doit contenir 0xFF |
| NOT | NOR zero | inverse le contenu de l'accumulateur, zero doit contenir 0x00 |
| JMP dest | JCC dest, JCC dest | saut inconditionnel à dest |
| JCS dest | JCC *+2, JCC dest | saut si retenue |
| SUB mem | NOR zero, ADD mem, ADD one | Accu = mem[AA AAAA] - Accu, one doit contenir 0x01 |
| MOV src,dest | NOR allone, ADD src, STA dest | déplacement de la mémoire src vers dest |
Vous disposez à ce point de 11 instructions (4 instructions d'origine + 7 macros), ce qui est suffisant pour un calcul de PGCD (voir aussi le chapitre précédent pour le PGCD).
La documentation originale de Tim Boescke mentionne pour l'instruction "SUB mem" la réalisation de Accu=Accu-mem[AA AAAA]. Nous pensons au contraire qu'elle réalise Accu=mem[AA AAAA] - Accu ce qui n'est absolument pas habituel. La sémantique de cette instruction risque de perturber l'utilisateur de cette architecture.
Si vous voulez respecter la sémantique habituelle vous devriez faire plutôt :
SUB mem = NOR zero, ADD one, ADD mem, NOR zero, ADD one
Transformer notre FSMD en programme
Dans cette section, nous désirons reprendre un FSMD qui calculait un PGCD et le transformer en programme.
Il est toujours possible de transformer un FSMD ou un graphe d'état en un ensemble d'instructions. Il faudra ensuite imaginer une architecture capable de réaliser un tel programme.
Nous ne sommes pas tout à fait dans cette situation puisque notre architecture existe, nous venons tout juste de la présenter. Pour notre exemple de calcul de PGCD, cela peut se faire avec un programme en assembleur du style (sans utiliser les macros) :
;********* programme non testé ******
;USE "cpu3.inc"
start:
NOR allone
ADD allone ;LDA allone
ADD b
JCC end ; fini si B=0
Bdif0:
NOR allone
ADD a
STA t ;MOV a,t ; t <- A
;****** T<B ?
rem:
NOR allone ;CLR
LDA b
ADD one ;Akku = - b
ADD t ;Akku = t - b
;Carry set when akku >= 0
JCC Tinfb
STA t ;t <- t-b
JCC rem
JCC rem ;JMP rem
Tinfb:
NOR allone
ADD b
STA a ;MOV b,a a <- b
NOR allone
ADD t
STA b ;MOV t,b b <- t
JCC start
JCC start ;JMP start
end:
JCC end
JCC end ;JMP end
a:
DCB (126)
b:
DCB (124)
t:
DCB (0)
allone:
DCB (255)
zero:
DCB (0)
one:
DCB (1)
Ce programme est facile à comprendre pour qui a un peu d'expérience car il reprend la technique utilisée dans l' unité de contrôle du chapitre précédent (nous avons modifié le programme original de Tim Boescke pour cela). Les données "allone", "zero" et "one" ainsi que les macros peuvent être définies dans un fichier à inclure comme dans le programme original.
Transformer notre programme en ...
Quand on a l'habitude de faire fonctionner des micro contrôleurs on sait qu’il suffit de compiler un programme en fichier hex qu'un programmateur permettra d'envoyer à une EPROM. Mais ici, comment et où va finir notre programme ? En général on dispose d'un programme convertisseur qui permet de transformer notre fichier hex en VHDL. Ce VHDL finira dans des blocs logiques ou dans de la RAM (il y en a dans tout FPGA moderne).
Ainsi mettre notre MCPU dans un FPGA ou dans un CPLD (comme initialement prévu par son concepteur) est un peu différent : dans le CPLD il est très probable que le programme soit externe (EPROM externe par exemple), alors que dans un FPGA on s'arrangera pour laisser le programme en interne dans une RAM/ROM prévue à cet effet.
Puisqu’il n'y a pas de standard pour la description de RAM/ROM en VHDL, les différents fabricants de FPGA laissent au style de programmation VHDL le soin de définir ce qui sera finalement utilisé dans le FPGA en lieu et place des RAM/ROM. C'est pratique, mais cela a un inconvénient : celui d’être dépendant du fabricant.
Liens internes
- RAM et FPGA d'un autre projet aborde le problème des RAMs dans un FPGA.
Exercice 1
Le programme VHDL de description original de Tim Boescke pour décrire son architecture est tellement simple que nous le donnons maintenant complètement :
-- Minimal 8 Bit CPU
-- rev 15102001
-- 01−02/2001 Tim Boescke
-- 10 /2001 slight changes for proper simulation.
-- t.boescke@tuhh.de
library ieee;
use ieee.std_logic_1164.all;
use ieee.std_logic_unsigned.all;
entity CPU8BIT2 is
port ( data: inout std_logic_vector(7 downto 0);
adress: out std_logic_vector(5 downto 0);
oe: out std_logic;
we: out std_logic; -- Asynchronous memory interface
rst: in std_logic;
clk: in std_logic);
end;
architecture CPU_ARCH of CPU8BIT2 is
signal akku: std_logic_vector(8 downto 0); -- akku(8) is carry !
signal adreg: std_logic_vector(5 downto 0);
signal pc: std_logic_vector(5 downto 0);
signal states: std_logic_vector(2 downto 0);
begin
process(clk,rst)
begin
if (rst = '0') then
adreg <= (others => '0');-- start execution at memory location 0
states <= "000";
akku <= (others => '0');
pc <= (others => '0');
elsif rising_edge(clk) then
-- PC / Adress path
if (states = "000") then
pc <= adreg + 1;
adreg <= data(5 downto 0);
else
adreg <= pc;
end if;
-- ALU / Data Path
case states is
when "010" => akku <= ("0" & akku(7 downto 0)) + ("0" & data); -- add
when "011" => akku(7 downto 0) <= akku(7 downto 0) nor data; -- nor
when "101" => akku(8) <= '0';-- branch not taken, clear carry
when others => null; -- instr. fetch, jcc taken (000), sta (001)
end case;
-- State machine
if (states /= "000") then states <= "000"; -- fetch next opcode
elsif (data(7 downto 6) = "11" and akku(8)='1') then states <= "101"; -- branch not taken
else states <= "0" & not data(7 downto 6);-- execute instruction
end if;
end if;
end process;
-- output
adress <= adreg;
data <= "ZZZZZZZZ" when states /= "001" else akku(7 downto 0);
oe <= '1' when (clk='1' or states = "001" or rst='0' or states = "101") else '0'; -- no memory access during reset and
we <= '1' when (clk='1' or states /= "001" or rst='0') else '0'; -- state "101" (branch not taken)
end CPU_ARCH;
Cette architecture utilise une seule mémoire pour les données et le programme : ils peuvent donc être mélangés dans une même mémoire. Répondre aux questions suivantes :
- Le compteur programme destiné à chercher les instructions en mémoire programme est sur 6 bits. Quelle est la taille de la mémoire programme sachant que, comme le montre le tableau des instructions, les opcodes sont sur 8 bits ?
- Dans le tableau ci-dessus, AAAAAA désigne une adresse mémoire en binaire sur 6 bits tandis que DDDDDD désigne une destination sur aussi 6 bits. Quelle est la taille de la mémoire donnée adressable ?
- L'astuce de cette architecture est qu’il est possible de définir par dessus ces instructions des macros instructions (ensemble d'une ou plusieurs instructions) de manière assez subtile. Pouvez-vous donner l'opcode de "JMP dst" ?
- Le signal "Akku" représente le registre accumulateur, là où se trouve le résultat de toute exécution d'instruction. Pourquoi est-il sur 9 bits au lieu de 8 ?
- La machine d'états qui séquence le processeur est décrite après le commentaire "State machine" sur 3 lignes. Son état est décrit par le signal "state". Combien d'états (au maximum) peut comporter cette machine ?
- Quel est l'état futur de l'état "001" ?
- Chercher les équations de récurrences de cette machine d'états.
- Assembler manuellement le programme du PGCD, puis transformer manuellement le binaire en mémoire ROM VHDL. Insérer cette ROM avec le processeur et tester à l'aide d'une simulation.
- la donnée de 8 bits dans la question sert à connaitre la largeur de la mémoire. Son nombre de ligne est donné par contre par 2^6 = 64. Cette mémoire contient donc 64 octets.
- même réponse qu’à la question précédente. Heureusement puisque les deux mémoires sont confondues.
- JMP dst = JCC dst, JCC dst Donc l'opcode est 11DDDDDD suivi de 11DDDDDD où DDDDDD représente l'adresse de dst.
- Akku est sur 9 bits car comme le dit le commentaire le neuvième bit représente la retenue.
- state est sur 3 bits peut donc contenir 8 valeurs différentes => 8 états maxi.
- L'état futur de tout état est "000" dès qu’il diffère de "000" : voir le code VHDL
- Le tableau état présent / état futur peut s'écrire à partir du code :
État present Opcode(7) Opcode(6) Akku(8) État futur
000 1 1 1 101 pas de saut car retenue à 1
000 1 1 0 000 saut car retenue à 0
000 0 1 X 010
000 1 0 X 001
000 0 0 X 011
001 X X X 000
010 X X X 000
011 X X X 000
100 X X X 000
101 X X X 000
110 X X X 000
111 X X X 000
Il permet d'écrire facilement les équations de récurrences.
Nous allons nous intéresser maintenant à la réalisation de ce processeur en architecture Harvard, c'est-à-dire en séparant la mémoire donnée de la mémoire programme. L'intérêt est de réaliser un processeur pouvant exécuter une instruction par période d'horloge, mais sa compréhension nécessite un certain recul sur l'architecture des chemins de données dans les processeurs.
Autre code source de MCPU
Un membre du forum stackoverflow a écrit une version un peu plus lisible de MCPU en VHDL :
library ieee;
use ieee.std_logic_1164.all;
use ieee.std_logic_unsigned.all;
entity mcpu is
port (
data_bus: inout std_logic_vector(7 downto 0);
address: out std_logic_vector(5 downto 0);
n_oe: out std_logic;
-- Asynchronous memory interface
n_we: out std_logic;
n_reset: in std_logic;
clock: in std_logic
);
end;
architecture refactored of mcpu is
signal accumulator: std_logic_vector(8 downto 0);
alias carry is accumulator(8);
alias result is accumulator(7 downto 0);
alias opcode is data_bus(7 downto 6);
signal address_register: std_logic_vector(5 downto 0);
signal pc: std_logic_vector(5 downto 0);
signal states: std_logic_vector(2 downto 0);
type cpu_state_type is (FETCH, WRITE, ALU_ADD, ALU_NOR, BRANCH_NOT_TAKEN);
signal cpu_state: cpu_state_type;
type state_encoding_type is array (cpu_state_type) of std_logic_vector(2 downto 0);
constant STATE_ENCODING: state_encoding_type := (
FETCH => "000",
WRITE => "001",
ALU_ADD => "010",
ALU_NOR => "011",
BRANCH_NOT_TAKEN => "101"
);
begin
process (clock, n_reset)
begin
if not n_reset then
-- start execution at memory location 0
address_register <= (others => '0');
states <= "000";
cpu_state <= FETCH;
accumulator <= (others => '0');
pc <= (others => '0');
elsif rising_edge(clock) then
-- PC / Adress path
if cpu_state = FETCH then
pc <= address_register + 1;
address_register <= data_bus(5 downto 0);
else
address_register <= pc;
end if;
-- ALU / Data Path
case cpu_state is
when ALU_ADD =>
accumulator <= ('0' & result) + ('0' & data_bus);
when ALU_NOR =>
result <= result nor data_bus;
when BRANCH_NOT_TAKEN =>
carry <= '0';
when others => null;
end case;
-- State machine
if cpu_state /= FETCH then
cpu_state <= FETCH;
elsif opcode ?= "11" and carry then
cpu_state <= BRANCH_NOT_TAKEN;
else
states <= "0" & not opcode; -- execute instruction
case opcode is
when "00" => cpu_state <= ALU_NOR; -- 011
when "01" => cpu_state <= ALU_ADD; -- 010
when "10" => cpu_state <= WRITE; -- 001
when "11" => cpu_state <= FETCH; -- 000
when others => null;
end case;
end if;
end if;
end process;
-- output
address <= address_register;
data_bus <= result when (cpu_state = WRITE) else (others => 'Z');
-- output enable is active low, asserted only when
-- rst=1, clk=0, and state!=001(wr_acc) and state!=101(read_pc)
n_oe <= '1' when (clock='1' or cpu_state = WRITE or n_reset = '0' or cpu_state = BRANCH_NOT_TAKEN) else '0';
-- write enable is active low, asserted only when
-- rst=1, clk=0, and state=001(wr_acc)
n_we <= '1' when (clock = '1' or cpu_state /= WRITE or n_reset = '0') else '0';
end;
Réalisation du MCPU en mono cycle (un cycle d'horloge par instruction)
Le travail demandé dans cette section est important pour simplement doubler la vitesse de notre processeur puisque toutes les instructions étaient réalisées en deux cycles d'horloge et vont l'être maintenant en un seul cycle. Il est même possible que la première version puisse tourner avec une fréquence un peu plus grande et qu'ainsi le gain ne soit pas total.
Pourtant si vous désirez écrire votre propre cœur embarqué nous pensons que cette deuxième façon est plus moderne : la très grande majorité des architectures modernes sont des architectures Harvard.
Cette section est difficile à comprendre. Même si elle ne fait intervenir que des notions du niveau indiqué, il est conseillé d'avoir du recul sur les notions présentées pour bien assimiler ce qui suit. Cependant, ce contenu n'est pas fondamental et peut être sauté en première lecture.
Dans une réalisation mono cycle un processeur doit accéder aux instructions et aux données indépendamment et chaque instruction se réalise en un cycle d'horloge. C'est ce que l’on appelle l'architecture Harvard qui propose une mémoire pour les données et une mémoire pour le programme comme déjà expliqué.
Si l’on veut rapidement réaliser une architecture programmable mono cycle, il faut d’abord se pencher sur le chemin de données. Concevoir le chemin de données est un processus incrémental. On commence toujours par le séquencement des instructions (recherche des instructions en mémoire), puis à chaque étape on examine une classe d'instructions et on essaye de construire une portion du chemin de donnée qui peut exécuter cette classe d'instructions. Nous allons le détailler maintenant pour notre architecture MCPU.
Les sections suivantes sur la réalisation mono cycle du MCPU sont inspirées du livre "Embedded Core Design with FPGA" de Zainalabedin Navabi (McGrawHill 2007) qui montre la construction d'un processeur de quatre instructions (en verilog). Ses quatre instructions choisies sont différentes de celles du MCPU de Tim Boescke et conduisent à un processeur seulement capable de faire une addition alors que le MCPU est capable de calculer un PGCD. Les objectifs de Zainalabedin Navabi étaient d'expliquer et d'introduire une méthode de construction du chemin de données ce qu’il a réussi à faire puisque nous l'utilisons de suite.
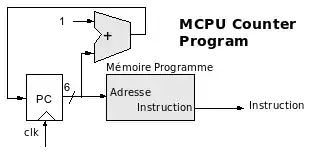
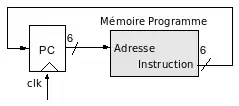
Séquencement du programme
Le déroulement d'un programme se fait par recherche de l'instruction "Instruction Fetch" et incrémentation du PC (compteur programme ou compteur ordinal) pour pouvoir aller chercher l'instruction suivante. Voici le schéma correspondant :
Instructions NOR et ADD
Ces deux instructions sont dans le même groupe car elles vont chercher toutes les deux une donnée en mémoire. Voici le schéma correspondant :
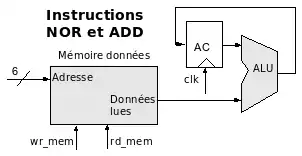
Vous voyez apparaître dans cette figure une Unité Arithmétique et Logique ou ALU qui est responsable de la réalisation de deux instructions. Cela signifie qu'elle possède à ce stade un seul fil de sélection non présenté dans le schéma. Un registre supplémentaire, l’accumulateur noté "AC", apparaît maintenant dans notre nouvelle architecture.
Regrouper les instructions par groupes nécessite une certaine expérience. Lisez l’article Instruction Machine qui vous détaille un classement des instructions.
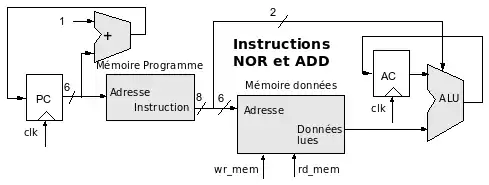
Séquencement de NOR et ADD
Cela consiste tout simplement à associer les deux schémas précédents :
Instruction STA ou écriture dans la mémoire données
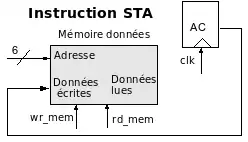
Évidemment l'adresse provient de l'instruction.
Séquencement des 3 instructions
On assemble les deux derniers schémas :
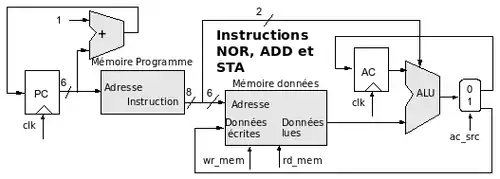
Un soin tout particulier devra être pris pour l’ensemble AC + ALU + DMUX si l’on veut garder la valeur dans AC (front d'horloge inévitable).
Instruction de contrôle et son chemin de donnée
L'instruction de contrôle unique est JCC qui a la particularité de mettre la retenue à 0 après son exécution.
Jusqu'à présent, le bit de retenue n'a pas été ajouté au schéma pour raisons de simplifications.
Ensemble des instructions
L'ensemble des instructions peut être réalisé par le chemin de données suivant:
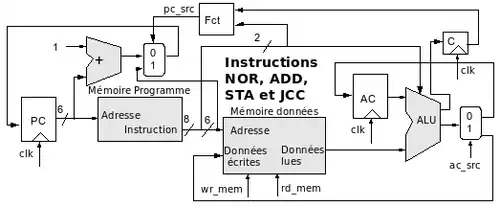
La fonction combinatoire "Fct" détecte l'instruction JCC et la retenue à 0.
Le fait de séparer la mémoire données de la mémoire programme présente un grave inconvénient pour une si petite architecture : on ne peut plus mettre les données dans la mémoire programme puisqu’il n'y a plus d'instruction pour venir les chercher ! Il existe heureusement plusieurs solutions pour contourner cela :
- Décomposer la mémoire données en deux parties comme dans la très grande majorité des micro contrôleurs modernes, soit un banc de registres suivi de la RAM proprement dite. Le banc de registres relié à l'extérieur permettrait d'entrer les données par l'extérieur.
- Prévoir dans l'assembleur une possibilité de séparer des valeurs qui iront dans la mémoire données. La programmation du composant se fera par l'envoi du programme pour la mémoire programme et par l'envoi des données pour la mémoire données.
Réalisation de l'unité de contrôle
L'unité de contrôle permet de générer "wr_mem", rd_mem", "ac_src" et "pc_src" à partir des bits d'instructions et de la retenue. C'est donc tout simplement une super-fonction combinatoire remplaçant "Fct".
Exercice 2
Implanter complètement l'architecture MCPU monocycle et la tester avec le programme PGCD.
Voir aussi
Pour aller plus loin, jetez un coup d'œil sur les processeurs et aussi fonctionnement appelé pipeline.
- Série de 12 étapes pour construire un processeur 16 bits : Le processeur S3 sur carte Nexys2/ Nexys3 de Jean-Luc DEKEYSER
- (en) Microprocessor Design
- John Kent's Micro8, une extension de MCPU