Windows-1252
Windows-1252 ou CP1252 (abréviation de « code page – 1252 » , signifiant Page de code – 1252) est un jeu de caractères, utilisé historiquement par défaut sur le système d'exploitation Microsoft Windows en anglais et dans les principales langues d’Europe de l’Ouest, dont le français.
| Windows-1252 | ||
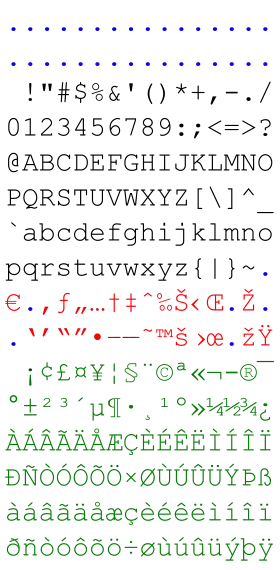 | ||
| Famille | Microsoft Windows | |
|---|---|---|
| Langues | Allemand, anglais, basque, catalan, danois, espagnol, finnois, français, italien, néerlandais, norvégien, portugais et suédois, parmi d'autres langues européennes | |
| Nombre de caractères | ~223 | |
| État du projet | Standardisé par Microsoft | |
| Plates-formes | Windows | |
| Organisme / Parrainage |
Microsoft | |
| Numéro d'enregistrement | 1252 | |
| Séquences d'échappement | Non prises en charge | |
| Unité de codage (codet) | 8 bits | |
Contexte
Au début des années 1990, l'utilisation du codage Windows-1252 se développe en Occident, avec la diffusion de Windows 3.x. Les caractères codés sont appelés par confusion « ANSI » au lieu d'« occidentaux » ((en)« Western »)[1]. L'erreur est corrigée mais l'usage est perpétué par ses successeurs (notamment Windows 95, 98, NT, 2000, XP, Vista, 2003, 7). À cette époque, le jeu de caractères Windows-1252 se substitue aux jeux de caractères DOS, c'est-à-dire à la page de code 437 dans les pays anglophones, et à la page de code 850 dans la plupart des pays d'Europe de l'Ouest. L'ensemble des logiciels développés pour Windows fonctionne alors avec cet ensemble de caractères.
Toutefois, sous l'influence des problèmes d'interopérabilité, des régions francophones multilingues (Union européenne, Maghreb) ainsi que de la mondialisation des échanges et du développement d'Internet en particulier, et bien que le codage Windows-1252 reste encore utilisé, ce codage subit la concurrence et le développement du standard Unicode.
De nos jours, les applications modernes n'utilisent plus ce type de codage, sauf lorsqu'il est nécessaire pour :
- communiquer avec des applications anciennes ;
- communiquer avec des serveurs anciens, qui peuvent éventuellement ne pas supporter encore Unicode ;
- communiquer avec la console Windows[2].
Aspects techniques
Windows-1252 est une extension de l'ISO/CEI 8859-1 : il diffère du codage ISO-8859-1 par l'utilisation de caractères imprimables, plutôt que des caractères de contrôle, dans les codes 128 à 159. Pour les utilisateurs de Windows, Microsoft appelle ceci de manière générique ANSI, mais, en fonction de l'endroit où le système d'exploitation a été vendu, l'ensemble de caractères peut avoir un autre nom, comme CP1252 aux États-Unis ou, dans les pays de l'Europe de l'Ouest, le nom validé par l'IANA, Windows-1252.
Table des caractères
Le tableau suivant montre Windows-1252. Les numéros 81, 8D, 8F, 90, et 9D ne sont pas utilisés et sont signalés par la couleur vert pâle. Les changements par rapport à ISO-8859-1 sont signalés par la couleur jaune.
| Windows-1252 (CP1252) | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x0 | x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | x9 | xA | xB | xC | xD | xE | xF | |
| 0x | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI |
| 1x | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2x | SP | ! | " | # | $ | % | & | ' | ( | ) | * | + | , | - | . | / |
| 3x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4x | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5x | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 6x | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7x | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
| 8x | € | ‚ | ƒ | „ | … | † | ‡ | ˆ | ‰ | Š | ‹ | Œ | Ž | |||
| 9x | ‘ | ’ | “ | ” | • | – | — | ˜ | ™ | š | › | œ | ž | Ÿ | ||
| Ax | NBSP | ¡ | ¢ | £ | ¤ | ¥ | ¦ | § | ¨ | © | ª | « | ¬ | ® | ¯ | |
| Bx | ° | ± | ² | ³ | ´ | µ | ¶ | · | ¸ | ¹ | º | » | ¼ | ½ | ¾ | ¿ |
| Cx | À | Á | Â | Ã | Ä | Å | Æ | Ç | È | É | Ê | Ë | Ì | Í | Î | Ï |
| Dx | Ð | Ñ | Ò | Ó | Ô | Õ | Ö | × | Ø | Ù | Ú | Û | Ü | Ý | Þ | ß |
| Ex | à | á | â | ã | ä | å | æ | ç | è | é | ê | ë | ì | í | î | ï |
| Fx | ð | ñ | ò | ó | ô | õ | ö | ÷ | ø | ù | ú | û | ü | ý | þ | ÿ |
Interopérabilité
Windows-1252 est reconnu et utilisé par les plates-formes Windows et n'est pas reconnu dans d'autres systèmes d'exploitation : DOS n'utilise que les pages de codes d'IBM, et Linux/Unix utilisent nativement les pages de codes ISO (exemple ISO-8859-15) ou UTF-8.
Pour ces raisons notamment, Unicode (et plus généralement ISO/CEI 10646) tend à lui être préféré.
Interopérabilité en HTML
Selon les standards HTML du W3C, UTF-8 est un codage adapté à la plupart des documents HTML[3]. Cependant, l'usage de Windows-1252 a été si répandu que plusieurs navigateurs supportent les références numériques de caractères pour les codes 128 à 159, alors qu'ils ne correspondent à des caractères que pour Windows-1252, mais correspondent à des contrôles C1 en Unicode si on les code en UTF-8 et non pas en référence numérique.
Ainsi, le symbole « € » est le caractère Unicode numéro 8364 — 20AC(16) —, donc € — € — est la référence numérique standard du symbole « € » ; mais, comme « € » est le caractère Windows-1252 numéro 128 — 80(16) —, certains navigateurs supportent aussi € — € — comme référence numérique de ce caractère, bien que ce soit illégal en HTML où cela devrait indiquer un contrôle C1 (par ailleurs, la plupart des contrôles C1 sont illégaux également en HTML, en dehors des contrôles de séparation de ligne pour lesquels il est légal en HTML de les représenter sous forme de référence numérique, aussi bien en décimal qu'en hexadécimal, ce qui explique alors l'illégalité des références numériques des numéros 128 à 159 pour indiquer un caractère du code Windows-1252 ; cependant divers navigateurs font exception à cette règle pour les codes qui ne sont pas associés aux quelques contrôles C1 autorisés, et alors les afficher selon le code Windows-1252 et non selon le point de code Unicode standard)[4].
Voir aussi
Articles connexes
Notes et références
- Glossaire des termes utilisés, Centre de développement sur la globalisation, Microsoft Developer Network (MSDN), page A
- https://docs.microsoft.com/en-us/windows/desktop/intl/code-pages
- « Les codages de caractères », sur www.w3.org (consulté le )
- Codage valide des caractères Windows illégaux en HTML et XHTML
 Portail de l’écriture
Portail de l’écriture  Portail de l’informatique
Portail de l’informatique  Portail de Microsoft
Portail de Microsoft