Supercalculateur exaflopique
Les supercalculateurs exaflopiques (Exascale computing en anglais) sont des ordinateurs de type supercalculateur fonctionnant selon une architecture massivement parallèle et dont la puissance de calcul dépasse 1018 flops. La machine décompose les tâches à effectuer en millions de sous-tâches, dont chacune d'entre elles est ensuite réalisée de manière simultanée par un processeur.
.jpg.webp)
Il n'existe pas de machine Exascale en 2020. Pour atteindre ce niveau, les systèmes informatiques auront besoin d'une refonte complète sur la façon de relever les défis dans différents domaines.
Une course à la puissance est en cours avec des programmes aux États-Unis, en Europe, en Chine et au Japon. Les premières livraisons avec cette capacité de calcul sont annoncées pour 2021 par Cray.
Les missions du supercalculateur exaflopique seront orientées vers la recherche et le développement de plusieurs enjeux de notre société.
Supercalculateurs exaflopiques
Définition

Les supercalculateurs exaflopiques (Exascale computing) sont des superordinateurs (High-Performance Computing ou HPC) qui ont une puissance de calcul de l'ordre de 1018 flops (un exaflop = un milliard de milliards d’opérations en virgule flottante par seconde)[1],[2],[3]. Ces machines sont une collection de microprocesseurs fortement connectés entre eux, dont chacun d'eux se caractérise par une fréquence d’horloge élevée et se compose de plusieurs cœurs de calcul. Pour concevoir des superordinateurs très performants, les constructeurs jouent simultanément sur le nombre de microprocesseurs, le nombre de cœurs, la fréquence d’horloge et l'association des processeurs graphiques[4]. L'idée fondamentale derrière le HPC est le calcul en parallèle qui consiste à distribuer plusieurs segments d’une équation complexe sur plusieurs processeurs afin de les calculer simultanément[5]. Un supercalculateur se compose de milliers de nœuds, un nœud étant la brique de base constituée d'un assemblage de plusieurs microprocesseurs[6]. Une capacité élevée de calcul nécessite un espace de stockage en conséquence qui atteint plusieurs pétaoctets (dix pétaoctets sur Summit d'IBM par exemple). En plus de la vitesse de pointe, ils doivent disposer aussi d'un environnement logiciel qui facilite son utilisation efficace et productive[1].
Les coûts de recherche et développement pour créer un système informatique exaflopique ont été estimés par de nombreux experts à plus d'un milliard de dollars américains, avec un coût d'exploitation annuel de plusieurs dizaines de millions de dollars[7].
Les deux applications principales des supercalculateurs sont le Calcul Haute Performance (CHP, High Performance Computing en anglais), et l’analyse des données complexes. Initialement, l'utilisation des supercalculateurs était limitée à certaines applications particulières telles que les simulations simples, l'ingénierie, le pétrole et le gaz en raison du coût énorme des systèmes HPC[5]. Puis elle s'est élargie dans divers domaines tels que l'exploration de données, les recherches sur le climat, la santé, l'automobile, la physique, l'astrophysique, la mécanique des fluides numérique ou encore la nanotechnologie moléculaire. Ces futurs moyens permettront de réaliser des découvertes à travers un large spectre de domaines scientifiques afin de nous aider à améliorer notre compréhension du monde où nous vivons[1],[8],[9].
Enjeux
Les progrès dans la compréhension de certains problèmes scientifiques sont souvent associés à l'évolution des informatiques. Des capacités supérieures aux systèmes petascale aideront les scientifiques à concevoir des modèles et exécuter des simulations de problèmes complexes. La simulation numérique est une démarche essentielle de la recherche scientifique en complément de la théorie et de l’expérimentation[3]. Elle est aussi une partie prenante des cycles de conception et de production dans de nombreuses filières industrielles[10]. Ces machines permettent une conception et une optimisation multidisciplinaires, réduisant le temps et les coûts de prototypage[3].
Les leaders comme les États-Unis, la Chine, l'Europe et le Japon rivalisent entre elles pour se doter des machines les plus puissantes[3]. Les enjeux relèvent de la politique de souveraineté et de sécurité individuelle et collective. Les politiques énergétique, prévention des risques naturels et de défense s’appuient sur les apports de la simulation et du calcul haute performance[11],[10].
Écosystème

Le CMOS (Complementary Metal Oxide Semiconductor) a permis aux performances des circuits microélectroniques de croître de façon exponentielle à coût constant[12]. La fin d'une croissance exponentielle spectaculaire des performances d'un seul processeur marque la fin de la domination du microprocesseur unique en informatique. L'informatique séquentielle cède la première place au parallélisme[10].
Bien que l'informatique haute performance ait bénéficié des mêmes avancées en matière de semi-conducteurs que l'informatique de base, les performances durables des systèmes HPC se sont améliorées plus rapidement en raison de l'augmentation de la taille du système et du parallélisme[13]. Le nombre de cœurs du système devrait atteindre plusieurs millions de cœurs de calcul[14],[15].
Dans les années 1980, la superinformatique vectorielle dominait l'informatique haute performance, comme en témoignent les systèmes nommés du même nom conçus par Seymour Cray. Les années 1990 ont vu la montée du traitement massivement parallèle (MPP : Massively Parallel Processing) et des multiprocesseurs à mémoire partagée (SMP : Shared Memory Multiprocessors) construits par Thinking Machines Corporation, Silicon Graphics et d'autres. À leur tour, des grappes de produits (Intel / AMD x86) et de processeurs spécialement conçus (comme BlueGene d'IBM) ont dominé les années 2000. La décennie suivante, ces clusters sont complétés par des accélérateurs de calcul sous la forme de coprocesseurs d'Intel et d'unités de traitement graphique (GPU) de Nvidia ; ils comprennent également des interconnexions à haut débit et à faible latence (comme Infiniband). Les réseaux de stockage (SAN) sont utilisés pour le stockage de données persistantes, avec des disques locaux sur chaque nœud utilisé uniquement pour les fichiers temporaires. Cet écosystème matériel est optimisé en priorité pour les performances, plutôt que pour un coût minimal. Au sommet du matériel du cluster, Linux fournit des services systèmes, complétés par des systèmes de fichiers parallèles (tels que Luster) et des planificateurs de lots (tels que PBS et SLURM) pour la gestion des travaux parallèles. MPI et OpenMP sont utilisés pour le parallélisme entre nœuds et internœuds, optimisé de bibliothèques et d'outils (tels que CUDA et OpenCL) pour une utilisation en coprocesseur. Des bibliothèques numériques (telles que LAPACK et PETSc) et des bibliothèques spécifiques au domaine complètent la pile logicielle. Les applications sont généralement développées en FORTRAN, C ou C++[16].
Il y a deux types de conceptions architecturales :
- conception basée sur des systèmes avec des nœuds hétérogènes : elle se caractérise par des nœuds combinant des processeurs puissants avec des accélérateurs (GPU)[17] ;
- conception du système basée sur des nœuds homogènes : les caractéristiques de base de cette conception sont un grand nombre de nœuds plus petits, chacun avec un pool de cœurs homogènes et un seul niveau de mémoire[17].
Performance
La course mondiale à la construction de superordinateurs toujours plus grands et plus puissants a conduit au fil des années à la création d'une pléthore d'architectures différentes et a entraîné diverses « révolutions ». Cette course a été enregistrée au fil des années dans la liste des supercalculateurs TOP500, où les supercalculateurs les plus puissants construits jusqu'à présent sont classés en fonction des performances maximales en virgule flottante (Site internet TOP500)[18],[3]. En général, la vitesse des superordinateurs est mesurée et comparée en FLOPS, et non en MIPS (en millions d'instructions par seconde), comme les ordinateurs à usage général[19]. Pour exprimer les performances globales d'un système informatique, on utilise le Linpack benchmark qui permet d'estimer la vitesse à laquelle l'ordinateur résout les problèmes numériques. Cette référence est largement utilisée dans l'industrie[20]. La mesure FLOPS est soit citée sur la base des performances théoriques en virgule flottante d'un processeur (« Rpeak » dans les listes TOP500), soit par la dérivée des Linpack benchmark (« Rmax » dans la liste TOP500)[21].
Les performances de Linpack donnent une indication pour certains problèmes du monde réel, mais ne correspondent pas nécessairement aux exigences de traitement de nombreuses autres charges de travail d'un supercalculateur, qui peuvent par exemple nécessiter la prise en compte de la bande passante, ou encore des systèmes I/O[20].
Défis majeurs et contraintes
Pour atteindre le niveau Exascale, les systèmes informatiques auront besoin d'une refonte complète sur la façon de relever les défis dans les domaines du coût, de la puissance, de l'efficacité du calcul, de la résilience et de la tolérance aux pannes, du mouvement des données à travers le réseau et, enfin, des modèles de programmation[22].
Puissance des processeurs


Depuis les années 1990, la croissance rapide des performances des microprocesseurs a été rendue possible grâce à trois moteurs technologiques clés : la mise à l'échelle de la vitesse des transistors, les techniques de microarchitecture et les mémoires caches[23]. Vers 2004, les puces ont cessé de s'accélérer lorsque les limitations thermiques ont mis fin à la mise à l'échelle des fréquences (également appelée mise à l'échelle de Dennard)[24],[25],[26]. Le progrès en miniaturisation a été mis au service du parallélisme massif. Pour augmenter la puissance des supercalculateurs, la tendance est à la multiplication des cœurs de calcul au sein des processeurs[27],[24].
Pour l'architecture d'un nœud de calcul, certains privilégient l’utilisation des processeurs graphiques (GPU), qui servent normalement au rendu réaliste des jeux vidéo. La puissance de ces processeurs repose sur l’utilisation de plusieurs centaines de cœurs de calculs organisés selon une architecture simplifiée, SIMD (pour Single Instruction Multiple Data), où toutes les unités exécutent en parallèle une même tâche, mais sur des données différentes[28]. D’autres misent plutôt sur le parallélisme d’un grand nombre de cœurs généralistes — une centaine par processeur — dont les performances seront boostées par l’ajout d’unités dites « vectorielles » qui opèrent sur des registres de 512 bits au lieu de 64 habituellement. On réalise ainsi huit fois plus de calculs par cycle. Cette nouvelle architecture proposée par Intel a été baptisée « MIC » (Many Integrated Cores). Les GPU ou les MIC jouent ainsi le rôle d’accélérateur de calcul et permettent d’améliorer l’efficacité énergétique[29].
The National Strategic Computing Initiative (NSCI) propose des axes de recherche stratégiques, le premier étant d'accélérer la livraison d'un système informatique exascale. Cet objectif peut être atteint sur la base de l'évolution continue de la technologie des transistors CMOS et des technologies plus récentes comme la photonique au silicium et l'intégration de mémoire 3D[26],[30]. L'émergence d'un dispositif basse tension à haute performance pourrait considérablement assouplir les contraintes de production d'énergie et de chaleur qui limitent le calcul[31],[26].
Mémoire, interconnexion et refroidissement
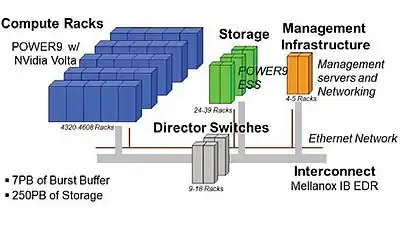
Dans le régime de calcul Exascale, le coût énergétique des mouvements de données entre la mémoire et le pipeline FPU devrait dépasser le coût d'une opération en virgule flottante. Cela nécessite des interconnexions écoénergétiques, à faible latence et à large bande passante afin de permettre les échanges de données entre les processeurs[32],[33]. Il faudra intégrer dans un seul et même composant électronique plusieurs fonctions telle que les mémoires et les interconnexions[34]. Le but étant de réduire la distance physique entre les composants et de s'assurer que les éléments de calcul exploitent pleinement la localité physique avec le stockage[22],[35].
Mémoire
La minimisation du mouvement des données et la réduction de la consommation d'énergie dépendent également des nouvelles technologies de mémoire, y compris la mémoire du processeur, la mémoire empilée et les approches de mémoire non volatile[32],[26],[36].
La SRAM peut être intégrée à une logique CMOS hautes performances, permettant une intégration plus rentable de grandes quantités de mémoire logique par rapport à la DRAM et flash sur la même puce[26].
Interconnexion
Le réseau de communication d'un supercalculateur interconnecte des milliers de nœuds. Pour les machines exaflopiques, il faudra cette fois relier entre eux dix fois plus de nœuds que les machines pétaflopiques[6]. La façon dont ces éléments informatiques sont connectés les uns aux autres (topologie du réseau) a un fort impact sur de nombreuses caractéristiques de performance[34]. Il existe de nombreuses topologies possibles pour construire des systèmes parallèles, tels que le tore, l'arbre classique ou encore le Dragonfly[34]. Pour être efficace en Exascale, les communications devront s'effectuer de façon complètement autonome sans faire intervenir les cœurs des processeurs dédiés aux calculs. L'enjeu est de développer de nouvelles architectures de réseaux d’interconnexions intimement intégrés aux nœuds de calcul[6].
Refroidissement
L’énergie électrique consommée par un calculateur est transformée en grande partie en chaleur (effet Joule), ce qui nécessite l’installation de systèmes de refroidissement qui sont également gourmands en énergie[37]. L'infrastructure de refroidissement est généralement conçue pour un fonctionnement aux puissances maximales des systèmes HPC déployés. Les concepteurs doivent innover pour concevoir des systèmes plus efficaces[38].
Fiabilité et résilience
Idéalement, les systèmes seraient homéostatiques, s'adaptant aux pannes matérielles et logicielles sans intervention humaine et continuant de fonctionner jusqu'à ce que le nombre de pannes devienne trop important pour atteindre les objectifs de performance[39].Étant donné que les composants défaillants sont périodiquement remplacés, le système HPC ne se dégrade jamais au point que les utilisateurs remarquent[40].
Avec l'augmentation de la complexité et du nombre de nœuds dans les systèmes HPC au fil du temps, la probabilité que les applications connaissent des échecs d'exécution a considérablement augmentée[14],[41]. Les machines exaflopiques, qui contiendront plusieurs millions de cœurs de calcul, seront sujettes à plusieurs pannes par heure[14],[15],[35]. La résilience systémique face aux défaillances régulières des composants sera essentielle[41],[35].
Les erreurs matérielles, également appelées erreurs permanentes, dépendent d'une stratégie d'atténuation différente des erreurs Logicielles. Ces erreurs peuvent être partiellement corrigées en incorporant des composants redondants ou de rechange. Par exemple, la construction de cœurs supplémentaires qui reste inactif, mais peut être mise en service pour remplacer tout processeur défaillant[42].
Le taux d'erreur fait référence aux erreurs transitoires qui affectent le temps moyen entre les interruptions d'application. Le Mean Time to Identify (MTTI) est tout échec qui nécessite une action corrective de l'application par opposition aux erreurs qui sont cachées à l'application par un mécanisme de résilience dans le matériel ou le logiciel[43].
Tous les protocoles basés sur des points de contrôle reposent sur l'enregistrement périodique de l'état d'exécution du système et le redémarrage à partir d'un état sans erreur antérieur après l'occurrence d'une défaillance[14].
Daniel Dauwe, Sudeep Pasricha, Anthony A. Maciejewski et Howard Jay Siegel proposent une comparaison de quatre protocoles de résilience HPC qui utilisent les points de contrôle :
- Checkpointing and Restarting
Le point de contrôle est la technique de résilience la plus utilisée par les HPC. Elle consiste à noter l’état de tous les programmes en cours d’exécution sur un périphérique de stockage(comme le système de fichiers parallèles). Cela se fait en arrêtant le système à intervalles réguliers.
- Multilevel Checkpointing
Étant donné que différents types de défaillances peuvent affecter un système informatique de différentes manières, toutes les défaillances ne nécessitent pas le redémarrage du système à partir d'un point de contrôle. Multilevel Checkpointing exploite cela en fournissant plusieurs niveaux de point de contrôle. Chaque niveau offre un compromis entre le temps nécessaire au point de contrôle, au redémarrage et le niveau de gravité de l'échec à partir duquel le système peut reprendre le calcul.
- Message Logging
Cette technique consiste à enregistrer les messages envoyés entre processus pour générer des captures de l’exécution des programmes qui seront réparties sur l’ensemble des mémoires du système. En cas de panne cela va permettre au nœud défaillant d’utiliser les messages stockés dans la mémoire d’un autre nœud pour la récupération. Cette méthode a pour avantage de réduire le temps du recalcule et d'économiser de l'énergie car seul le nœud défaillant est actif, le reste du système peut rester inactif jusqu’à la récupération.
- Redundancy
La technique de la redondance est utilisée pour améliorer la fiabilité d’un système. Cette méthode peut être mise en œuvre au niveau du matériel ou logiciel et elle permet de réaliser plusieurs copies du même morceau du code. L’inconvénient reste l’utilisation de ressources supplémentaires[44].
Parallélisation à très large échelle
Le parallélisme a provoqué une révolution dans les performances de l'ordinateur. Celui-ci a été introduit dans les années 1990 et est toujours à l'étude pour traiter les systèmes informatiques Exascale ciblés[9].
Avec plusieurs millions de cœurs de calcul[14],[15], le défi sera de paralléliser à l’extrême les calculs, c’est-à-dire de les diviser en un très grand nombre de sous-calculs exécutés par les cœurs des processeurs. Il faudra répartir les tâches équitablement entre les cœurs pour permettre aux machines d’être performantes. Cela pose des questions en termes de programmation qui nécessite une nouvelle approche de programmation parallèle à faible consommation d'énergie pour atteindre des performances massives[5]. Il faut des modèles de programmation plus expressifs capables de gérer ce procédé et de simplifier les efforts du développeur tout en prenant en charge un parallélisme dynamique et à grain fin[33]. La programmation de tels futurs systèmes massivement parallèles et hétérogènes ne sera pas anodine, et les modèles de programmation et les systèmes d'exécution devront être adaptés et repensés en conséquence[41],[45].
Les chercheurs Usman Ashraf, Fathy Alburaei Eassa, Aiiad Ahmad Albeshri et Abdullah Algarni présentent un hybride MPI + OMP + CUDA (MOC), un nouveau modèle de programmation parallèle massif pour les systèmes de cluster hétérogènes à grande échelle. Ils annoncent « une accélération asymptotique allant jusqu'à 30 %-40 % par rapport aux meilleures implémentations sur multiprocesseurs hétérogènes et des GPU Nvidia accélérés »[5].
Le projet ECOSCALE vise à fournir une approche holistique pour une nouvelle architecture hiérarchique hétérogène à haut rendement énergétique, un environnement de programmation hybride MPI + OpenCL et un système d'exécution pour les machines exascale[22].
Softwares, middlewares et algorithmes
Depuis , les 500 superordinateurs les plus rapides au monde s'exécutent sur des systèmes d'exploitation basés sur Linux[46].
Les machines exaflopiques, qui contiendront plusieurs millions de cœurs de calcul, seront sujettes à plusieurs pannes par heure[47],[15]. Les logiciels devront donc être capables de distribuer au mieux les tâches à effectuer entre tous les cœurs de calcul en réduisant au maximum le mouvement des données. Ils devront également sauvegarder les données au cours de l’exécution des calculs pour que celles-ci ne soient pas perdues si un composant de la machine tombe en panne[48],[49].
Les applications ayant beaucoup d'échanges ou de synchronisations entre leurs sous-tâches sont dites fine-grained, c'est-à-dire à grain fin, celles qui ont au contraire peu d'échanges et de synchronisations sont dites coarse-grained, c'est-à-dire à gros grain. L'informatique exascale exigera une grande demande en algorithmes dans au moins deux domaines : la nécessité d'augmenter les quantités de données locales pour effectuer efficacement les calculs et la nécessité d'obtenir des niveaux beaucoup plus élevés de parallélisme à grain fin, car ces systèmes prennent en charge un nombre croissant de fil d'instruction. En conséquence, les algorithmes parallèles doivent s'adapter à cet environnement, et de nouveaux algorithmes et implémentations doivent être développés pour exploiter les capacités de calcul du nouveau matériel[50].
Les nouvelles conceptions logiciels et systèmes d'exploitation devront prendre en charge la gestion des ressources hétérogènes et des hiérarchies de mémoire non cohérentes avec le cache, fournir aux applications et à l'exécution plus de contrôle sur les politiques de planification des tâches et gérer les espaces de noms globaux. Ils doivent également exposer des mécanismes de mesure, de prévision et de contrôle plus précis de la gestion de l'énergie, permettant aux ordonnanceurs de mapper les calculs aux accélérateurs spécifiques à la fonction et de gérer les enveloppes thermiques et les profils énergétiques des applications[51].
Une collaboration devrait naître des spécialistes des mathématiques appliquées qui développent des outils de calcul numérique et des informaticiens spécialistes du calcul haute performance qui conçoivent des logiciels pour permettre d'exploiter au mieux les caractéristiques matérielles de ces nouvelles architectures massivement parallèles[52].
De nouveaux langages et modèles de programmation au-delà de C et FORTRAN seront utiles. Les fonctionnalités de programmation trouvées dans Chapel et X10 ont déjà eu un effet indirect sur les modèles de programmes existant(tels que OpenMP). Ces derniers ont profité des extensions pour les exemples suivants: le parallélisme des tâches, les accélérateurs et l'affinité des threads. Les langues spécifiques au domaine (DSL) (Domain Specific Language) se spécialisent dans un domaine d'application particulier, représentant un moyen d'étendre la langue de base existante. Les DSL intégrés sont un moyen pragmatique d'exploiter les capacités sophistiquées d'analyse et de transformation des compilateurs pour les langages standards[53].
La répartition de charge est un défi à prendre en compte. L'unité d'équilibrage de charge répartit la charge de traitement entre les systèmes informatiques disponibles afin que le travail de traitement soit effectué dans un minimum de temps. La répartition de charge peut être implémenté avec un logiciel, du matériel ou une combinaison des deux[54].
Un développement significatif du modèle, une refonte de l'algorithme et une réimplémentation des applications scientifiques, soutenus par un ou des modèles de programmation adaptés à l'exascale, seront nécessaires pour exploiter la puissance des architectures exascales[53]. Il s'agira de systèmes basés sur une architecture homogène ou hétérogène. Par conséquent, nous avons besoin d'un modèle de programmation hybride adaptatif qui peut traiter à la fois des systèmes d'architecture homogènes et hétérogènes[55],[56].
Consommation énergétique
Le supercalculateur pétaflopique Titan introduit en 2012 dans les laboratoires nationaux d'Oak Ridge avec une consommation de neuf mégawatts (MW) et une puissance de pointe théorique de vingt-sept pétaFLOPS a généré une facture d'électricité annuelle d'environ neuf millions de dollars[22]. Les coûts très élevés incluant l’installation des infrastructures et d’entretien deviennent des facteurs prédominants dans le coût total de possession (TCO) d’un superordinateur[57],[2],[58],[59]. Le coût énergétique de ces plates-formes au cours de leur durée de vie utile, généralement de trois à cinq ans[40], pourrait rivaliser avec leur coût d'acquisition[2].
Power Usage Effectiveness (PUE) est une mesure bien établie pour évaluer l'efficacité énergétique des centres de données. Intuitivement, le PUE mesure la fraction d'énergie fournie à une installation qui alimente l'équipement informatique réel[60]. Par conséquent, afin de rendre un centre de données plus économe en énergie, et donc de réduire sa valeur PUE, il faudrait s'attaquer à tous les facteurs influençant la consommation d'énergie : l'infrastructure de refroidissement (Pcooling) ; les systèmes HPC déployés jusqu'à la gestion des ressources et la planification et l'optimisation des applications (PIT) ; les pertes de puissance dues à la distribution et à la conversion électrique (PelectricalLosses) ; et à la consommation d'énergie diverse Pmisc[37].

Ces conclusions ont également commencé à influencer la conception et le déploiement des HPC, pour réduire leur PUE[60].
Un supercalculateur Exascale avec la même technologie que sur les machines pétaflopiques entraîneraient des consommations de pointe de plus de 100 MW, avec une conséquence immédiate sur le coût de gestion et d'alimentation[22],[27],[59]. La puissance requise par Exascale computing de dizaines de mégawatts rend la gestion de la consommation d'énergie beaucoup plus difficile par rapport aux systèmes qui prennent en charge de nombreux petits travaux[2].
Pour concevoir des machines exaflopiques, il faut relever le principal défi qui est d’être capable de réduire les importants coûts de consommations énergétiques de ces plates-formes[57],[59]. Des pionniers du HPC tels que le Département américain de l'énergie (US DoE), Intel, IBM et AMD ont défini une limite maximale de consommation électrique d'une machine Exascale de l'ordre de 25–30 MW[57],[61],[5]. Avec par exemple une consommation d'énergie cible de 20 MW, il faudrait une efficacité énergétique de ∼20 pJ / Op[22].
Pour atteindre l'objectif de puissance attendue il est nécessaire d'avoir une amélioration significative de l'efficacité énergétique du système informatique, entraînée par un changement à la fois dans la conception matérielle et le processus d'intégration[61],[62].
Projets et recherches
Internationale
Bien que la concurrence mondiale pour le leadership en informatique avancée et en analyse de données se poursuit avec des programmes au Ėtats-Unis, en Europe, en Chine et au Japon[3] ; il existe une collaboration internationale active. Le projet international de logiciel Exascale (IESP) en est un exemple en informatique avancée. Grâce au financement des gouvernements du Japon, de l'UE et des États-Unis, ainsi qu'à des contributions des parties prenantes de l'industrie, l'IESP a été créé pour permettre la recherche en science et ingénierie à ultra-haute résolution et gourmande en données jusqu'en 2020. L'équipe internationale de l'IESP a développé un plan pour un environnement de calcul commun pour les systèmes pétascale / exascale[63].
États-Unis
Les États-Unis sont un leader international de longue date dans la recherche, le développement et l'utilisation de l'informatique haute performance (HPC). Une série d'activités est née en 2016 de l’ordre du National Strategic Computing Initiative(NSCI), dont la plus importante est l'initiative de calcul exascale (ECI). Il est dirigée par le Département américain de l'énergie (DoE) qui est un partenariat entre l'Office of Science et la National Nuclear Security Administration (NNSA). L'objectif est d'accélérer les projets de recherche, de développement, d'acquisition et de déploiement afin de fournir une capacité informatique exascale à ses laboratoires du début au milieu des années 2020[11].
ECI s'occupe de la préparation des installations informatiques et de l'acquisition de trois systèmes exascale distincts :
- Aurora : le département américain de l'énergie a annoncé le qu'Intel et Cray construiraient le premier supercalculateur exascale aux États-Unis. Il sera livré au Laboratoire national d'Argonne en 2021. Le système comprendra plus de 200 armoires Shasta, la pile logicielle unique de Cray optimisée pour les architectures Intel, l'interconnexion Cray Slingshot, ainsi que des innovations technologiques Intel de prochaine génération dans les technologies de processeur de calcul, de mémoire et de stockage[64],[65] ;
- Frontier : il sera construit par AMD et Cray pour le laboratoire national d'Oak Ridge, le contrat est évaluée à plus de 600 millions de dollars et la livraison est prévue en 2021. Le système sera basé sur l'architecture Shasta, l'interconnexion Slingshot de Cray, un processeur AMD EPYC hautes performances et la technologie GPU AMD Radeon Instinct. Frontier fournira de nouvelles capacités d'apprentissage en profondeur, d'apprentissage automatique et d'analyse de données pour des applications allant de la fabrication à la santé humaine[66] ;
- El Capitan : US DoE, NNSA et le Laboratoire national Lawrence Livermore ont annoncé le la signature d'un contrats avec Cray pour la construction de ce supercalculateur. Ses performances maximales atteindront plus de 1,5 exaFLOPS et sa livraison est prévue pour fin 2022. Il sera utilisé pour effectuer les évaluations critiques nécessaires pour faire face à l'évolution des menaces à la sécurité nationale et à d'autres fins telles que la non-prolifération ou la lutte contre le terrorisme nucléaire[67],[68].
Chine
En 2015, selon le classement de TOP500, le supercalculateur chinois Tianhe-2 était le plus rapide au monde. Il contient 16 000 nœuds. Chaque nœud possède deux processeurs Intel Xeon et trois coprocesseurs Intel Xeon Phi, une interconnexion haute vitesse propriétaire, appelée « TH Express-2 ». Il est conçu par l'université nationale de technologie de défense (NUDT)[69].
En 2010, Tianhe-1 est entré en service. Il effectue diverses tâches comme l'exploration pétrolière, la fabrication d'équipements haut de gamme, la médecine biologique et la conception d'animations, et sert près de 1 000 clients[70].
Selon le plan national pour la prochaine génération d'ordinateurs haute performance, la Chine développera un ordinateur exascale au cours de la 13e période du plan quinquennal (2016-2020). « Le gouvernement de la nouvelle zone de Tianjin Binhai, l'université nationale de technologie de défense (NUDT) et le Centre national de superordinateurs de Tianjin travaillent sur le projet, et le nom du supercalculateur sera Tianhe-3 », a déclaré Liao Xiangke, le directeur de l'école d'informatique de l'NUDT. Les nouvelles machines auront une vitesse de calcul deux cents fois plus rapide et une capacité de stockage cent fois supérieure à celle du Tianhe-1[70].
Europe
La Commission européenne et 22 pays d'Europe ont déclaré leur intention d'unir leurs efforts dans le développement des technologies et des infrastructures HPC grâce à un projet de recherche européen nommé « H2020 »[58]. Celui-ci soutiendra trois projets traitant des technologies exascale et postexascale :
- ExaNoDe qui a pour principe d'appliquer de nouvelles technologies d'intégration 3D et de conception matérielle, associées à la virtualisation des ressources et au système de mémoire UNIMEM[22] ;
- ExaNeSt qui étudiera comment les systèmes de stockage, d'interconnexions et de refroidissement devront évoluer vers Exascale[22] ;
- ECOSCALE qui vise à fournir une approche holistique pour une nouvelle architecture hiérarchique hétérogène à haut rendement énergétique, un environnement de programmation hybride MPI + OpenCL et un système d'exécution pour les machines exascale[22].
La combinaison de ces trois projets vise à couvrir l'ensemble de l'image d'une machine HPC Exascale d’ici 2020[22].
Japon
En , Fujitsu et l'institut de recherche japonais Riken ont annoncé que la conception du supercalculateur post-K était terminée, pour une livraison en 2021. Le nouveau système sera doté d'un processeur A64FX basé sur ARMv8-ASVE à 512 bits. Il s'agit d'un processeur haute performance conçu et développé par Fujitsu pour les systèmes exascale. La puce est basée sur un design ARM8. Ce processeur équipe une grande majorité des smartphones et abrite 48 cœurs de traitement complétés par quatre cœurs dédiés aux entrées-sorties et aux interfaces. Il peut gérer jusqu'à 32 Go de mémoire par puce. Le système sera équipé d'un processeur par nœud et de 384 nœuds par rack, soit un pétaflop par rack. Le système au complet sera constitué de plus de 150 000 nœuds. Le Post-K doit succéder, vers 2021, au K-Computer, qui équipe depuis l’institut de recherche Riken à Kobe[71].
Exemple d'étude complète
AMD Research, Advanced Micro Devices, Department of Electrical and Computer Engineering et l'université de Wisconsin-Madison proposent une étude complète d'une architecture qui peut être utilisée pour construire des systèmes exascale : «Une architecture conceptuelle de nœud exascale (ENA), qui est le bloc de calcul pour un supercalculateur exascale. L'ENA se compose d'un processeur hétérogène Exascale (EHP) couplé à un système de mémoire avancé. L'EHP fournit une unité de traitement accélérée hautes performances (CPU + GPU), une mémoire 3D à large bande passante intégrée et une utilisation massive des technologies d'empilement de matrices et de puces pour répondre aux exigences de l'informatique exascale de manière équilibrée.
Une architecture de nœud Exascale (ENA) en tant que bloc de construction principal pour les machines exascale. L'ENA répond aux exigences de calcul exascale à travers :
- une unité de traitement accéléré (APU) haute performance qui intègre des GPU à haut débit avec une excellente efficacité énergétique requise pour les niveaux de calcul exascale, étroitement couplée à des processeurs multicœurs haute performance pour les sections de code série ou irrégulières et les applications héritées ;
- utilisation massive des capacités d'empilement de matrices qui permettent une intégration dense des composants afin de réduire les frais généraux de déplacement des données et d'améliorer l'efficacité énergétique ;
- une approche basée sur des puces qui dissocie les composants de traitement essentiels aux performances (par exemple, les CPU et les GPU) aux composants qui ne s'adaptent pas bien à la technologie (par exemple, les composants analogiques). Cette méthode de fabrication permet de réduire les coûts et réutiliser la conception dans d'autres segments de marché ;
- mémoires multi-niveaux qui améliorent la bande passante en intégrant la mémoire 3D, qui est empilée directement au-dessus des GPU ;
- techniques avancées de circuits et techniques de gestion active de la puissance qui permettent de réduire l'énergie avec peu d'impact sur les performances ;
- mécanismes matériels et logiciels pour atteindre une résilience et une fiabilité élevées avec un impact minimal sur les performances et l'efficacité énergétique ;
- cadres de concurrence qui exploitent l'écosystème logiciel Heterogeneous System Architecture (HSA) et Radeon Open Compute Platform (ROCm) pour prendre en charge les applications nouvelles et existantes avec des performances élevées et une productivité élevée des programmeurs[72].
Exemples d'utilisation
Big data et intelligence artificielle
Les acteurs des télécoms et de l’internet comme les GAFA (Google, Apple, Facebook et Amazon) sont amenés quotidiennement à gérer une quantité gigantesque de données. Fortement en lien avec le Cloud et le Big Data dans leurs grands datacenters, le calcul intensif trouve sa place dans le traitement de ces données massives[73].
Sécurité nationale
La simulation numérique du fonctionnement d’une arme nucléaire peut être réalisée à l’aide d’un supercalculateur ou encore obtenir des certificats et des évaluations pour garantir que les stocks nucléaires du pays sont sûrs, sécurisés et fiables[74].
Biologie et biomédecine
L'informatique exascale accélérera la recherche sur le cancer en aidant les scientifiques à comprendre la base moléculaire des interactions protéiques clés et en automatisant l'analyse des informations provenant de millions de dossiers de patients cancéreux pour déterminer les stratégies de traitement optimales. Il permettra également aux médecins de prédire les bons traitements pour le patient en modélisant les réponses médicamenteuses[75].
Dans la biologie, il sera possible de simuler dans le détail le fonctionnement des membranes des cellules vivantes pour mieux comprendre comment les médicaments pénètrent dans la cellule et agissent[76]. Le séquençage du génome requiert aujourd’hui une exploitation et un stockage de quantités massives de données génétiques[77]. L'exascale computing sera un développement nécessaire pour soutenir les efforts de recherche en cours des biologistes computationnels. De suivre le rythme de la génération de données expérimentales à permettre de nouveaux modèles multiphysiques multi-échelles de processus biologiques complexes. La science informatique continuera d'évoluer et, à terme, de transformer la biologie d'une science observationnelle à une science quantitative[77].
Plus généralement, les défis biologiques et biomédicaux couvrent l'annotation et la comparaison des séquences, la prédiction de la structure des protéines ; simulations moléculaires et machines à protéines ; voies métaboliques et réseaux de régulation ; modèles et organes de cellules entières ; et les organismes, les environnements et les écologies[73].
Découverte scientifique
Les modèles informatiques des phénomènes astrophysiques, à des échelles temporelles et spatiales aussi diverses que la formation du système planétaire, la dynamique stellaire, le comportement des trous noirs, la formation galactique et l'interaction de la matière noire baryonique et putative, ont fourni de nouvelles perspectives sur les théories et complété les données expérimentales[78].
La cosmologie, la physique des hautes énergies et l'astrophysique font partie des sciences qui cherchent à comprendre l'évolution de l'univers, les lois qui régissent la création et le comportement de la matière. Ils dépendent des modèles informatiques avancés, ainsi le supercalculateur exaflopique sera un accélérateur dans ces différentes recherches[75].
Simulation avancée et modélisation industrielle
Les HPCs permettent de reproduire, par la modélisation et la simulation, des expériences qui ne peuvent pas être réalisées en laboratoire quand elles sont dangereuses, coûteuses, de longue durée ou très complexes. La simulation numérique a permis à Cummins de construire de meilleurs moteurs diesel plus rapidement et à moindre coût, Goodyear pour concevoir des pneus plus sûrs beaucoup plus rapidement, Boeing pour construire des avions plus économes en carburant et Procter & Gamble pour créer de meilleurs matériaux pour les produits domestiques[16].
Lu but est de faciliter et encourager l’accès aux PME au HPC pour leur permettre de simuler des phénomènes plus globaux, de limiter ou remplacer des expériences, de raccourcir la phase de test ou de traiter des données pléthoriques et hétérogènes. Le recours au calcul intensif sert à la compétitivité des PME[79].
Énergie
La fusion nucléaire pourrait constituer une source d’énergie majeure. Pour enclencher la réaction au sein d’un réacteur nucléaire, l’un des enjeux majeurs sera de confiner la chaleur dégagée par le phénomène bien au centre de la machine. Les phénomènes sont complexes et font appel à un jeu d’équations mathématiques qui génèrent un volume important de données à traiter. Les simulations numériques avec les supercalculateurs exaflopique permettront de faire un pas important dans cette direction[80].
L'énergie solaire sera rendue plus rentable grâce à la découverte de matériaux qui convertissent plus efficacement les rayons solaires en électricité[75].
L'énergie éolienne, grâce à la capacité de simulation prédictive validée pour le cycle de conception, permettant à l'industrie de réduire le temps de développement de moteurs et turbines efficaces[80].
Prédiction météorologique
La compréhension du climat et de ses variations passées, actuelles et à venir est l’un des enjeux scientifiques majeurs du XXIe siècle. Dans cette quête, la simulation est devenue un outil indispensable. Cette démarche permet, en effet, de mieux comprendre les mécanismes qui régulent le climat et ainsi de faire des prévisions sur des échelles de temps allant de la saison à quelques siècles, dans le cas des scénarios de changement climatique[75],[81].
En 2018, les prévisions à cinq jours étaitent aussi précises que les prévisions à quatre jours dix ans avant. Cette amélioration remarquable est possible avec une puissance de calcul d'environ cinq pétaFLOPS. Ces prévisions permettent aux gouvernements, aux secteurs public et privé de planifier et de protéger la population ou les biens. Ceci permet de réaliser des milliards de dollars d'économies chaque année[82].
L'Europe occupe la tête des prévisions météorologiques mondiales à moyenne portée depuis les années 1980[58]. United Kingdom Meteorological Office et Météo-France possèdent des supercalculateurs qui sont classés dans le TOP500[83]. Météo-France prévoit fin 2020 un supercalculateur sur la plateforme Sequana XH2000, développée par Bull (filiale du groupe Atos) d'une puissance de calcul théorique de 20,78 pétaFLOPS[84].
Les modèles de prévision météorologique exaflopique seront en mesure de prédire avec plus de précision et de rapidité le moment et la trajectoire des événements météorologiques graves tels que les ouragans. Cela sera possible grâce une résolution spatiale beaucoup plus élevée, en incorporant plus d'éléments physiques et en assimilant plus de données d'observation. Ces avancées sont essentielles pour prévoir suffisamment de temps pour les évacuations et les mesures de protection par exemple[75],[82].
L'un des objectifs est de développer une architecture de référence dans les années à venir qui permettront aux modèles météorologiques et climatiques mondiaux de fonctionner à une résolution horizontale de 1 km avec un débit de 1 SYPD (les meilleurs centres de prédiction en 2018 exécutent des simulations à une résolution spatiale de 10 à 15 km). Mal reproduits, voire absents dans les modèles climatiques existants, les phénomènes à petite échelle, qui jouent pourtant un rôle important, peuvent ainsi être pris en compte[85],[81].
Références
- Messina 2017, p. 1
- Grant 2016, p. 1
- Rigo 2017, p. 486
- Diouri 2012, p. 4
- Ashraf 2018, p. 1
- Duro 2017, p. 511
- Reed 2015, p. 60
- Reed 2015, p. 56-57
- Ashraf 2018, p. 3
- Fuller 2011, p. 31
- Kothe 2018, p. 1
- Schulthess 2018, p. 31
- Reed 2015, p. 59-60
- Dauwe 2018, p. 332
- Jensen 2010, p. 21
- Reed 2015, p. 58
- Geist 2015, p. 105
- Strohmaier 2015, p. 42-43
- Xingfu 1999, p. 114-117
- Dongarra 2003, p. 114-117
- Strohmaier 2015, p. 42-49
- Rigo 2017, p. 487
- Borkar 2011, p. 68
- Messina 2017, p. 2
- Fuller 2011, p. 32
- Theis 2017, p. 45
- Ashraf 2018, p. 2
- Ashraf 2018, p. 4
- Fuller 2011, p. 36
- Rumley 2014, p. 447-448
- Katevenis 2016, p. 61
- Ammendola 2017, p. 512
- Reed 2015, p. 63
- Pascual 2017, p. 2209.
- Geist 2015, p. 106
- Ahrens 2015, p. 8-9
- Shoukourian 2017, p. 954-955
- Shoukourian 2017, p. 955
- Geist 2015, p. 107
- Geist 2015, p. 108
- Rigo 2017, p. 488
- Shalf 2010, p. 20
- Shalf 2010, p. 20-21
- Dauwe 2018, p. 333-334
- Kogge 2013, p. 23
- Operating system Family / Linux
- Dauwe 2017, p. 1
- Fuller 2011, p. 35
- Kogge 2013, p. 25
- Reed 2015, p. 64
- Reed 2015, p. 65
- Fuller 2011, p. 34
- Reed 2015, p. 66
- Mirtaheri 2017, p. 1
- Ashraf 2018, p. 12
- Geist 2015, p. 111
- Diouri 2012, p. 2
- Schulthess 2018, p. 32
- Geist 2015, p. 104
- Geist 2015, p. 109
- Vijayaraghavan 2017, p. 1
- Fuller 2011, p. 33
- Dongarra 2011, p. 3-60
- Aurora 2019
- Intel 2019
- Frontier 2019
- energy.gov 2019
- ElCapitan 2019
- Reed 2015, p. 67
- Chine 2016
- POST-K-Japon 2019
- Vijayaraghavan 2017, p. 1-2
- Reed 2015, p. 61
- Kothe 2018, p. 9
- Messina 2017, p. 4
- Kothe 2018, p. 8-9
- Lee 2018, p. 23-24
- Reed 2015, p. 56-58
- Reed 2015, p. 62
- Kothe 2018, p. 8
- Fuhrer 2017, p. 1-2
- Schulthess 2018, p. 33
- Top500
- Météo-France
- Schulthess 2018, p. 39
Bibliographie
![]() : document utilisé comme source pour la rédaction de cet article.
: document utilisé comme source pour la rédaction de cet article.
- (en) H. Esmaeilzadeh, E. Blem, R. St. Amant, K. Sankaralingam et D. Burger, « Dark silicon and the end of multicore scaling », 2011 38th Annual International Symposium on Computer Architecture (ISCA), , p. 365-376 (ISSN 1063-6897)

- (en) P. Kogge et J. Shalf, « Exascale Computing Trends: Adjusting to the New Normal for Computer Architecture », Computing in Science & Engineering, vol. 15, no 6, , p. 16–26 (ISSN 1521-9615, DOI 10.1109/MCSE.2013.95)
- (en) A. Geist et E. Reed, « A survey of high-performance computing scaling challenges », The International Journal of HighPerformance Computing Applications 2017, vol. 31, , p. 104-113 (DOI 10.1177/1094342015597083)
- (en) S. Fuller et L. Millett, « Computing Performance: Game Over or Next Level? », Computer, vol. 44, no 1, , p. 31-38 (ISSN 0018-9162, DOI 10.1109/MC.2011.15)
- M. Diouri, O. Glück et L. Lefevre, « Vers des machines exaflopiques vertes », HAL archives-ouvertes, , p. 1-8
- (en) P. Messina, « The Exascale Computing Project », Computing in Science & Engineering, vol. 19, no 3, , p. 63-67 (ISSN 1521-9615, DOI 10.1109/MCSE.2017.57)
- (en) D. Reed et J. Dongarra, « Exascale computing and big data », Communications of the ACM, vol. 58, no 7, , p. 56-68 (ISSN 0001-0782, DOI 10.1145/2699414)
- (en) G. Kalbe, « The European Approach to the Exascale Challenge », Computing in Science & Engineering, vol. 21, no 1, , p. 42-47 (ISSN 1521-9615, DOI 10.1109/MCSE.2018.2884139)
- (en) D. Kothe, S. Lee et I. Qualters, « Exascale Computing in the United States », Computing in Science & Engineering, vol. 21, no 1, , p. 17-29 (ISSN 1521-9615, DOI 10.1109/MCSE.2018.2875366)
- (en) J. Duro, S. Petit, J. Sahuquillo et M. Gomez, « Modeling a Photonic Network for Exascale Computing », 2017 International Conference on High Performance Computing & Simulation (HPCS), (DOI 10.1109/HPCS.2017.82)
- (en) M. Borkar et A. Chien, « The future of microprocessors », Communications of the ACM, vol. 54, no 5, , p. 67-77 (ISSN 0001-0782, DOI 10.1145/1941487.1941507)
- (en) S. Mirtaheri et L. Grandinetti, « Dynamic load balancing in distributed exascale computing systems », Cluster Comput, vol. 20, no 4, , p. 3677–3689 (ISSN 1386-7857, DOI 10.1007/s10586-017-0902-8)
- (en) T. Vijayaraghavan, Y. Eckert, H. Loh, M. Schulte, M. Ignatowski, B. Beckmann, W. Brantley, J. Greathouse, W. Huang, A. Karunanithi, O. Kayiran, M. Meswani, I. Paul, M. Poremba, S. Raasch, S. Reinhardt, G. Sadowski et V. Sridharan, « Design and Analysis of an APU for Exascale Computing », 2017 IEEE International Symposium on High Performance Computer Architecture (HPCA), , p. 85-96 (ISSN 2378-203X, DOI 10.1109/HPCA.2017.42)
- (en) U. Ashraf, F. Alburaei Eassa, A. Albeshri et A. Algarni, « Performance and Power Efficient Massive Parallel Computational Model for HPC Heterogeneous Exascale Systems », IEEE Access, vol. 6, , p. 23095 - 23107 (ISSN 2169-3536, DOI 10.1109/ACCESS.2018.2823299)
- (en) R. Grant, M. Levenhagen, S. Olivier, D. DeBonis, K. Pedretti et J. Laros III, « Standardizing Power Monitoring and Control at Exascale », Computer, vol. 49, no 10, , p. 38-46 (ISSN 0018-9162, DOI 10.1109/MC.2016.308)
- (en) T. Schulthess, P. Bauer, N. Wedi, O. Fuhrer, T. Hoefler et C. Schär, « Reflecting on the Goal and Baseline for Exascale Computing: A Roadmap Based on Weather and Climate Simulations », Computing in Science & Engineering, vol. 21, no 1, , p. 30-41 (ISSN 1521-9615, DOI 10.1109/MCSE.2018.2888788)
- (en) C. Lee et R. Amaro, « Exascale Computing: A New Dawn for Computational Biology », Computing in Science & Engineering, vol. 20, no 5, , p. 18-25 (ISSN 1521-9615, DOI 10.1109/MCSE.2018.05329812)
- (en) D. Dauwe, S. Pasricha, A. Maciejewski et H. Siegel, « Resilience-Aware Resource Management for Exascale Computing Systems », IEEE Transactions on Sustainable Computing, vol. 3, no 4, , p. 332 - 345 (ISSN 2377-3782, DOI 10.1109/TSUSC.2018.2797890)
- (en) J. Dongarra, p. Luszczek et A. Petitet, « The LINPACK Benchmark: past, present and future », Concurrency and Computation: Practice and Experience, vol. 15, no 9, , p. 803–820 (DOI 10.1002/cpe.728)
- (en) M. Katevenis, N. Chrysos, M. Marazakis, I. Mavroidis, F. Chaix, N. Kallimanis, J. Navaridas, J. Goodacre, P. Vicini, A. Biagioni, P.S Paolucci, A. Lonardo, E. Pastorelli, F. Lo Cicero, R. Ammendola, P. Hopton, P. Coates, G. Taffoni, S. Cozzini, M. Kersten, Y. Zhang, J. Sahuquillo, S. Lechago, C. Pinto, B. Lietzow, D. Everett et G. Perna, « The ExaNeSt Project: Interconnects, Storage, and Packaging for Exascale Systems », IEEE, , p. 60-67 (DOI 10.1109/DSD.2016.106)
- (en) R. Ammendola, A. Biagioni, P. Cretaro, O. Frezza, F. Lo Cicero, A. Lonardo, M. Martinelli, P. Paolucci, E. Pastorelli, F. Simula, P Vicini, G. Taffoni, J. Pascual, J. Navaridas, M. Luján, J. Goodacree, N. Chrysos et M. Katevenis, « The Next Generation of Exascale-Class Systems: The ExaNeSt Project », IEEE, , p. 510-515 (DOI 10.1109/DSD.2017.20)
- (en) A. Rigo, C. Pinto, K. Pouget, D. Raho, D. Dutoit, P. Martinez, C. Doran, L. Benini, L. Mavroidis, M. Marazakis, V. Bartsch, G. Lonsdale, A. Pop, J. Goodacre, A. Colliot, P. Carpenter, P. Radojković, D. Pleiter, D. Drouin et B. Dupont de Dinechin, « Paving the Way Towards a Highly Energy-Efficient and Highly Integrated Compute Node for the Exascale Revolution: The ExaNoDe Approach », 2017 Euromicro Conference on Digital System Design (DSD), (DOI 10.1109/DSD.2017.37)
- (en) J. Dongarra, « The International Exascale Software Project roadmap », The International Journal of High Performance Computing Applications, , p. 3-60 (DOI 10.1177/1094342010391989)
- (en) D. Jensen et A. Rodrigues, « Embedded Systems and Exascale Computing », Computing in Science & Engineering, vol. 12, no 6, , p. 20-29 (ISSN 1521-9615, DOI 10.1109/MCSE.2010.95)
- (en) D. Dauwe, S. Pasricha, P. Luszczek et H. Siegel, « An Analysis of Resilience Techniques for Exascale Computing Platforms », 2017 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), (DOI 10.1109/IPDPSW.2017.41)
- (en) H. Shoukourian, T. Wilde, D. Labrenz et A. Bode, « Using Machine Learning for Data Center Cooling Infrastructure Efficiency Prediction », 2017 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), , p. 954-963 (DOI 10.1109/IPDPSW.2017.25)
- (en) T. Theis et P. Wong, « The End of Moore's Law: A New Beginning for Information Technology », Computing in Science & Engineering, vol. 19, no 2, , p. 41-50 (ISSN 1521-9615, DOI 10.1109/MCSE.2017.29)
- (en) O. Fuhrer, T. Chadha, T. Hoefler, G. Kwasniewski, X. Lapillonne, D. Leutwyler, D. Lüthi, C. Osuna, C. Schär, T. Schulthess et v. Vogt, « Near-global climate simulation at 1km resolution: establishing a performance baseline on 4888 GPUs with COSMO 5.0 », Copernicus Publications on behalf of the European Geosciences Union, (DOI 10.5194/gmd-11-1665-2018)
- (en) J. Pascual, J. Lant, A. Attwood, C. Concatto, J. Navaridas, M. Luján et J. Goodacre, « Designing an exascale interconnect using multi-objective optimization », 2017 IEEE Congress on Evolutionary Computation (CEC), , p. 85-96 (DOI 10.1109/CEC.2017.7969572)
- (en) J. Ahrens et T. Rhyne, « Increasing Scientific Data Insights about Exascale Class Simulations under Power and Storage Constraints », IEEE Computer Graphics and Applications, vol. 35, no 2, , p. 8-11 (ISSN 0272-1716, DOI 10.1109/MCG.2015.35)
- (en) E. Strohmaier, H. Meuer, J. Dongarra et H. Simon, « The TOP500 List and Progress in High-Performance Computing », Computer, vol. 48, no 11, , p. 42-49 (ISSN 0018-9162, DOI 10.1109/MC.2015.338)
- (en) S. Rumley, D. Nikolova, R. Hendry, Q. Li, D. Calhoun et K. Bergman, « Silicon Photonics for Exascale Systems », Journal of Lightwave Technology, vol. 33, no 3, , p. 547 - 562 (ISSN 0733-8724, DOI 10.1109/JLT.2014.2363947)
- (en) J. Shalf, S. Dosanjh et J. Morrison, « Exascale Computing Technology Challenges », High Performance Computing for Computational Science – VECPAR 2010, vol. 6449, , p. 1-25 (DOI https://doi.org/10.1007/978-3-642-19328-6_1)
- (en) « Performance Evaluation, Prediction and Visualization of Parallel Systems », livre, vol. 20, no 5, , p. 114–117 (ISBN 978-0-7923-8462-5, ISSN 1521-9615)
- (en) S. Som et Y. Pei, « HPC Opens a New Frontier in Fuel-Engine Research », Computing in Science & Engineering, vol. 20, no 5, , p. 77–80 (ISSN 1521-9615, DOI 10.1109/mcse.2018.05329817)
- (en) S. Borkar, « Exascale computing - A fact or a fiction? », 2013 IEEE 27th International Symposium on Parallel and Distributed Processing, , p. 3 (ISSN 1530-2075, DOI 10.1109/IPDPS.2013.121)
- (en) VECPAR, « High performance computing for computational science-- VECPAR 2012 : 10th International Conference », VECPAR,
- (en) T. Agerwala, « Exascale computing: The challenges and opportunities in the next decade », HPCA - 16 2010 The Sixteenth International Symposium on High-Performance Computer Architecture, (ISSN 1530-0897, DOI 10.1109/HPCA.2010.5416662)
- (en) M. Snir, R. Wisniewski, J. Abraham et S. Adve, « Addressing failures in exascale computing », The International Journal of High Performance Computing Applications, vol. 28, no 2, , p. 129-173 (ISSN 1094-3420, DOI 10.1177/1094342014522573)
- (en) S. Sterling et T. Sterling, « Exascale Computing [Guest Editorial] », Computing in Science & Engineering, vol. 15, no 6, , p. 12-15 (ISSN 1521-9615, DOI 10.1109/mcse.2013.122)
- (en) X. Yang, Z. Wang, J. Xue et Y. Zhou, « The Reliability Wall for Exascale Supercomputing », IEEE Transactions on Computers, vol. 61, no 6, , p. 767 - 779 (ISSN 0018-9340, DOI 10.1109/TC.2011.106)
- (en) F. Cappello, A. Geist, W. Gropp, S. Kale, B. Kramer et M. Snir, « Toward Exascale Resilience: 2014 Update », Supercomputing Frontiers and Innovations: an International Journal, , p. 1-24 (ISSN 2409-6008, DOI 10.14529/jsfi140101)
- (en) D. Dauwe, S. Pasricha, A. Maciejewski et H. Siegel, « A Performance and Energy Comparison of Fault Tolerance Techniques for Exascale Computing Systems », 2016 IEEE International Conference on Computer and Information Technology (CIT), , p. 1 - 8 (DOI 10.1109/CIT.2016.44)
- (en) G. Lapenta, S. Markidis, S. Poedts et D. Vucinic, « Space Weather Prediction and Exascale Computing », Computing in Science & Engineering, vol. 15, no 5, , p. 68-76 (ISSN 1521-9615, DOI 10.1109/MCSE.2012.86)
- (en) L. Mavroidis, L. Papaefstathiou, L. Lavagno, D. Nikolopoulos, D. Koch, J. Goodacre, L. Sourdis, V. Papaefstathiou, M. Coppola et M. Palomino, « ECOSCALE: Reconfigurable computing and runtime system for future exascale systems », IEEE, , p. 696–701 (ISSN 1558-1101)
- (en) B. Dally, « Power, Programmability, and Granularity: The Challenges of ExaScale Computing », 2011 IEEE International Parallel & Distributed Processing Symposium, (ISSN 1530-2075, DOI 10.1109/IPDPS.2011.420)
- (en) J. Dongarra, S. Tomov, P. Luszczek, J. Kurzak, M. Gates, I. Yamazaki, H. Anzt, A. Haidar et A. Abdelfattah, « With Extreme Computing, the Rules Have Changed », Computing in Science & Engineering, vol. 19, no 3, , p. 52-62 (ISSN 1521-9615, DOI 10.1109/MCSE.2017.48)
- (en) P. Balaprakash, D. Buntinas, A. Chan, A. Guha, R. Gupta, S. Narayanan, A. Chien, P. Hovland et B. Norris, « Exascale workload characterization and architecture implications », 2013 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), (DOI 10.1109/ISPASS.2013.6557153)
- (en) J. Mair, Z. Huang, D. Eyers et Y. Chen, « Quantifying the Energy Efficiency Challenges of Achieving Exascale Computing », 2015 15th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, (DOI 10.1109/CCGrid.2015.130)
- (en) J. Zounmevo, S. Perarnau, K. Iskra, K. Yoshii, R. Gioiosa, B. Van Essen, M. Gokhale et E. Leon, « A Container-Based Approach to OS Specialization for Exascale Computing », 2015 IEEE International Conference on Cloud Engineering, , p. 85-96 (DOI 10.1109/IC2E.2015.78)
- (en) S. Borkar, « The Exascale challenge », Proceedings of 2010 International Symposium on VLSI Design, Automation and Test, (DOI 10.1109/VDAT.2010.5496640)
- (en) A. Karanth Kodi, B. Neel et W. Brantley, « Photonic Interconnects for Exascale and Datacenter Architectures », IEEE Micro, vol. 35, no 5, , p. 18-30 (ISSN 0272-1732, DOI 10.1109/MM.2014.62)
- (en) A. Bar-Cohen, M. Arik et M. Ohadi, « Direct Liquid Cooling of High Flux Micro and Nano Electronic Components », Proceedings of the IEEE, vol. 94, no 8, , p. 1549 - 1570 (ISSN 0018-9219, DOI 10.1109/JPROC.2006.879791)
Liens externes
- (en) « Operating system Family / Linux » (consulté le )
- (en) « TOP500 Supercomputer » (consulté le )
- « Les supercalculateurs de Météo-France » (consulté le )
- (en) « Retooled Aurora Supercomputer Will Be America’s First Exascale System » (consulté le )
- (en) « Department of Energy, National Nuclear Security Administration and Lawrence Livermore National Laboratory announce partnership with Cray to develop NNSA’s first exascale supercomputer » (consulté le )
- (en) « US Department of Energy and Intel to Deliver First Exascale Supercomputer » (consulté le )
- (en) « UDOE’s NNSA signs $600 million contract to build its first exascale supercomputer » (consulté le )
- (en) « First U.S. Exascale Supercomputer to Be a Cray Shasta System » (consulté le )
- (en) « U.S. Department of Energy and Cray to Deliver Record-Setting Frontier Supercomputer at ORNL » (consulté le )
- (en) « China's Exascale Supercomputer Operational by 2020 » (consulté le )
- (en) « POST-K SUPERCOMPUTER DEVELOPMENT, 12/03/2019 » (consulté le )
 Portail de l’informatique
Portail de l’informatique