Logit
La fonction logit est une fonction mathématique utilisée principalement
- en statistiques et pour la régression logistique
- en inférence bayésienne pour transformer les probabilités sur [0,1] en evidence sur ℝ afin d'une part d'éviter des renormalisations permanentes, et d'autre part de rendre additive la formule de Bayes pour la plus grande commodité des calculs.

Son expression est
- où p est défini sur ]0 ; 1[

La base du logarithme utilisé est sans importance, tant que celle-ci est supérieure à 1. Le logarithme népérien (base e) est souvent choisi, mais on peut lui préférer pour mettre en évidence les ordres de grandeur décimaux le logarithme décimal (base 10 : logit(p)=-4 correspond alors à une probabilité de 10-4, etc. En fiabilité, Myron Tribus utilise une base 100.1, soit dix fois le logarithme décimal, et les nomme des décibels[1] par analogie avec les niveaux de bruit. Pour éviter toute confusion[2], Stanislas Dehaene appelle cette unité décibans dans ses cours au Collège de France, du nom inventé par Alan Turing en 1940[3], repris par d'autres auteurs[4].
Propriétés
Réciproque
Utilisée avec le logarithme népérien, la fonction logit est la réciproque de la sigmoïde :
- .

Elle est donc utilisée pour linéariser les fonctions logistiques.
Points remarquables et limites
La fonction logit étant définie sur ]0,1[, on s'intéresse aux deux points extrêmes et au point central.



Dérivée
Avec le logarithme népérien, la fonction logit est dérivable pour tout avec pour valeur :


Etant donné que, pour tout , la fonction logit est strictement croissante.

Primitives
En utilisant les propriétés du logarithme népérien et la forme de ses primitives, on montre que sa primitive qui s'annule en 0 s'écrit :

Motivation
Si p est une probabilité, cette probabilité sera toujours comprise entre 0 et 1, et donc toute tentative pour ajuster un nuage de probabilité par une droite sera invalidée par le fait que la droite n'est pas bornée. La transformation de p en p/(1-p) permet de travailler sur des valeurs variant de 0 à + ∞, puis le passage au logarithme permet de travailler sur un nuage de points dont les valeurs varient entre - ∞ et + ∞, ce qui rend possible l'approximation par une droite réelle. Sous cette forme on peut tenter un ajustement du nuage de points[5].
Historique
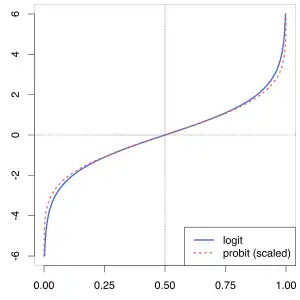


Joseph Berkson a présenté la fonction et le nom logit en 1944. Il construit le premier terme par analogie et en opposition à probit, notion développée par Chester Ittner Bliss et John Gaddum en 1934. Une distribution de fréquences en forme de S laisse penser, soit à une fonction de répartition d'une loi normale, soit à une courbe logistique. Jusqu'en 1944, le modèle de la loi normale était privilégié et la fonction pour en déterminer les paramètres était la fonction probit. Pendant plusieurs années, Berkson explique à la communauté scientifique que le modèle logit possède sa place dans l'arsenal des méthodes au même titre que le modèle probit, mais sa virulence polémique d'une part et l'habitude acquise de la loi normale d'autre part freinent puissamment l'adoption du modèle. Le développement parallèle des statistiques et de la biométrie le généralisera pourtant (1960). Actuellement, il est principalement employé dans la régression logistique[6]. Alan Turing utilise indépendamment la même fonction peu après la seconde Guerre mondiale sous le nom de log-odds[7].
La fonction logit doit en partie son succès à la moindre puissance de calcul nécessaire à son évaluation, même sans moyens informatiques[8].
Notes et références
- (en) Myron Tribus, Rational Descriptions, Decisions and Designs, Pergamon Press, (lire en ligne), réimprimé en 1999, Expira Press, (ISBN 9789197363303).
- Le décibel est le logarithme base 0,1 du rapport entre deux puissances.
- (en) Irving John Good, « Studies in the History of Probability and Statistics. XXXVII A. M. Turing's statistical work in World War II », Biometrika, vol. 66, no 2, , p. 393–396 (DOI 10.1093/biomet/66.2.393, Math Reviews 0548210).
- (en) F.L. Bauer, Decrypted secrets : Methods and maxims of cryptology, Berlin, Springer, (lire en ligne), p. 239 ; (en) David J. MacKay, Information Theory, Inference and Learning Algorithms, Cambridge University Press, , p. 265
- La méthode des moindres carrés ne s'imposera pas nécessairement pour autant, les points n'étant pas nécessairement de représentativité ni de poids comparables
- (en) J.S. Cramer, « The origins and development of the logit model », sur cambridge.org (université de Cambridge), p. 8sq.
- Stanislas Dehaene, « Introduction au raisonnement Bayésien et à ses applications », .
- Cramer, p. 11.
 Portail des probabilités et de la statistique
Portail des probabilités et de la statistique