Arbre de décision (apprentissage)
L’apprentissage par arbre de décision désigne une méthode basée sur l'utilisation d'un arbre de décision comme modèle prédictif. On l'utilise notamment en fouille de données et en apprentissage automatique.
Dans ces structures d'arbre, les feuilles représentent les valeurs de la variable-cible et les embranchements correspondent à des combinaisons de variables d'entrée qui mènent à ces valeurs. En analyse de décision, un arbre de décision peut être utilisé pour représenter de manière explicite les décisions réalisées et les processus qui les amènent. En apprentissage et en fouille de données, un arbre de décision décrit les données mais pas les décisions elles-mêmes, l'arbre serait utilisé comme point de départ au processus de décision.
C'est une technique d'apprentissage supervisé : on utilise un ensemble de données pour lesquelles on connaît la valeur de la variable-cible afin de construire l'arbre (données dites étiquetées), puis on extrapole les résultats à l'ensemble des données de test. Les arbres de décision font partie des algorithmes les plus populaires en apprentissage automatique[1],[2].
Généralités
L'apprentissage par arbre de décision est une méthode classique en apprentissage automatique [3]. Son but est de créer un modèle qui prédit la valeur d'une variable-cible depuis la valeur de plusieurs variables d'entrée.
Une des variables d'entrée est sélectionnée à chaque nœud intérieur (ou interne, nœud qui n'est pas terminal) de l'arbre selon une méthode qui dépend de l'algorithme et qui sera discutée plus loin. Chaque arête vers un nœud-fils correspond à un ensemble de valeurs d'une variable d'entrée, de manière que l'ensemble des arêtes vers les nœuds-fils couvrent toutes les valeurs possibles de la variable d'entrée.
Chaque feuille (ou nœud terminal de l'arbre) représente soit une valeur de la variable-cible, soit une distribution de probabilité des diverses valeurs possibles de la variable-cible. La combinaison des valeurs des variables d'entrée est représentée par le chemin de la racine jusqu'à la feuille.
L'arbre est en général construit en séparant l'ensemble des données en sous-ensembles en fonction de la valeur d'une caractéristique d'entrée. Ce processus est répété sur chaque sous-ensemble obtenu de manière récursive, il s'agit donc d'un partitionnement récursif.
La récursion est achevée à un nœud soit lorsque tous les sous-ensembles ont la même valeur de la caractéristique-cible, ou lorsque la séparation n'améliore plus la prédiction. Ce processus est appelé induction descendante d'arbres de décision (top-down induction of decision trees ou TDIDT)[4], c'est un algorithme glouton puisqu'on recherche à chaque nœud de l'arbre le partage optimal, dans le but d'obtenir le meilleur partage possible sur l'ensemble de l'arbre de décision. C'est la stratégie la plus commune pour apprendre les arbres de décision depuis les données.
En fouille de données, les arbres de décision peuvent aider à la description, la catégorisation ou la généralisation d'un jeu de données fixé.
L'ensemble d'apprentissage est généralement fourni sous la forme d'enregistrements du type :

La variable désigne la variable-cible que l'on cherche à prédire, classer ou généraliser. Le vecteur est constitué des variables d'entrée etc. qui sont utilisées dans ce but.



Types
Il existe deux principaux types d'arbre de décision en fouille de données :
- Les arbres de classification (Classification Tree) permettent de prédire à quelle classe la variable-cible appartient, dans ce cas la prédiction est une étiquette de classe,
- Les arbres de régression (Regression Tree) permettent de prédire une quantité réelle (par exemple, le prix d'une maison ou la durée de séjour d'un patient dans un hôpital), dans ce cas la prédiction est une valeur numérique.
Le terme d'analyse d'arbre de classification et de régression (CART, d'après l'acronyme anglais) est un terme générique se référant aux procédures décrites précédemment et introduites par Breiman et al.[5]. Les arbres utilisés dans le cas de la régression et dans le cas de la classification présentent des similarités mais aussi des différences, en particulier en ce qui concerne la procédure utilisée pour déterminer les séparations des branches.
Construction d'un arbre de décision
L'apprentissage par arbre de décision consiste à construire un arbre depuis un ensemble d'apprentissage constitué de n-uplets étiquetés. Un arbre de décision peut être décrit comme un diagramme de flux de données (ou flowchart) où chaque nœud interne décrit un test sur une variable d'apprentissage, chaque branche représente un résultat du test, et chaque feuille contient la valeur de la variable cible (une étiquette de classe pour les arbres de classification, une valeur numérique pour les arbres de régression).
Critère de segmentation
Usuellement, les algorithmes pour construire les arbres de décision sont construits en divisant l'arbre du sommet vers les feuilles en choisissant à chaque étape une variable d'entrée qui réalise le meilleur partage de l'ensemble d'objets, comme décrit précédemment[6]. Pour choisir la variable de séparation sur un nœud, les algorithmes testent les différentes variables d'entrée possibles et sélectionnent celle qui maximise un critère donné.
Cas des arbres de classification
Dans le cas des arbres de classification, il s'agit d'un problème de classification automatique. Le critère d’évaluation des partitions caractérise l'homogénéité (ou le gain en homogénéité) des sous-ensembles obtenus par division de l'ensemble. Ces métriques sont appliquées à chaque sous-ensemble candidat et les résultats sont combinés (par exemple, moyennés) pour produire une mesure de la qualité de la séparation.
Il existe un grand nombre de critères de ce type, les plus utilisés sont l’entropie de Shannon, l'indice de diversité de Gini et leurs variantes.
- Indice de diversité de Gini : utilisé par l'algorithme CART, il mesure avec quelle fréquence un élément aléatoire de l'ensemble serait mal classé si son étiquette était choisie aléatoirement selon la distribution des étiquettes dans le sous-ensemble. L'indice de diversité de Gini peut être calculé en sommant la probabilité pour chaque élément d'être choisi, multipliée par la probabilité qu'il soit mal classé. Il atteint sa valeur minimum (zéro) lorsque tous les éléments de l'ensemble sont dans une même classe de la variable-cible. Pratiquement, si l'on suppose que la classe prend une valeur dans l'ensemble , et si désigne la fraction des éléments de l'ensemble avec l'étiquette dans l'ensemble, on aura :




- Gain d'information : utilisé par les algorithmes ID3 et C4.5, le gain d'information est basé sur le concept d'entropie de Shannon en théorie de l'information [2]. L'entropie permet de mesurer le désordre dans un ensemble de données et est utilisée pour choisir la valeur permettant de maximiser le gain d'information. En utilisant les mêmes notations que pour l'indice de diversité de Gini, on obient la formule suivante :

Cas des arbres de régression
Dans le cas des arbres de régression, le même schéma de séparation peut être appliqué, mais au lieu de minimiser le taux d’erreur de classification, on cherche à maximiser la variance inter-classes (avoir des sous-ensembles dont les valeurs de la variable-cible soient les plus dispersées possibles). En général, le critère utilise le test du chi carré.
Remarques
Certains critères permettent de prendre en compte le fait que la variable-cible prend des valeurs ordonnées, en utilisant des mesures ou des heuristiques appropriées[7].
Chaque ensemble de valeurs de la variable de segmentation permet de produire un nœud-fils. Les algorithmes d’apprentissage peuvent différer sur le nombre de nœud-fils produits : certains (tels que CART) produisent systématiquement des arbres binaires, et cherchent donc la partition binaire qui optimise le critère de segmentation. D’autres (comme CHAID) cherchent à effectuer les regroupements les plus pertinents en s’appuyant sur des critères statistiques. Selon la technique, nous obtiendrons des arbres plus ou moins larges. Pour que la méthode soit efficace, il faut éviter de fractionner exagérément les données afin de ne pas produire des groupes d’effectifs trop faibles, ne correspondant à aucune réalité statistique.
Traitement des variables continues
Dans le cas de variables de segmentation continues, le critère de segmentation choisi doit être adéquate. En général, on trie les données selon la variable à traiter, puis on teste les différents points de coupure possibles en évaluant le critère pour chaque cas, le point de coupure optimal sera celui qui maximise le critère de segmentation.
Définir la taille de l’arbre
Il n'est pas toujours souhaitable en pratique de construire un arbre dont les feuilles correspondent à des sous-ensembles parfaitement homogènes du point de vue de la variable-cible. En effet, l'apprentissage est réalisé sur un échantillon que l'on espère représentatif d’une population. L'enjeu de toute technique d'apprentissage est d'arriver à saisir l'information utile sur la structure statistique de la population, en excluant les caractéristiques spécifiques au jeu de données étudié. Plus le modèle est complexe (plus l'arbre est grand, plus il a de branches, plus il a de feuilles), plus l'on court le risque de voir ce modèle incapable d'être extrapolé à de nouvelles données, c'est-à-dire de rendre compte de la réalité que l'on cherche à appréhender.
En particulier, dans le cas extrême où l'arbre a autant de feuilles qu'il y a d'individus dans la population (d'enregistrements dans le jeu de données), l'arbre ne commet alors aucune erreur sur cet échantillon puisqu'il en épouse toutes les caractéristiques, mais il n'est pas généralisable à un autre échantillon. Ce problème, nommé surapprentissage ou surajustement (overfitting), est un sujet classique de l'apprentissage automatique et de la fouille de données.
On cherche donc à construire un arbre qui soit le plus petit possible en assurant la meilleure performance possible. Suivant le principe de parcimonie, plus un arbre sera petit, plus il sera stable dans ses prévisions futures. Il faut réaliser un arbitrage entre performance et complexité dans les modèles utilisés. À performance comparable, on préférera toujours le modèle le plus simple, si l'on souhaite pouvoir utiliser ce modèle sur de nouveaux échantillons.
Le problème du surajustement des modèles
Pour réaliser l'arbitrage performance/complexité des modèles utilisés, on évalue la performance d'un ou de plusieurs modèles sur les données qui ont servi à sa construction (le ou les échantillons d'apprentissage), mais également sur un (ou plusieurs) échantillon(s) de validation : des données étiquetées à disposition mais que l'on décide volontairement de ne pas utiliser dans la construction des modèles.
Ces données sont traitées comme les données de test, la stabilité de la performance des modèles sur ces deux types d'échantillon permettra de juger de son surajustement et donc de sa capacité à être utilisé avec un risque d'erreur maîtrisé dans des conditions réelles où les données ne sont pas connues à l'avance.
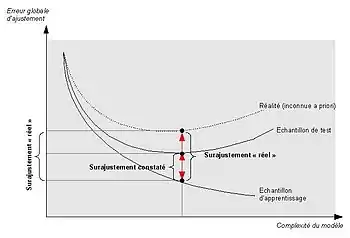
Dans le graphique ci-contre, nous observons l’évolution de l’erreur d’ajustement d'un arbre de décision en fonction du nombre de feuilles de l’arbre (qui mesure ici la complexité). Nous constatons que si l’erreur décroît constamment sur l’échantillon d’apprentissage, à partir d'un certain niveau de complexité, le modèle s'éloigne de la réalité, réalité que l’on cherche à estimer sur l'échantillon de validation (appelé échantillon de test dans le graphique).
Dans le cas des arbres de décisions, plusieurs types de solutions algorithmiques ont été envisagées pour tenter d'éviter autant que possible le surapprentissage des modèles : les techniques de pré- ou de post-élagage des arbres.
Certaines théories statistiques cherchent à trouver l'optimum entre l'erreur commise sur l'échantillon d'apprentissage et celle commise sur l'échantillon de test. La théorie de Vapnik-Chervonenkis Structured Risk Minimization (ou SRM), utilise une variable appelée dimension VC, pour déterminer l’optimum d’un modèle. Elle est utilisable par conséquent pour générer des modèles qui assurent le meilleur compromis entre qualité et robustesse du modèle.
Ces solutions algorithmiques sont complémentaires des analyses de performances comparées et de stabilité effectuées sur les échantillons d'apprentissage et de validation.
Le pré-élagage
La première stratégie utilisable pour éviter un surapprentissage des arbres de décision consiste à proposer des critères d’arrêt lors de la phase d’expansion. C’est le principe du pré-élagage. Lorsque le groupe est d’effectif trop faible, ou lorsque l'homogénéité d'un sous-ensemble a atteint un niveau suffisant, on considère qu’il n’est plus nécessaire de séparer l'échantillon. Un autre critère souvent rencontré dans ce cadre est l’utilisation d’un test statistique pour évaluer si la segmentation introduit un apport d’informations significatif pour la prédiction de la variable-cible.
Le post-élagage
La seconde stratégie consiste à construire l’arbre en deux temps : on produit d'abord l’arbre dont les feuilles sont le plus homogènes possibles dans une phase d’expansion, en utilisant une première fraction de l’échantillon de données (échantillon d’apprentissage à ne pas confondre avec la totalité de l’échantillon, appelé en anglais growing set pour lever l'ambiguïté), puis on réduit l’arbre, en s’appuyant sur une autre fraction des données de manière à optimiser les performances de l’arbre, c’est la phase de post-élagage. Selon les cas, cette seconde portion des données est désignée par le terme d’échantillon de validation ou échantillon de test, introduisant une confusion avec l’échantillon utilisé pour mesurer les performances des modèles. Le terme d'échantillon d’élagage permet de le désigner sans ambiguïté, c'est la traduction directe de l’appellation anglaise pruning set.
Problème des données incomplètes
Les données à disposition sont souvent incomplètes, dans le sens où l'on ne dispose que d'une partie des variables d'entrée pour un enregistrement. Plusieurs possibilités sont envisageables dans ce cas :
- Les ignorer : cela n'est possible que si l'échantillon de données est suffisamment grand pour supprimer des individus (c'est-à-dire des lignes d'enregistrements) du jeu de données, et que si l'on est sûr que lorsque l'arbre de décision sera utilisé en pratique, toutes les données seront toujours disponibles pour tous les individus.
- Les remplacer par une valeur calculée jugée adéquate (on parle d'imputation de valeurs manquantes) : cette technique est parfois utilisée en statistique mais au-delà des problèmes purement mathématiques, elle est contestable du point de vue méthodologique.
- Utiliser des variables substituts : cela consiste, pour un individu qui aurait une donnée manquante pour une variable sélectionnée par l'arbre comme étant discriminante, à utiliser la variable qui parmi l'ensemble des variables disponibles dans la base de données produit localement les feuilles les plus similaires aux feuilles produites par la variable dont la donnée est manquante, on appelle alors cette variable un substitut. Si un individu a une valeur manquante pour la variable initiale, mais aussi pour la variable substitut, on peut utiliser une deuxième variable substitut. Et ainsi de suite, jusqu'à la limite d'un critère de qualité du substitut. Cette technique a l'avantage d'exploiter l'ensemble de l'information disponible (cela est donc très utile lorsque cette information est complexe à récupérer) pour chaque individu.
Affectation de la conclusion sur chaque feuille
Dans le cas des arbres de classification, il faut préciser la règle d’affectation dans les feuilles une fois l’arbre construit. Si les feuilles sont homogènes, il n'y a pas d'ambiguïté. Si ce n’est pas le cas, une règle simple consiste à décider de la classe de la feuille en fonction de la classe majoritaire, celle qui est la plus représentée.
Cette technique très simple est optimale dans le cas où les données sont issues d’un tirage aléatoire non-biasé dans la population ; la matrice des coûts de mauvaise affectation est unitaire (symétrique) : affecter à bon escient à un coût nul, et affecter à tort coûte 1 quel que soit le cas de figure. En dehors de ce cadre, la règle de la majorité n’est pas nécessairement justifiée mais est facile à utiliser dans la pratique.
Amélioration des performances
Méthodes d'ensembles
Certaines techniques, appelées méthodes d'ensembles (ensemble methods), améliorent la qualité ou la fiabilité de la prédiction en construisant plusieurs arbres de décision depuis les données :
- L'ensachage (bagging ou bootstrap aggregating), une des premières méthodes historiquement, selon laquelle on construit plusieurs arbres de décision en ré-échantillonnant l'ensemble d'apprentissage, puis en construisant les arbres par une procédure de consensus[8].
- La classification par forêts d'arbres aléatoires de Breiman.
- La classification par rotation de forêts d'arbres de décision, dans laquelle on applique d'abord une analyse en composantes principales (PCA) sur un ensemble aléatoire des variables d'entrée[11].
Combinaisons à d'autres techniques
Les arbres de décision sont parfois combinés entre eux ou à d'autres techniques d'apprentissage : analyse discriminante, régressions logistiques, régressions linéaires, réseaux de neurones (perceptron multicouche, radial basis function network) ou autres.
Des procédures d'agrégation des performances des différents modèles utilisés (telles que les décisions par consensus), sont mises en place pour obtenir une performance maximale, tout en contrôlant le niveau de complexité des modèles utilisés.
Avantages et inconvénients de la méthode
Avantages
Comparativement à d'autres méthodes de fouille de données, les arbres de décision présentent plusieurs avantages :
- La simplicité de compréhension et d'interprétation. C'est un modèle boîte blanche : si l'on observe une certaine situation sur un modèle, celle-ci peut-être facilement expliquée à l'aide de la logique booléenne, au contraire de modèles boîte noire comme les réseaux neuronaux, dont l'explication des résultats est difficile à comprendre.
- Peu de préparation des données (pas de normalisation, de valeurs vides à supprimer, ou de variable muette).
- Le modèle peut gérer à la fois des valeurs numériques et des catégories. D'autres techniques sont souvent spécialisées sur un certain type de variables (les réseaux neuronaux ne sont utilisables que sur des variables numériques).
- Il est possible de valider un modèle à l'aide de tests statistiques, et ainsi de rendre compte de la fiabilité du modèle.
- Performant sur de grands jeux de données: la méthode est relativement économique en termes de ressources de calcul.
Inconvénients
En revanche, elle présente certains inconvénients :
- L'apprentissage de l'arbre de décision optimal est NP-complet concernant plusieurs aspects de l'optimalité[12],[13]. En conséquence, les algorithmes d'apprentissage par arbre de décision sont basés sur des heuristiques telles que les algorithmes gloutons cherchant à optimiser le partage à chaque nœud, et de tels algorithmes ne garantissent pas d'obtenir l'optimum global. Certaines méthodes visent à diminuer l'effet de la recherche gloutonne [14].
- L'apprentissage par arbre de décision peut amener des arbres de décision très complexes, qui généralisent mal l'ensemble d'apprentissage (il s'agit du problème de surapprentissage précédemment évoqué[15]). On utilise des procédures d'élagage pour contourner ce problème, certaines approches comme l'inférence conditionnelle permettent de s'en affranchir[16],[17].
- Certains concepts sont difficiles à exprimer à l'aide d'arbres de décision (comme XOR ou la parité). Dans ces cas, les arbres de décision deviennent extrêmement larges. Pour résoudre ce problème, plusieurs moyens existent, tels que la proportionnalisation[18], ou l'utilisation d'algorithmes d'apprentissage utilisant des représentations plus expressives (par exemple la programmation logique inductive).
Extensions
Les graphes de décision
Dans un arbre de décision, tous les chemins depuis la racine jusqu'aux feuilles utilisent le connecteur AND. Dans un graphe de décision, on peut également utiliser le connecteur OR pour connecter plusieurs chemins à l'aide du Minimum message length (MML)[20]. En général les graphes de décision produisent des graphes avec moins de feuilles que les arbres de décision.
Méthodes de recherche alternatives
Des algorithmes évolutionnistes sont utilisés pour éviter les séparations amenant à des optimum locaux[21],[22].
On peut également échantillonner l'arbre en utilisant des méthodes MCMC dans un paradigme bayésien[23].
L'arbre peut être construit par une approche ascendante (du bas vers le haut)[24].
Algorithmes classiques
On dénombre plusieurs algorithmes pour construire des arbres de décision, parmi lesquels :
- ID3 (Iterative Dichotomiser 3)
- C4.5, C5 (successeurs d'ID3)
- CHAID (CHi-squared Automatic Interaction Detector) [25]
- Exhaustive CHAID
- CART (Classification And Regression Tree)
- SLIQ
- QUEST
- VFDT
- UFFT
- MARS
- Conditional Inference Trees. Une méthode statistique basée sur l'utilisation de tests non-paramétriques comme critère de séparation[16],[17].
ID3 et CART ont été inventées de manière indépendante dans les décennies 1970-1980, mais utilisent des approches similaires pour apprendre des arbres de décision depuis l'ensemble d'apprentissage.
Tous ces algorithmes se distinguent par le ou les critères de segmentation utilisés, par les méthodes d'élagages implémentées, par leur manière de gérer les données manquantes dans les prédicteurs.
Implémentations
Beaucoup de logiciels de fouille de données proposent des bibliothèques permettant d'implémenter un ou plusieurs algorithmes d'apprentissage par arbre de décision. Par exemple, le logiciel Open Source R contient plusieurs implémentations de CART, telles que rpart, party et randomForest, les logiciels libres Weka et Orange (et son module orngTree) ou encore la bibliothèque libre Python scikit-learn ; mais également Salford Systems CART, IBM SPSS Modeler, RapidMiner, SAS Enterprise Miner, KNIME, Microsoft SQL Server .
Notes
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Decision Tree Learning » (voir la liste des auteurs).
- (en) Xindong Wu, Vipin Kumar, J. Ross Quinlan et Joydeep Ghosh, « Top 10 algorithms in data mining », Knowledge and Information Systems, vol. 14, no 1, , p. 1–37 (ISSN 0219-1377 et 0219-3116, DOI 10.1007/s10115-007-0114-2, lire en ligne, consulté le ).
- (en) S. Madeh Piryonesi et Tamer E. El-Diraby, « Data Analytics in Asset Management: Cost-Effective Prediction of the Pavement Condition Index », Journal of Infrastructure Systems, vol. 26, no 1, , p. 04019036 (ISSN 1076-0342 et 1943-555X, DOI 10.1061/(ASCE)IS.1943-555X.0000512, lire en ligne, consulté le ).
- (en) Lior Rokach, Data mining with decision trees : theory and applications, Hackensack (NJ), World Scientific Pub Co Inc, , 244 p. (ISBN 978-981-27-7171-1, notice BnF no FRBNF41351943).
- Quinlan, J. R., (1986). Induction of Decision Trees. Machine Learning 1: 81-106, Kluwer Academic Publishers.
- Leo Breiman, Classification and regression trees, Monterey, CA, Wadsworth & Brooks/Cole Advanced Books & Software, , 368 p. (ISBN 978-0-412-04841-8).
- L. Rokach et O. Maimon, « Top-down induction of decision trees classifiers-a survey », IEEE Transactions on Systems, Man, and Cybernetics, Part C, vol. 35, no 4, , p. 476–487 (DOI 10.1109/TSMCC.2004.843247).
- Des heuristiques sont notamment utilisées lorsque l'on cherche à réduire la complexité de l'arbre en agrégeant les modalités des variables utilisées comme prédicteurs de la cible. Par exemple, pour le cas des modalités d'une variable de classes d'âge, on ne va autoriser que des regroupements de classes d'âge contiguës.
- Breiman, L. (1996). Bagging Predictors. "Machine Learning, 24": p. 123-140.
- Friedman, J. H. (1999). Stochastic gradient boosting. Stanford University.
- Hastie, T., Tibshirani, R., Friedman, J. H. (2001). The elements of statistical learning : Data mining, inference, and prediction. New York: Springer Verlag.
- Rodriguez, J.J. and Kuncheva, L.I. and Alonso, C.J. (2006), Rotation forest: A new classifier ensemble method, IEEE Transactions on Pattern Analysis and Machine Intelligence, 28(10):1619-1630.
- Laurent Hyafil et RL Rivest, « Constructing Optimal Binary Decision Trees is NP-complete », Information Processing Letters, vol. 5, no 1, , p. 15–17 (DOI 10.1016/0020-0190(76)90095-8).
- Murthy S. (1998). Automatic construction of decision trees from data: A multidisciplinary survey. Data Mining and Knowledge Discovery
- Ben-Gal I. Dana A., Shkolnik N. and Singer: "Efficient Construction of Decision Trees by the Dual Information Distance Method". Quality Technology & Quantitative Management (QTQM), 11( 1), 133-147. (disponible en ligne en Anglais PDF)
- DOI:10.1007/978-1-84628-766-4.
- T. Hothorn, K. Hornik et A. Zeileis, « Unbiased Recursive Partitioning: A Conditional Inference Framework », Journal of Computational and Graphical Statistics, vol. 15, no 3, , p. 651–674 (DOI 10.1198/106186006X133933, JSTOR 27594202).
- C. Strobl, J. Malley et G. Tutz, « An Introduction to Recursive Partitioning: Rationale, Application and Characteristics of Classification and Regression Trees, Bagging and Random Forests », Psychological Methods, vol. 14, no 4, , p. 323–348 (DOI 10.1037/a0016973).
- DOI:10.1007/b13700.
- Deng,H., Runger, G.; Tuv, E. (2011). « Bias of importance measures for multi-valued attributes and solutions » dans Proceedings of the 21st International Conference on Artificial Neural Networks (ICANN) : 293–300 p...
- http://citeseer.ist.psu.edu/oliver93decision.html
- Papagelis A., Kalles D.(2001). Breeding Decision Trees Using Evolutionary Techniques, Proceedings of the Eighteenth International Conference on Machine Learning, p. 393-400, June 28-July 01, 2001
- Barros, Rodrigo C., Basgalupp, M. P., Carvalho, A. C. P. L. F., Freitas, Alex A. (2011). A Survey of Evolutionary Algorithms for Decision-Tree Induction. IEEE Transactions on Systems, Man and Cybernetics, Part C: Applications and Reviews, vol. 42, n. 3, p. 291-312, May 2012.
- Chipman, Hugh A., Edward I. George, and Robert E. McCulloch. "Bayesian CART model search." Journal of the American Statistical Association 93.443 (1998): 935-948.
- Barros R. C., Cerri R., Jaskowiak P. A., Carvalho, A. C. P. L. F., A bottom-up oblique decision tree induction algorithm. Proceedings of the 11th International Conference on Intelligent Systems Design and Applications (ISDA 2011).
- G. V. Kass, « An exploratory technique for investigating large quantities of categorical data », Applied Statistics, vol. 29, no 2, , p. 119–127 (DOI 10.2307/2986296, JSTOR 2986296).
Références
- L. Breiman, J. Friedman, R. Olshen, C. Stone: CART: Classification and Regression Trees, Wadsworth International, 1984.
- R. Quinlan: C4.5: Programs for Machine Learning, Morgan Kaufmann Publishers Inc., 1993.
- D. Zighed, R. Rakotomalala: Graphes d'Induction -- Apprentissage et Data Mining, Hermes, 2000.
- Daniel T. Larose (adaptation française T. Vallaud): Des données à la connaissance : Une introduction au data-mining (1Cédérom), Vuibert, 2005.
Articles connexes
Voir aussi
Liens externes
 Portail de l'informatique théorique
Portail de l'informatique théorique