Algorithme de Cocke-Younger-Kasami
En informatique théorique et en théorie des langages, l'algorithme de Cocke-Younger-Kasami (CYK) est un algorithme d'analyse syntaxique pour les grammaires non contextuelles, publié par Itiroo Sakai en 1961[1],[2]. Il permet de déterminer si un mot est engendré par une grammaire, et si oui, d'en donner un arbre syntaxique. L'algorithme est nommé d'après les trois personnes qui l'ont redécouvert indépendamment, J. Cocke, dont l'article n'a jamais été publié[3], D. H. Younger[4] et T. Kasami qui a publié un rapport interne aux US-AirForce[5].
Pour les articles homonymes, voir CKY.
L'algorithme opère par analyse ascendante et emploie la programmation dynamique. L'algorithme suppose que la grammaire est en forme normale de Chomsky. Cette restriction n'est pas gênante dans la mesure où toute grammaire non contextuelle admet une grammaire en forme normale de Chomsky équivalente[6]. Le temps de calcul de cet algorithme est en , où est la longueur du mot à analyser et est la taille de la grammaire.




Principe
Sans perte de généralité, on suppose que la grammaire n'engendre pas le mot vide . Ainsi, on peut supposer que la grammaire est sous forme normale de Chomsky et qu'elle ne contient pas de règles de la forme (on parle de grammaire propre, voir grammaire non contextuelle).



Soit un mot non vide à analyser. L'algorithme emploie la programmation dynamique. Les sous-problèmes sont les suivants : est l'ensemble des non-terminaux qui engendrent le mot pour tout tels que où est la longueur du mot .




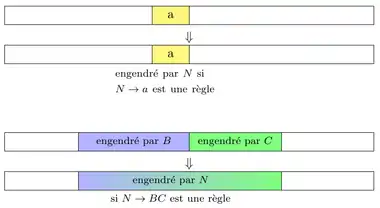
On peut calculer les ensembles par récurrence sur .

- Cas de base : est l'ensemble des non-terminaux tel que est une règle de la grammaire.
- Cas récursif : Si , est l'ensemble des non-terminaux tels qu'il existe une règle où et sont des non-terminaux et un entier tels que est dans et est dans .










La figure à droite montre le cas de base et le cas récursif.
On en déduit un algorithme de programmation dynamique qui calcule tous les ensembles . Le mot est engendré par la grammaire si et seulement si est dans où est l'axiome de la grammaire et est la longueur du mot .


Exemple
Considérons la grammaire suivante en forme normale de Chomsky :

où l'ensemble des non-terminaux est et l'ensemble des terminaux (lettres) est . Ici, « elle » s'appelle une lettre (bien que c'est un mot) et une phrase comme « elle mange du poisson avec une fourchette » s'appelle un mot.


Maintenant, analysons le mot qui est la phrase « elle mange du poisson avec une fourchette » avec l'algorithme CYK. Dans la table suivante, on indique les valeurs de :
| P[1, 7] = {S} | ||||||
| P[1, 6] = ø | P[2, 7] = {GV} | |||||
| P[1, 5] = ø | P[2, 6] = ø | P[3, 7] = ø | ||||
| P[1, 4] = S | P[2, 5] = ø | P[3, 6] = ø | P[4, 7] = ø | |||
| P[1, 3] = ø | P[2, 4] = {GV} | P[3, 5] = ø | P[4, 6] = ø | P[5, 7] = {C} | ||
| P[1, 2] = {S} | P[2, 3] = ø | P[3, 4] = {GN} | P[4, 5] = ø | P[5, 6] = ø | P[6, 7] = {GN} | |
| P[1, 1] = {GN} | P[2, 2] = {V, GV} | P[3, 3] = {Det} | P[4, 4] = {N} | P[5, 5] = {P} | P[6, 6] = {Det} | P[7, 7] = {N} |
| elle | mange | du | poisson | avec | une | fourchette |
Le mot « elle mange du poisson avec une fourchette » est reconnu car l'axiome est dans .

Pseudo-code
Voici un pseudo-code inspiré de l'analyse de la section précédente :
Pour i = 1 à := ensemble des non-terminaux tel que est une règle de la grammaire Pour d = 1 à Pour i = 1 à -d j := i+d := ensemble des non-terminaux tels qu'il existe une règle et un entier tels que est dans et est dans Retourne oui si est dans ; non sinon.

On peut donner un pseudo-code qui montre la complexité cubique en :
Pour i = 1 à := ensemble des non-terminaux tel que est une règle de la grammaire Pour d = 1 à Pour i = 1 à -d j := i+d := ensemble vide Pour tout k = i à j-1 Pour tout est dans et est dans Pour tout non-terminal tel que est une règle Ajouter à Retourne oui si est dans ; non sinon.
Discussions
Grammaires pondérées
Si la grammaire est pondérée, l'algorithme de CYK permet de générer l'arbre le plus lourd qui engendre la phrase[7],[8].
Intérêt de la mise en forme normale de Chomsky
La restriction qui consiste à avoir une grammaire en forme normale de Chomsky est essentiellement esthétique et Lange et Leiß [9] discutent une variante de l'algorithme CYK avec des restrictions plus faibles.
Lien avec la multiplication de matrices
L'algorithme CYK est en , où est la longueur du mot à analyser et est la taille de la grammaire en forme normale de Chomsky. Valiant[10] donne une extension de l'algorithme CYK en en adaptant l'algorithme de Strassen sur les matrices.


En utilisant l'algorithme de Coppersmith-Winograd[11] pour multiplier les matrices, on atteint une complexité asymptotique de . Mais la constante cachée dans la notation grand O fait que l'algorithme n'a pas d'intérêt en pratique[12]. La dépendance sur un algorithme efficace pour multiplier des matrices ne peut pas être évitée dans le sens suivant : Lee[13] a montré que l'on peut construire un algorithme pour multiplier des matrices 0-1 de taille en temps à partir d'un analyseur pour des grammaires non contextuelles en .




Démonstrations
Notes et références
- (en) Itiroo Sakai, « Syntax in universal translation », dans 1961 International Conference on Machine Translation of Languages and Applied Language Analysis, Teddington, England, vol. II, London, Her Majesty’s Stationery Office, , p. 593-608.
- (en) Dick Grune, Parsing techniques: a practical guide, New York, Springer, , 2e éd. (ISBN 978-0-387-20248-8), p. 579.
- D'apres Hopcroft, Motwani et Ullman, le travail de J. Cocke, bien qu’il ait circulé de façon privée, n’a jamais été publié.
- D. H. Younger, « Recognition and parsing of context-free languanges in time n3 », Information and Control, vol. 10, no 2, , p. 189-208.
- T. Kasami, « An efficient recognition and syntax-analysis algorithm for context-free languages », Science Report AFCRL-65-758, Bedford, Mass., Air Force Cambridge Research Laboratory, .
- (en) Sipser, Michael, Introduction to the Theory of Computation (1st ed.), (ISBN 978-0-534-94728-6).
- Víctor M. Jiménez et Andrés Marzal, « Computation of the N Best Parse Trees for Weighted and Stochastic Context-Free Grammars », Advances in Pattern Recognition, Springer Science + Business Media, , p. 183-192 (ISBN 978-3-540-67946-2, ISSN 0302-9743, DOI 10.1007/3-540-44522-6_19, lire en ligne).
- Xian Chen, « Weighted-CYK-Probabilistic-Context-Free-Grammar », sur GitHub, .
- Martin Lange, Hans Leiß, « To CNF or not to CNF? An Efficient Yet Presentable Version of the CYK Algorithm », Informatica Didactica 8, 2009.
- « General context-free recognition in less than cubic time », sur www.sciencedirect.com (DOI 10.1016/S0022-0000(75)80046-8, consulté le ).
- Don Coppersmith and Shmuel Winograd. Matrix multiplication via arithmetic progressions. Proceedings of the Nineteenth Annual ACM Symposium on Theory of Computing, pages 1–6, 1987.
- (en) Donald Knuth, The Art of Computer Programming Volume 2 : Seminumerical Algorithms (3rd ed.). Addison-Wesley Professional. p. 501., Reading (Mass.), Addison-Wesley, 762 p. (ISBN 978-0-201-89684-8, notice BnF no FRBNF37532795).
- Lillian Lee, « Fast Context-free Grammar Parsing Requires Fast Boolean Matrix Multiplication », J. ACM, vol. 49, , p. 1–15 (ISSN 0004-5411, DOI 10.1145/505241.505242, lire en ligne, consulté le ).
Bibliographie
L'algorithme est exposé dans les ouvrages théoriques sur les langages formels.
- Alfred Aho, Monica Lam, Ravi Sethi et Jeffrey Ullman, Compilateurs : principes, techniques et outils : avec plus de 200 exercices, Paris, Pearson, , 2e éd., 928 p. (ISBN 978-2-7440-7037-2 et 2744070378, notice BnF no FRBNF41172860) — Exercice 4.4.9 du Dragon book.
- (de) Katrin Erk et Lutz Priese, Theoretische Informatik : Eine umfassende Einführung, Berlin, Springer, , 485 p. (ISBN 978-3-540-76319-2, OCLC 244015158) — 6.8.1 Das Wortproblem, p. 154-159.
- (en) Michael A. Harrison, Introduction to Formal Language Theory, Reading, Mass. u.a., Addison-Wesley, , 594 p. (ISBN 978-0-201-02955-0, OCLC 266962302) — Section 12.4 The Cocke-Kasami-Younger Algorithm, p. 430-442.
- (en) John E. Hopcroft, Rajeev Motwani et Jeffrey D. Ullman, Introduction to Automata Theory, Languages, and Computation, Addison Wesley, , 2e éd., 521 p. (ISBN 978-0-201-44124-6 et 0201441241) — Section 7.4.4 Testing Membership in a CFL, p. 298-304.
- (en) Peter Linz, An Introduction to Formal Languages and Automata, Jones & Bartlett Learning, , 410 p. (ISBN 978-0-7637-1422-2 et 0763714224) — Section 6.3 A Membership Algorithm for Context Free Grammars, p. 172-174.
- (en) Jeffrey Shallit, A Second Course in Formal Languages and Automata Theory, Cambridge University Press, , 240 p. (ISBN 978-0-521-86572-2 et 0521865727) — Section 5.1 Recognition and parsing in general grammars p. 141-144
Voir aussi
- Analyse Earley
- Modèle de Markov caché
- Automate fini
- Théorie des automates
- Grammaire algébrique probabiliste
- Algorithme de Viterbi
- Programmation dynamique
- Bio-informatique
- Reconnaissance automatique de la parole
 Portail de l'informatique théorique
Portail de l'informatique théorique