Les processeurs vus auparavant ne peuvent émettre au maximum qu'une instruction par cycle d'horloge : ce sont des processeurs à émission unique. Et quand on court après la performance, on en veut toujours plus : un IPC de 1, c'est pas assez ! Pour cela, les concepteurs de processeurs ont inventés des processeurs qui émettent plusieurs instructions par cycle : les processeurs à émissions multiples.
Les processeurs superscalaires
Pour que cela fonctionne, il faut répartir les instructions sur différentes unités de calcul, et cela n'est pas une mince affaire. Si le processeur répartit les instructions sur les unités de calcul à l’exécution, on parle de processeur superscalaire. Certains processeurs superscalaires n'utilisent pas l'exécution dans le désordre, tandis que d'autres le font. Pour que le processeur répartisse ses instructions sur plusieurs unités de calcul, il faut modifier toutes les étapes entre le chargement et les unités de calcul.
L'étape de chargement superscalaire
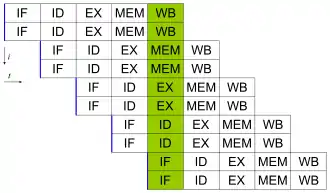
Sur les processeurs superscalaires, l'unité de chargement charge un bloc de mémoire de taille fixe, qui contient plusieurs instructions (le program counter est modifié en conséquence). Ceci dit, il faut convenablement gérer le cas où un branchement pris se retrouve en plein milieu d'un bloc. Dans ce qui va suivre, un morceau de code sans branchement est appelé un bloc de base (basic block).
Certains processeurs superscalaires exécutent toutes les instructions d'un bloc, sauf celles qui suivent un branchement pris. L'unité de chargement coupe le bloc chargé au niveau du premier branchement non-pris, remplit les vides avec des NOP, avant d'envoyer le tout à l'unité de décodage. Le processeur détermine quels branchements sont pris ou non avec la prédiction de branchements.
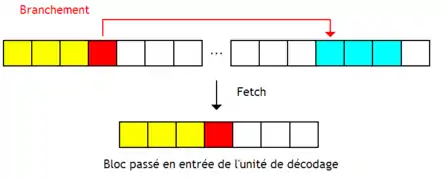
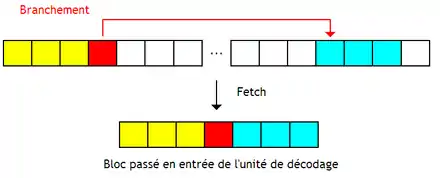
D'autres chargent les instructions de destination du branchement et les placent à sa suite. Ils chargent deux blocs à la fois et les fusionnent en un seul qui ne contient que les instructions présumées utiles (exécutées). Le principe peut se généraliser avec un nombre de blocs supérieur à deux.
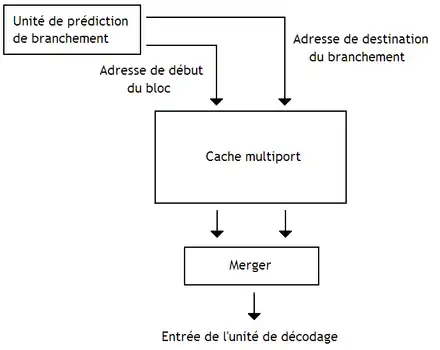
Ces processeurs utilisent des unités de prédiction de branchement capables de prédire plusieurs branchements par cycle, au minimum l'adresse du bloc à charger et la ou les adresses de destination des branchements dans le bloc. De plus, on doit charger deux blocs de mémoire en une fois, via des caches d'instruction multiports. Il faut aussi ajouter un circuit pour assembler plusieurs morceaux de blocs en un seul : le fusionneur (merger). Le résultat en sortie du fusionneur est ce qu'on appelle une trace.
Le cache de traces
Si jamais un bloc est rechargé et que ses branchements sont pris à l'identique, le résultat du fusionneur sera le même. Il est intéressant de conserver cette trace dans un cache de traces pour la réutiliser ultérieurement. Mais il reste à déterminer si une trace peut être réutilisée. Une trace est réutilisable quand le premier bloc de base est identique et que les prédictions de branchement restent identiques. Dans ces conditions, le tag du cache de traces doit contenir l'adresse de départ du premier bloc de base, la position des branchements dans la trace et le résultat des prédictions utilisées pour construire la trace. Le résultat des prédictions de branchement utilisées pour construire la trace est stocké sous la forme d'une suite de bits : si la trace contient n branchements, le n-ième bit vaut 1 si ce branchement a été pris, et 0 sinon. Même chose pour la position des branchements dans la trace : le bit numéro n indique si la n-ième instruction de la trace est un branchement : si c'est le cas, il vaut 1, et 0 sinon. Pour savoir si une trace est réutilisable, l'unité de chargement envoie l'adresse de chargement au cache de traces, le reste des informations étant fournie par l'unité de prédiction de branchement. Si le tag est identique, alors on a un succès de cache de traces, et la trace est envoyée directement au décodeur. Sinon, la trace est chargée depuis le cache d'instructions et assemblée.
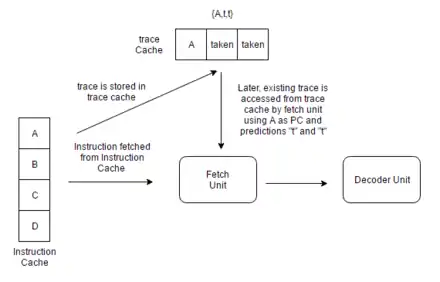
Certains caches de traces peuvent stocker plusieurs traces différentes pour une même adresse de départ, avec une trace par ensemble de prédiction. Mais d'autres caches de traces n'autorisent qu'une seule trace par adresse de départ, ce qui est sous-optimal. Mais on peut limiter la casse on utilisant des correspondances partielles. Si jamais les prédictions de branchement et la position des branchements n'est pas strictement identique, il arrive quand même que les premières prédictions et les premiers branchements soient les mêmes. Dans ce cas, on peut alors réutiliser les blocs de base concernés et le processeur charge les portions de la trace qui sont valides depuis le cache de traces. Une autre solution consiste à reconstituer les traces à la volée. Il suffit de mémoriser les blocs de base dans des caches dédiés et les assembler par un fusionneur. Par exemple, au lieu d'utiliser un cache de traces dont chaque ligne peut contenir quatre blocs de base, on va utiliser quatre caches de blocs de base. Cela permet de supprimer la redondance que l'on trouve dans les traces, quand elles se partagent des blocs de base identiques, ce qui est avantageux à mémoire égale.
La présence d'un cache de traces se marie très bien avec une unité de prédiction de branchement capable de prédire un grand nombre de branchements par cycle. Malheureusement, ces unités de prédiction de branchement sont très complexes et gourmandes en circuits. Les concepteurs de processeurs préfèrent utiliser une unité de prédiction de branchement normale, qui ne peut prédire l'adresse que d'un seul bloc de base. Pour pouvoir utiliser un cache de traces avec une unité de prédiction aussi simple, les concepteurs de processeurs vont ajouter une seconde unité de prédiction, spécialisée dans le cache de traces.
L'unité de renommage superscalaire
Le séquenceur d'un processeur superscalaire est lui aussi modifié, afin de pourvoir décoder plusieurs instructions à la fois. Une unité de renommage de registres superscalaire doit renommer plusieurs instructions à la fois, mais aussi gérer les dépendances entre instructions. Pour cela, elle renomme les registres sans tenir compte des dépendances, pour ensuite corriger le résultat.
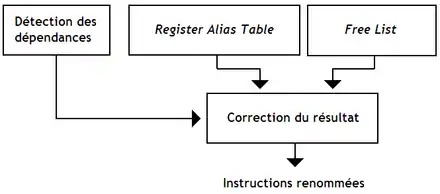
Seules les dépendances lecture-après-écriture doivent être détectées, les autres étant supprimées par le renommage de registres. Repérer ce genre de dépendances se fait assez simplement : il suffit de regarder si un registre de destination d'une instruction est un opérande d'une instruction suivante.
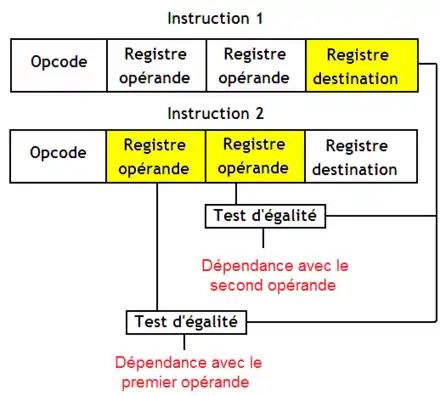
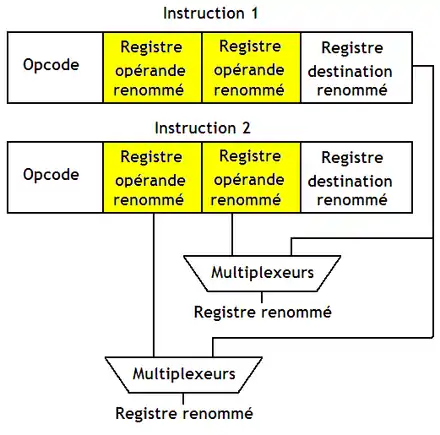
Ensuite, il faut corriger le résultat du renommage en fonction des dépendances. Si une instruction n'a pas de dépendance avec une autre, on la laisse telle quelle. Dans le cas contraire, un registre opérande sera identique avec le registre de destination d'une instruction précédente. Dans ce cas, le registre opérande n'est pas le bon après renommage : on doit le remplacer par le registre de destination de l'instruction avec laquelle il y a dépendance. Cela se fait simplement en utilisant un multiplexeur dont les entrées sont reliées à l'unité de détection des dépendances. On doit faire ce replacement pour chaque registre opérande.
L'unité d'émission superscalaire
Sur un processeur à émission multiple, l'unité d'émission doit, en plus de ses fonctions habituelles, détecter les dépendances entre instructions à émettre simultanément. L'unité d'émission d'un processeur superscalaire se voit donc ajouter un nouvel étage pour les dépendances entre instructions à émettre. Sur les processeurs superscalaires à exécution dans l’ordre, il faut aussi gérer l'alignement des instructions dans la fenêtre d'instruction. Dans le cas le plus simple, les instructions sont chargées par blocs et on doit attendre que toutes les instructions du bloc soient émises pour charger un nouveau bloc. Avec la seconde méthode, La fenêtre d'instruction fonctionne comme une fenêtre glissante, qui se déplace de plusieurs crans à chaque cycle d'horloge.
L'accès au banc de registres
Émettre plusieurs instructions en même temps signifie lire ou écrire plusieurs opérandes à la fois : le nombre de ports du banc de registres doit être augmenté. Mais ces ports ajoutés sont souvent sous-utilisés en situation réelle. On peut en profiter pour ne pas utiliser autant de ports que le pire des cas le demanderait. Pour cela, le processeur doit détecter quand il n'y a pas assez de ports pour servir toutes les instructions : l'unité d'émission devra alors mettre en attente certaines instructions, le temps que les ports se libèrent. Cette détection est réalisée par un circuit d'arbitrage spécialisé, l’arbitre du banc de registres (register file arbiter).
Les processeurs VLIW
Comme on vient de le voir, les processeurs superscalaires utilisent beaucoup de circuits pour répartir des instructions sur plusieurs unités de calcul en parallèle. Pour limiter la casse, les concepteurs de processeurs ont eu l'idée de déléguer au compilateur ce travail de répartition des opérations sur les unités de calcul. C'est ainsi que les processeurs VLIW, ou very long instruction word, sont nés. Ce sont des processeurs qui n'utilisent pas l'exécution dans le désordre, ce qui fait qu'ils ne peuvent rien contre les dépendances qui ne peuvent être supprimées qu'à l’exécution, comme celles liées aux accès mémoires.
Les faisceaux d’instructions
Les processeurs VLIW exécutent des faisceaux d’instructions (aussi appelés bundle), des regroupements de plusieurs instructions qui s'exécutent en parallèle sur différentes unités de calcul. Le faisceau est chargé en une seule fois et est encodé comme une instruction unique. C'est le compilateur qui regroupe plusieurs instructions en un seul faisceau.
Chaque instruction d'un faisceau précise l'unité de calcul qui doit la prendre en charge. Et à ce petit jeu, il existe deux possibilités, respectivement nommées encodage par position et par nommage. Avec la première méthode, un faisceau est découpé en créneaux (slot), chacun étant attribué à une ALU. La position de l'instruction dans le faisceau détermine l'ALU à utiliser. Avec la seconde solution, chaque instruction contient un numéro qui indique l'unité de calcul à utiliser. Cette technique est déclinée en deux formes : soit on trouve un identifiant d'ALU par instruction, soit on utilise un identifiant pour tout le faisceau, qui permet à lui seul de déterminer l'unité associée à chaque instruction.
Quand le compilateur regroupe des instructions dans un faisceau, il se peut qu'il ne puisse pas remplir tout le faisceau avec des instructions indépendantes. Sur les anciens processeurs VLIW, les instructions VLIW (les faisceaux) étaient de taille fixe, ce qui forçait le compilateur à remplir d'éventuels vides avec des NOP, diminuant la densité de code. La majorité des processeurs VLIW récents utilise des faisceaux de longueur variable, supprimant ces NOP.
Les dépendances intra-faisceaux
Des difficultés arrivent quand des instructions d'un faisceau manipulent le même registre. Les problèmes apparaissent avec des écritures, notamment quand une instruction lit un registre écrit par une autre instruction. Dans ce cas, le processeur peut gérer la situation de trois manières différentes :
- la lecture du registre renvoie la valeur avant l'écriture ;
- la lecture lit la valeur écrite par l'écriture ;
- le processeur interdit aux instructions d'un même faisceau de lire et écrire le même registre.
Les exceptions
Lorsqu'une instruction lève une exception, un processeur VLIW peut gérer la situation de plusieurs manières différentes, qui dépendent du processeur. Soit :
- on invalide toutes les instructions du faisceau ;
- on invalide uniquement les instructions qui suivent l'exception dans l'ordre du programme (le compilateur doit ajouter quelques informations sur l'ordre des instructions dans le faisceau) ;
- on invalide seulement les instructions qui ont une dépendance avec celle qui a levé l'exception ;
- on exécute toutes les instructions du faisceau, sauf celle qui a levé l'exception.
Les défauts des architectures VLIW
Les architectures VLIW ont divers problèmes, comme une faible compatibilité, des performances limitées par les dépendances existantes à la compilation et une densité de code mauvaise.
Sur ces architectures, certains dépendances entre instructions ne peuvent être supprimées, ce qu'un processeur à exécution dans le désordre peut faire. Par exemple, le fait que les accès à la mémoire aient des durées variables (suivant que la donnée soit dans le cache ou la RAM, par exemple) joue sur les différentes dépendances. Un compilateur ne peut pas savoir combien de temps va mettre un accès mémoire et il ne peut organiser les instructions d'un programme en conséquence. Par contre, un processeur le peu. Autre exemple : les dépendances d'instructions dues aux branchements, qui ont tendance à limiter fortement les possibilités d'optimisation du compilateur.
Autre défaut : les processeurs VLIW n'ont strictement aucune compatibilité, ou alors celle-ci est très limitée. En effet, le format des faisceaux VLIW est spécifique à un processeur. Celui-ci va dire : telle instruction va sur telle ALU, et pas ailleurs. Mais si on rajoute des unités de calcul dans une nouvelle version du processeur, il faudra recompiler notre programme pour que celui-ci puisse l'utiliser, voire même simplement faire fonctionner notre programme. Dans des situations dans lesquelles on se moque de la compatibilité, cela ne pose aucun problèmes : par exemple, on utilise beaucoup les processeurs VLIW dans l'embarqué. Mais pour un ordinateur de bureau, c'est autre chose...
Les processeurs EPIC
En 1997, Intel et HP lancèrent un nouveau processeur, l'Itanium, dont l'architecture corrigeait les défauts des autres processeurs VLIW. Dans un but marketing évident, Intel et HP prétendirent que l'architecture de ce processeur n'était pas du VLIW amélioré, mais une nouvelle architecture appelée EPIC, pour Explicit Parallelism Instruction Computing. Il faut avouer que cette architecture avait de fortes différences avec le VLIW, mais aussi beaucoup de points communs. Bien évidemment, beaucoup ne furent pas dupes, et une gigantesque controverse vit le jour : est-ce que les architectures EPIC sont des VLIW ou non ? Sans prendre position sur le sujet, nous avons séparé les processeurs VLIW et EPIC, par souci didactique.
Les faisceaux des CPU EPIC
La première différence avec les VLIW tient dans les faisceaux. Ceux-ci deviennent des groupes d'instructions indépendantes, délimités par un petit groupe de bits d’arrêt (stop bits) qui indique la fin d'un faisceau.
D'autres processeurs utilisent un bit de parallélisme (parallel bit), un bit placé à la fin d'une instruction qui dit si elle peut s'effectuer ou non en parallèle de la suivante.
Avec l'usage d'un bit de stop ou de parallélisme, le processeur découpe le faisceau en instructions et les répartit sur les unités de calcul. L'avantage est que la compatibilité est nettement meilleure, de même que les performances. Peu importe le nombre d'unité de calcul, le processeur peut profiter de leur présence en répartissant les instructions convenablement. Enfin, on peut aussi citer les avantages en terme de densité de code : pas besoin d'insérer des NOPs dans des slots vides ou de fournir des identifiants d'ALUs, comme avec les processeurs VLIW.
Les exceptions différées
L'Itanium implémente ce qu'on appelle les exceptions différées. Avec cette technique, le compilateur crée deux versions d'un même code : une version optimisée qui suppose qu'aucune exception matérielle n'est levée, et une autre version qui prend en compte les exceptions. Le programme exécute d'abord la version optimisée de manière spéculative, mais annule son exécution et repasse sur la version non-optimisée en cas d'exception.
Pour vérifier l’occurrence d'une exception, chaque registre est associé à un bit « rien du tout » (not a thing), mis à 1 s'il contient une valeur invalide. Si une instruction lève une exception, elle écrira un résultat faux dans un registre et le bit « rien du tout » est mis à 1. Les autres instructions propageront ce bit « rien du tout » dans leurs résultats : si un opérande est « rien du tout », le résultat de l'instruction l'est aussi. Une fois le code fini, il suffit d'utiliser une instruction qui teste l'ensemble des bits « rien du tout » et agit en conséquence.
La spéculation sur les lectures
L'Itanium fournit une fonctionnalité similaire pour les lectures, où le code est compilé dans une version optimisée où les lectures sont déplacées sans tenir compte des dépendances, avec un code de secours non-optimisé. Encore une fois, le processeur vérifie si la spéculation s'est bien passée, avant de décider de passer sur le code de secours ou non. La vérification ne se fait pas de la même façon selon que la lecture ait été déplacée avant un branchement ou avant une autre écriture.
- Si on passe une lecture avant un branchement, la lecture et la vérification sont effectuées par les instructions LD.S et CHK.S. Si une dépendance est violée, le processeur lève une exception différée : le bit « rien du tout » du registre contenant la donnée lue est alors mis à 1. CHK.S ne fait rien d'autre que vérifier ce bit.
- Si on passe une lecture avant une écriture, la désambigüisation de la mémoire est gérée par le compilateur. Tout se passe comme avec les branchements, à part que les instructions sont nommées LD.A et CHK.A.
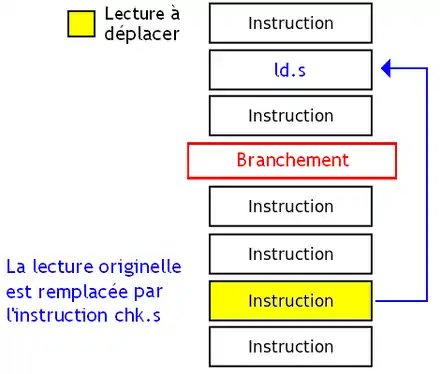
Pour détecter les violations de dépendance, le processeur maintient une liste des lectures spéculatives qui n'ont pas causé de dépendances mémoire, dans un cache : la table des adresses lues en avance (advanced load address table ou ALAT). Ce cache stocke l'adresse, la longueur de la donnée lue, le registre de destination, etc. Toute écriture vérifie si une lecture à la même adresse est présente dans l'ALAT : si c'est le cas, une dépendance a été violée, et la lecture est retirée de l'ALAT.
Les bancs de registres rotatifs
Les processeurs EPIC et VLIW utilisent une forme limitée de renommage de registres pour accélérer certaines boucles. Pour l’expliquer, prenons une boucle simple et intéressons-nous au corps de la boucle, à savoir la boucle sans les branchements et instructions de test qui servent à répéter les instructions. La boucle d'exemple se contente d'ajouter 5 à tous les éléments d'un tableau. L'adresse de l’élément du tableau est stockée dans le registre R2. Dans le code qui suivra, les crochets serviront à indiquer l'utilisation du mode d'adressage indirect. Sans optimisations, le corps de la boucle est le suivant :
loop :
load R5 [R2] / add 4 R2 ; add 5 R5 ; store [R2] R5 ;
Les différentes itérations de la boucle peuvent se calculer en parallèle, vu que les éléments du tableau sont manipulés indépendamment. Mais codée comme dessus, ce n'est pas possible car les trois instructions de la boucle utilisent le registre R5 et ont donc des dépendances. Le renommage de registres peut éliminer ces dépendances, mais il n'est pas disponible sur les processeurs VLIW et EPIC. A la place, les concepteurs de processeurs ont inventé les bancs de registres rotatifs (rotating register files). Avec cette méthode, la correspondance (nom de registre - registre physique) se décale d'un cran à chaque cycle d’horloge. Par exemple, le registre nommé R0 à un instant donné devient le registre R1 au cycle d'après, et idem pour tous les registres. Précisons que sur l'Itanium, cette technique est appliquée non pas à l'ensemble du banc de registre, mais est limitée à un banc de registres spécialisé dans l’exécution des boucles. Évidemment, le code source du programme doit être modifié pour en tenir compte. Ainsi, le code vu précédemment devient celui-ci.
loop :
load RB5 [R2] / add 4 R2 ; add 5 RB6 ; store [R2] RB7 ;
Ainsi, le LOAD d'une itération ne touchera pas le même registre que le LOAD de l'itération suivante, idem pour l'instruction de calcul et le STORE. Le nom de registre sera le même, mais le fait que les noms de registre se décalent à chaque cycle d'horloge fera que ces noms identiques correspondent à des registres différents. Les dépendances sont supprimées, et le pipeline est utilisé à pleine puissance.
Cette technique s'implémente avec un simple compteur, incrémenté à chaque cycle d'horloge, qui mémorise le décalage à appliquer aux noms de registre. A chaque utilisation d'un registre, le contenu de ce compteur est ajouté au nom de registre à accéder.