Les mémoires vues au chapitre précédent sont les mémoires les plus simples qui soient. Mais ces mémoires peuvent se voir ajouter quelques améliorations pas franchement négligeables, afin d'augmenter leur rapidité, ou de diminuer leur consommation énergétique. Dans ce chapitre, nous allons voir quelles sont ces améliorations les plus courantes.
Les mémoires synchrones
Les toutes premières mémoires n'étaient pas synchronisées avec le processeur via une horloge : c'était des mémoires asynchrones. Un accès mémoire devait être plus court qu'un cycle d'horloge processeur. Avec le temps, le processeur est devenu plus rapide que la mémoire : il ne pouvait pas prévoir quand la donnée serait disponible et ne faisait rien tant que la mémoire n'avait pas répondu. Pour résoudre ces problèmes, les concepteurs de mémoire ont synchronisé les échanges entre processeur et mémoire avec un signal d'horloge : les mémoires synchrones sont nées. L'utilisation d'une horloge a l'avantage d'imposer des temps d'accès fixes : le processeur sait qu'un accès mémoire prendra un nombre déterminé (2, 3, 5, etc) de cycles d'horloge et peut faire ce qu'il veut dans son coin durant ce temps.
Les mémoires synchrones non-pipelinées
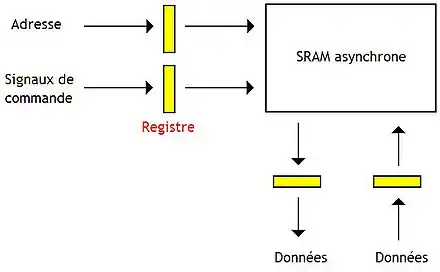
Fabriquer une mémoire synchrone demande de rajouter des registres sur les entrées/sorties d'une mémoire asynchrone. Ainsi, le processeur n'a pas à maintenir l'adresse en entrée de la mémoire durant toute la durée d'un accès mémoire : le registre s'en charge.
La première méthode ne mémorise que l'adresse d'entrée et les signaux de commande dans un registre synchronisé sur l'horloge.

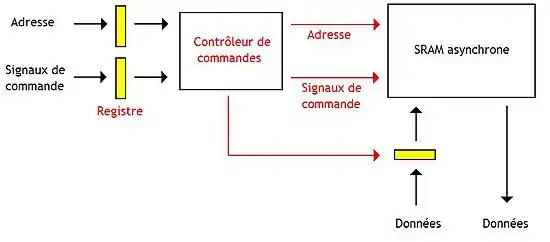
Une seconde méthode mémorise l'adresse, les signaux de commande, ainsi que les données à écrire.

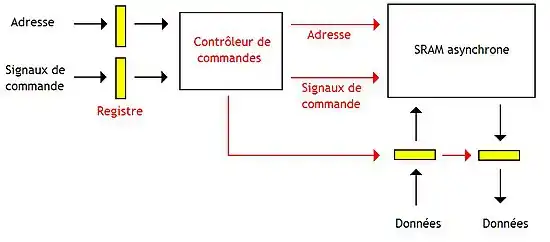
Et la dernière méthode mémorise toutes les entrées et sorties de la mémoire dans des registres synchronisés sur l'horloge.
Les mémoires synchrones pipelinées
L'usage d'une horloge permet aussi de faciliter l'implantation de ce qu'on appelle un pipeline. Pour rappel, la sélection d'une case mémoire se fait en plusieurs étapes, chaque étape prenant un cycle d’horloge. Suivant la mémoire, le nombre d'étapes varie :
- on peut envoyer l'adresse lors d'un cycle, et récupérer la donnée lue au cycle suivant ;
- on peut aussi envoyer l'adresse lors d'un premier cycle, effectuer la lecture durant le cycle suivant, et récupérer la donnée sur le bus un cycle plus tard ;
- on peut aussi tenir compte du fait que la mémoire est organisée en lignes et en colonnes : l'étape de lecture peut ainsi être scindée en une étape pour sélectionner la ligne, et une autre pour sélectionner la colonne ;
- etc.
Avec une mémoire synchrone sans pipeline, on doit attendre qu'un accès mémoire soit fini avant d'en démarrer un autre.

Avec les mémoires pipelinées, on peut réaliser un accès mémoire sans attendre que les précédents soient finis. En quelque sorte, ces mémoires ont la capacité de traiter plusieurs requêtes de lecture/écriture en même temps, tant que celles-ci sont chacune à des étapes différentes. Par exemple, on peut envoyer l'adresse de la prochaine requête pendant que l'on accède à la donnée de la requête courante. Les mémoires qui utilisent ce pipelining ont donc un débit supérieur aux mémoires qui ne l'utilisent pas : le nombre d'accès mémoire traités par seconde augmente.

Cette technique demande d'enchainer les différentes étapes à chaque cycle : les adresses et ordres de commande doivent arriver au bon endroit au bon moment. Pour cela, on est obligé de modifier le contrôleur de mémoire interne et y ajouter un circuit séquentiel qui envoie des ordres aux différents composants de la mémoire dans un ordre déterminé. La complexité de ce circuit séquentiel dépend fortement du nombre d'étapes utilisé pour gérer l'accès mémoire.
Précisons que si le temps d'accès mémoire ne change pas, le nombre de cycles nécessaires pour traiter une requête de lecture/écriture augmente : d'un seul cycle, on passe à autant de cycles qu'il y a d'étapes. Mais la fréquence est supérieure pour les mémoires pipelinées, ce qui compense exactement l'augmentation du nombre d'étapes. En effet, un cycle sur une mémoire non-pipelinée correspond à un accès mémoire complet, tandis qu'un cycle est égal à la durée d'une seule étape sur une mémoire pipelinée.
Les écritures tardives
Vu que lectures et écritures n'ont pas forcément le même nombre d'étapes, celles-ci peuvent vouloir accéder au plan mémoire en même temps : ces conflits, qui ont lieu lors d'alternances entre lectures et écritures, sont appelés des retournements de bus. Pour les résoudre, la mémoire doit mettre en attente un des deux accès : le registre d'adresse (et éventuellement le registre d'écriture) est maintenu pour conserver la commande en attente. Ces conflits sont détectés par le contrôleur mémoire.
Une solution pour éviter ces cycles morts est de retarder l'envoi de la donnée à écrire d'un cycle, ce qui donne une écriture tardive. Sur les mémoires pour lesquelles l'écriture tardive ne donne pas d'amélioration, l'idéal est de retarder l'écriture de deux cycles d'horloge, et non d'un seul. Cette technique s'appelle l'écriture doublement tardive. Mais si des lectures et écritures consécutives accèdent à la même adresse, la lecture lira une donnée qui n'a pas encore été mise à jour par l'écriture. Pour éviter cela, on doit ajouter un comparateur qui vérifie les deux adresses consécutives : si elles sont identiques, le contenu du registre d'écriture sera envoyé sur le bus au cycle adéquat. Dans le cas des écritures doublement tardives, il faut ajouter deux registres.
Les différents types de mémoires synchrones pipelinées
Il existe divers types de mémoires pipelinées. Les plus simples sont les mémoires à flot direct. Avec celles-ci, la donnée lue ne subit pas de mémorisation dans un registre de sortie.
Avec les mémoires synchrones registre à registre, la donnée sortante est mémorisée dans un registre, afin d'augmenter la fréquence de la mémoire et son débit. Le temps de latence des lectures est plus long avec cette technique : il faut ajouter un cycle supplémentaire pour enregistrer la donnée dans le registre, avant de pouvoir la lire. Sur certaines mémoires, le registre en question est séquencé non sur un front, mais par un bit : le temps mis pour écrire dans ce registre est plus faible, ce qui supprime le cycle d'attente supplémentaire.
Dual et quad data rate
Nos processeurs sont de plus en plus exigeants, et la vitesse de la mémoire est un sujet primordial. La solution la plus évidente est d'accroître sa fréquence ou la largeur du bus, mais cela aurait pas mal de désavantages : le prix de la mémoire s'envolerait, elle serait bien plus difficile à concevoir, et tout cela sans compter les difficultés pour faire fonctionner l'ensemble à haute fréquence. Le compromis entre ces deux techniques a donné naissance aux mémoires Dual Data Rate. Le plan mémoire a une fréquence inférieure à celle du bus, mais a une largeur plus importante : on peut y lire ou y écrire 2 fois plus de données d'un seul coup. Le contrôleur et le bus mémoire fonctionnent à une fréquence double de celle du plan mémoire, pour compenser.

Il existe aussi des mémoires quad data rate, pour lesquelles la fréquence du bus est quatre fois celle du plan mémoire. Évidemment, la mémoire peut alors lire ou écrire 4 fois plus de données par cycle que ce que le bus peut supporter.

Les banques et rangées
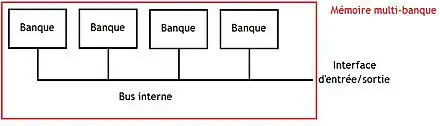
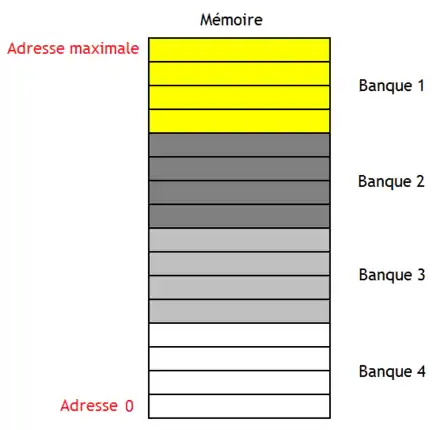
Sur certaines puces mémoires, un seul boitier peut contenir plusieurs mémoires indépendantes regroupées pour former une mémoire unique plus grosse. Chaque sous-mémoire indépendante est appelée une banque, ou encore un banc mémoire. La mémoire obtenue par combinaison de plusieurs banques est appelée une mémoire multi-banques. Cette technique peut servir à améliorer les performances, la consommation d'énergie, et j'en passe. Par exemple, cela permet de faciliter le rafraichissement d'une mémoire DRAM : on peut rafraichir chaque sous-mémoire en parallèle, indépendamment des autres. Mais cette technique est principalement utilisée pour doubler le nombre d'adresses, doubler la taille d'un mot mémoire, ou faire les deux.
L'arrangement horizontal
L'arrangement horizontal utilise plusieurs banques pour augmenter la taille d'un mot mémoire sans changer le nombre d'adresses. Chaque banc mémoire contient une partie du mot mémoire final. Avec cette organisation, on accède à tous les bancs en parallèle à chaque accès, avec la même adresse.

Pour l'exemple, les barrettes de mémoires SDRAM ou DDR-RAM des PC actuels possèdent un mot mémoire de 64 bits, mais sont en réalité composées de 8 sous-mémoires ayant un mot mémoire de 8 bits. Cela permet de répartir la production de chaleur sur la barrette : la production de chaleur est répartie entre plusieurs puces, au lieu d'être concentrée dans la puce en cours d'accès. La technologie dual-channel est basée sur le même principe. Sauf qu'au lieu de rassembler plusieurs puces mémoires sur une même barrette, on fait la même chose avec plusieurs barrettes de mémoires. Ainsi, on peut connecter deux barrettes avec un mot mémoire de 64 bits et on les relie à un bus de 128 bits.
L'arrangement vertical
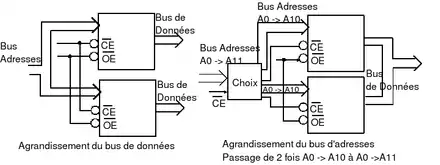
L'arrangement vertical rassemble plusieurs boitiers de mémoires pour augmenter la capacité sans changer la taille d'un mot mémoire. On utilisera un boitier pour une partie de la mémoire, un autre boitier pour une autre, et ainsi de suite. L'organisation d'une mémoire de ce type se compare assez facilement avec un arrangement horizontal. Premièrement, toutes les banques sont reliées au bus de données, qui a la même largeur que les sorties des banques. De plus, l'adresse n'est pas envoyée sur tous les boitiers : une partie de l'adresse est utilisée pour choisir à quel banque envoyer les bits restants de l'adresse. Les autres banques sont désactivées.
Les mémoires non-entrelacées
Sans aucune optimisation, on utilise les bits de poids forts pour sélectionner la banque, ce qui fait que les adresses sont réparties comme illustré dans le schéma ci-dessous. Un défaut de cette organisation est que, si on souhaite lire/écrire deux mots mémoires consécutifs, on devra attendre que l'accès au premier mot soit fini avant de pouvoir accéder au suivant (vu que ceux-ci sont dans la même banque).
Un arrangement vertical sans entrelacement peut se mettre en œuvre de plusieurs manières différentes.
- La première méthode consiste à connecter la bonne banque et déconnecter toutes les autres. Pour cela, on utilise la broche CS, qui connecte ou déconnecte la mémoire du bus. Cette broche est commandée par un décodeur, qui prend les bits de poids forts de l'adresse en entrée.
- Une autre solution est d'ajouter un multiplexeur en sortie des banques et de commander celui-ci convenablement avec les bits de poids forts.

L'entrelacement basique
Avec l'organisation précédente, les accès séquentiels se font dans la même banque, ce qui les rend assez lent. Mais il est possible de pipeliner ces accès à des bytes consécutifs en rusant quelque peu. Cela permet de démarrer une lecture ou écriture dans une nouvelle banque à chaque cycle, tant qu'il reste des banques inutilisées.
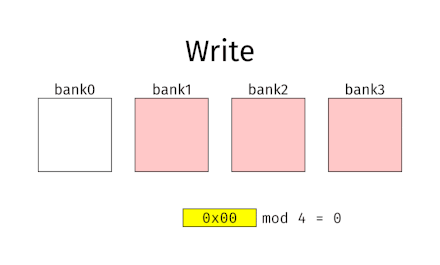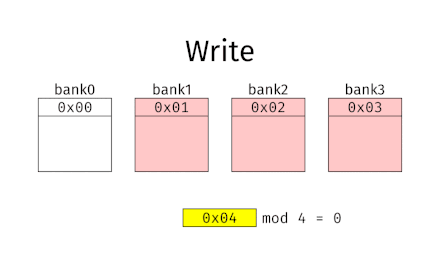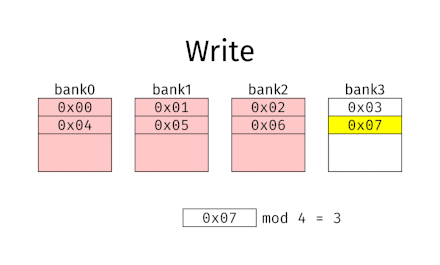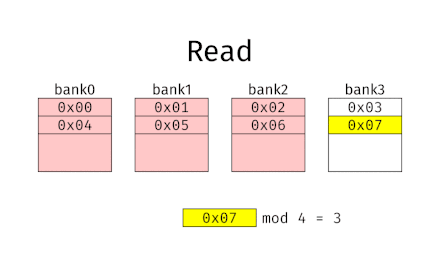
En clair, il faut que des accès consécutifs tombent dans des banques différentes, et donc que des bytes consécutifs soient localisés dans des banques différentes. Les mémoires qui fonctionnent sur ce principe sont appelées des mémoires à entrelacement simple.

Pour cela, il suffit de prendre une mémoire à arrangement vertical, avec un petit changement : il faut utiliser les bits de poids faible pour sélectionner la banque, et les bits de poids fort pour le Byte.

Les mémoires à entrelacement par décalage
Les mémoires à entrelacement simple ont un petit problème : sur une mémoire à N banques, des accès dont les adresses sont séparées par N mots mémoires vont tous tomber dans la même banque et seront donc impossibles à pipeliner. Pour résoudre ce problème, il faut répartir les mots mémoires dans la mémoire autrement. Dans les explications qui vont suivre, la variable N représente le nombre de banques, qui sont numérotées de 0 à N-1.
Pour obtenir cette organisation, on va découper notre mémoire en blocs de N adresses. On commence par organiser les N premières adresses comme une mémoire entrelacée simple : l'adresse 0 correspond à la banque 0, l'adresse 1 à la banque 1, etc. Pour le bloc suivant, nous allons décaler d'une adresse, et continuer à remplir le bloc comme avant. Une fois la fin du bloc atteinte, on finit de remplir le bloc en repartant du début du bloc. Et on poursuit l’assignation des adresses en décalant d'un cran en plus à chaque bloc. Ainsi, chaque bloc verra ses adresses décalées d'un cran en plus comparé au bloc précédent. Si jamais le décalage dépasse la fin d'un bloc, alors on reprend au début.

En faisant cela, on remarque que les banques situées à N adresses d'intervalle sont différentes. Dans l'exemple du dessus, nous avons ajouté un décalage de 1 à chaque nouveau bloc à remplir. Mais on aurait tout aussi bien pu prendre un décalage de 2, 3, etc. Dans tous les cas, on obtient un entrelacement par décalage. Ce décalage est appelé le pas d'entrelacement, noté P. Le calcul de l'adresse à envoyer à la banque, ainsi que la banque à sélectionner se fait en utilisant les formules suivantes :
- adresse à envoyer à la banque = adresse totale / N ;
- numéro de la banque = (adresse + décalage) modulo N, avec décalage = (adresse totale * P) mod N.
Avec cet entrelacement par décalage, on peut prouver que la bande passante maximale est atteinte si le nombre de banques est un nombre premier. Seulement, utiliser un nombre de banques premier peut créer des trous dans la mémoire, des mots mémoires inadressables. Pour éviter cela, il faut faire en sorte que N et la taille d'une banque soient premiers entre eux : ils ne doivent pas avoir de diviseur commun. Dans ce cas, les formules se simplifient :
- adresse à envoyer à la banque = adresse totale / taille de la banque ;
- numéro de la banque = adresse modulo N.
L'entrelacement pseudo-aléatoire
Une dernière méthode de répartition consiste à répartir les adresses dans les banques de manière pseudo-aléatoire. La première solution consiste à permuter des bits entre ces champs : des bits qui étaient dans le champ de sélection de ligne vont être placés dans le champ pour la colonne, et vice-versa. Pour ce faire, on peut utiliser des permutations : il suffit d'échanger des bits de place avant de couper l'adresse en deux morceaux : un pour la sélection de la banque, et un autre pour la sélection de l'adresse dans la banque. Cette permutation est fixe, et ne change pas suivant l'adresse. D'autres inversent les bits dans les champs : le dernier bit devient le premier, l'avant-dernier devient le second, etc. Autre solution : couper l'adresse en morceaux, faire un XOR bit à bit entre certains morceaux, et les remplacer par le résultat du XOR bit à bit. Il existe aussi d'autres techniques qui donnent le numéro de banque à partir d'un polynôme modulo N, appliqué sur l'adresse.
Les rangées
Si on mélange l'arrangement vertical et l'arrangement horizontal, on obtient ce que l'on appelle une rangée. Sur ces mémoires, les adresses sont découpées en trois morceaux, un pour sélectionner la rangée, un autre la banque, puis la ligne et la colonne.
Les mémoires multiports
Les mémoires multiports sont reliées non pas à un, mais à plusieurs bus. Chaque bus est connecté sur la mémoire sur ce qu'on appelle un port. Ces mémoires permettent de transférer plusieurs données à la fois, une par port. Le débit est sont donc supérieur à celui des mémoires mono-port. De plus, chaque port peut être relié à des composants différents, ce qui permet de partager une mémoire entre plusieurs composants. Comme autre exemple, certaines mémoires multiports ont un bus sur lequel on ne peut que lire une donnée, et un autre sur lequel on ne peut qu'écrire.
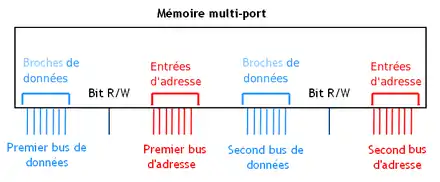
Le multiports idéal
Une première solution consiste à créer une mémoire qui soit vraiment multiports. Avec une mémoire multiports, tout est dupliqué sauf les cellules mémoire. Pour rappel, dans une mémoire normale, chaque cellule mémoire est relié à bitline via un transistor, lui-même commandé par le décodeur. Chaque port a sa propre bitline dédiée, ce qui donne N bitlines pour une mémoire à N ports. Évidemment, cela demande d'ajouter des transistors de sélection, pour la connexion et la déconnexion. De plus, ces transistors sont dorénavant commandés par des décodeurs différents : un par port. Et on a autant de duplications que l'on a de ports : N ports signifie tout multiplier par N. Autant dire que ce n'est pas l'idéal en termes de consommation énergétique !
Cette solution pose toutefois un problème : que se passe-t-il lorsque des ports différents écrivent simultanément dans la même cellule mémoire ? Eh bien tout dépend de la mémoire : certaines donnent des résultats plus ou moins aléatoires et ne sont pas conçues pour gérer de tels accès, d'autres mettent en attente un des ports lors de l'accès en écriture. Sur ces dernières, il faut évidemment rajouter des circuits pour détecter les accès concurrents et éviter que deux ports se marchent sur les pieds.
Le multiports à état partagé
Certaines mémoires ont besoin d'avoir un très grand nombre de ports de lecture. Pour cela, on peut utiliser une mémoire multiports à état dupliqué. Au lieu d'utiliser une seule mémoire de 20 ports de lecture, le mieux est d'utiliser 4 mémoires qui ont chacune 5 ports de lecture. Toutefois, ces quatre mémoires possèdent exactement le même contenu, chacune d'entre elles étant une copie des autres : toute donnée écrite dans une des mémoires l'est aussi dans les autres. Comme cela, on est certain qu'une donnée écrite lors d'un cycle pourra être lue au cycle suivant, quel que soit le port, et quelles que soient les conditions.
Le multiports externe
D'autres mémoires multiports sont fabriquées à partir d'une mémoire à un seul port, couplée à des circuits pour faire l'interface avec chaque port.

Une première méthode pour concevoir ainsi une mémoire multiports est d'augmenter la fréquence de la mémoire mono-port sans toucher à celle du bus. A chaque cycle d'horloge interne, un port a accès au plan mémoire.
La seconde méthode est basée sur des stream buffers. Elle fonctionne bien avec des accès à des adresses consécutives. Dans ces conditions, on peut tricher en lisant ou en écrivant plusieurs blocs à la fois dans la mémoire interne monoport : la mémoire interne a un port très large, capable de lire ou d'écrire une grande quantité de données d'un seul coup. Mais ces données ne pourront pas être envoyées sur les ports de lecture ou reçues via les ports d'écritures, nettement moins larges. Pour la lecture, il faut obligatoirement utiliser un circuit qui découpe les mots mémoires lus depuis la mémoire interne en données de la taille des ports de lecture, et qui envoie ces données une par une. Et c'est la même chose pour les ports d'écriture, si ce n'est que les données doivent être fusionnées pour obtenir un mot mémoire complet de la RAM interne.
Pour cela, chaque port se voit attribuer une mémoire qui met en attente les données lues ou à écrire dans la mémoire interne : le stream buffer. Si le transfert de données entre RAM interne et stream buffer ne prend qu'un seul cycle, ce n'est pas le cas pour les échanges entre ports de lecture et écriture et stream buffer : si le mot mémoire de la RAM interne est n fois plus gros que la largeur d'un port de lecture/écriture, il faudra envoyer le mot mémoire en n fois, ce qui donne n^cycles. Ainsi, pendant qu'un port accèdera à la mémoire interne, les autres ports seront occupés à lire le contenu de leurs stream buffers. Ces stream buffers sont gérés par des circuits annexes, pour éviter que deux stream buffers accèdent en même temps dans la mémoire interne.

La troisième méthode remplace les stream buffers par des caches, et utilise une mémoire interne qui ne permet pas de lire ou d'écrire plusieurs mots mémoires d'un coup. Ainsi, un port pourra lire le contenu de la mémoire interne pendant que les autres ports seront occupés à lire ou écrire dans leurs caches.

La méthode précédente peut être améliorée, en utilisant non pas une seule mémoire monoport en interne, mais plusieurs banques monoports. Dans ce cas, il n'y a pas besoin d'utiliser de mémoires caches ou de stream buffers : chaque port peut accéder à une banque tant que les autres ports n'y touchent pas. Évidemment, si deux ports veulent lire ou écrire dans la même banque, un choix devra être fait et un des deux ports devra être mis en attente.
