Dans le chapitre sur le langage machine, on a vu notre processeur comme une espèce de boite noire contenant des registres qui exécutait des instructions les unes après les autres et pouvait accéder à la mémoire. Mais on n'a pas encore vu comment celui-ci était organisé et comment celui-ci fait pour exécuter une instruction. Pour cela, il va falloir nous attaquer à la micro-architecture du processeur. C'est le but de ce chapitre : montrer comment les grands circuits de notre processeur sont organisés et comment ceux-ci permettent d’exécuter une instruction. On verra que notre processeur est très organisé et est divisé en plusieurs grands circuits qui effectuent des fonctions différentes.
L'exécution d'une instruction
Le but d'un processeur, c'est d’exécuter une instruction. Cela nécessite de faire quelques manipulations assez spécifiques et qui sont toutes les mêmes quelque soit l'ordinateur. Pour exécuter une instruction, notre processeur va devoir faire son travail en effectuant des étapes bien précises.
Le cycle d'exécution d'une instruction
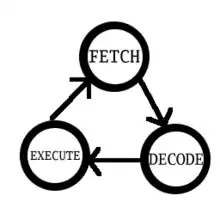
Pour exécuter une instruction, le processeur va effectuer trois étapes :
- l'unité de chargement va charger l'instruction depuis la mémoire : c'est l'étape de chargement (Fetch) ;
- le séquenceur va ensuite « étudier » la suite de bits de l'instruction et en déduire comment configurer les circuits du processeur pour exécuter l'instruction voulue : c'est l'étape de décodage (Decode) ;
- enfin, le séquenceur configure le chemin de données pour exécuter l'instruction : c'est l'étape d’exécution (Execute).
On verra plus tard dans le cours qu'une quatrième étape peut être ajoutée : l'étape d'interruption. Celle-ci permet de gérer des fonctionnalités du processeur nommées interruptions. Nous en parlerons dans le chapitre sur la communication avec les entrées-sorties.
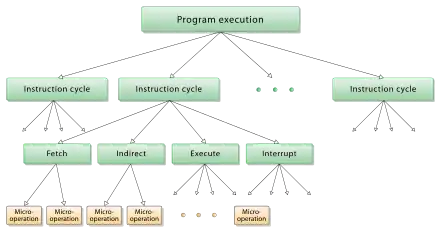
Les micro-instructions
Ces trois étapes ne s'effectuent cependant pas d'un seul bloc. Chacune de ces étapes est elle-même découpée en plusieurs sous-étapes, qui va échanger des données entre registres, effectuer un calcul, ou communiquer avec la mémoire. Pour l'étape de Fetch , on peut être sûr que tous les processeurs vont faire la même chose : il n'y a pas 36 façons pour lire une instruction depuis la mémoire. Même chose pour la plupart des processeur, pour l'étape de décodage. Mais cela change pour l'étape d’exécution : toutes les instructions n'ont pas les mêmes besoins suivant ce qu'elles font ou leur mode d'adressage. Voyons cela avec quelques exemples.
Commençons par prendre l'exemple d'une instruction de lecture ou d'écriture en mode d'adressage absolu. Vu son mode d'adressage, l'instruction va indiquer l'adresse à laquelle lire dans sa suite de bits qui la représente en mémoire. L’exécution de l'instruction se fait donc en une seule étape : la lecture proprement dite. Mais si l'on utilise des modes d'adressages plus complexes, les choses changent un petit peu. Reprenons notre instruction Load, mais en utilisant une mode d'adressage utilisé pour des données plus complexe. Par exemple, on va prendre un mode d'adressage du style Base + Index. Avec ce mode d'adressage, l'adresse doit être calculée à partir d'une adresse de base, et d'un indice, les deux étant stockés dans des registres. En plus de devoir lire notre donnée, notre instruction va devoir calculer l'adresse en fonction du contenu fourni par deux registres. L'étape d’exécution s'effectue dorénavant en deux étapes assez différentes : une implique un calcul d'adresse, et l'autre implique un accès à la mémoire.
Prenons maintenant le cas d'une instruction d'addition. Celle-ci va additionner deux opérandes, qui peuvent être soit des registres, soit des données placées en mémoires, soit des constantes. Si les deux opérandes sont dans un registre et que le résultat doit être placé dans un registre, la situation est assez simple : la récupération des opérandes dans les registres, le calcul, et l'enregistrement du résultat dans les registres sont trois étapes distinctes. Maintenant, autre exemple : une opérande est à aller chercher dans la mémoire, une autre dans un registre, et le résultat doit être enregistré dans un registre. On doit alors rajouter une étape : on doit aller chercher la donnée en mémoire. Et on peut aller plus loin en allant cherche notre première opérande en mémoire : il suffit d'utiliser le mode d'adressage Base + Index pour celle-ci. On doit alors rajouter une étape de calcul d'adresse en plus. Ne parlons pas des cas encore pire du style : une opérande en mémoire, l'autre dans un registre, et stocker le résultat en mémoire.
Bref, on voit bien que l’exécution d'une instruction s'effectue en plusieurs étapes distinctes, qui vont soit faire un calcul, soit échanger des données entre registres, soit communiquer avec la RAM. Chaque étape s'appelle une micro-opération, ou encore µinstruction. Toute instruction machine est équivalente à une suite de micro-opérations exécutée dans un ordre précis. Dit autrement, chaque instruction machine est traduite en suite de micro-opérations à chaque fois qu'on l’exécute. Certaines µinstructions font un cycle d'horloge, alors que d'autres peuvent prendre plusieurs cycles. Un accès mémoire en RAM peut prendre 200 cycles d'horloge et ne représenter qu'une seule µinstruction, par exemple. Même chose pour certaines opérations de calcul, comme des divisions ou multiplication, qui correspondent à une seule µinstruction mais prennent plusieurs cycles.
La micro-architecture d'un processeur
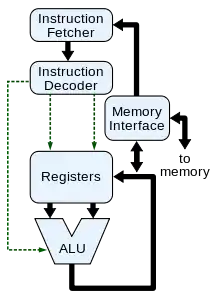
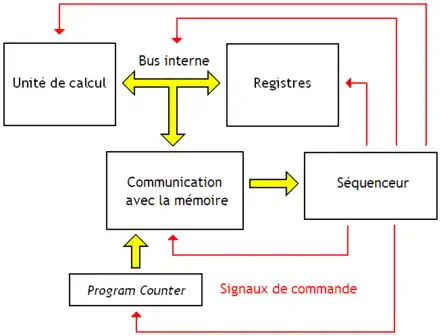
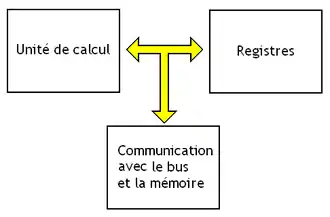
Conceptuellement, il est possible de segmenter les circuits du processeur en circuits spécialisés : des circuits chargés de faire des calculs, d'autres chargés de gérer les accès mémoires, etc. Ces circuits sont eux-mêmes regroupés en deux entités : le chemin de données et l'unité de contrôle. Le premier est l'ensemble des composants où circulent les données. Le second charge et interprète les instructions, pour commander le chemin de données. L'unité de contrôle regroupe un circuit chargé du Fetch, et un décodeur chargé de l'étape de Decode. Le chemin de données, quant à lui, regroupe l'unité de calcul, les registres et un circuit de communication avec la mémoire. Le tout est illustré ci-contre.
Le chemin de données
Pour effectuer ces calculs, le processeur contient un circuit spécialisé : l'unité de calcul. De plus, le processeur contient des registres, ainsi qu'un circuit chargé des communications avec la mémoire. Les registres, l'unité de calcul, et les circuits de communication avec la mémoire sont reliés entre eux par un ensemble de fils afin de pouvoir échanger des informations : par exemple, le contenu des registres doit pouvoir être envoyé en entrée de l'unité de calcul, pour additionner leur contenu par exemple. Ce groupe de fils forme ce qu'on appelle le bus interne du processeur. L'ensemble formé par ces composants s’appelle le chemin de données. On l'appelle ainsi parce que c'est dans ce chemin de données que les données vont circuler et être traitées dans le processeur.
L'unité de contrôle
Si le chemin de données s'occupe de tout ce qui a trait aux donnés, il est complété par un circuit qui s'occupe de tout ce qui a trait aux instructions elles-mêmes. Ce circuit, l'unité de contrôle va notamment charger l'instruction dans le processeur, depuis la mémoire RAM. Il va ensuite configurer le chemin de données pour effectuer l'instruction. Il faut bien contrôler le mouvement des informations dans le chemin de données pour que les calculs se passent sans encombre. Pour cela, l'unité de contrôle contient un circuit : le séquenceur. Ce séquenceur envoie des signaux au chemin de données pour le configurer et le commander.
Il est évident que pour exécuter une suite d'instructions dans le bon ordre, le processeur doit savoir quelle est la prochaine instruction à exécuter : il doit donc contenir une mémoire qui stocke cette information. C'est le rôle du registre d'adresse d'instruction, aussi appelé program counter. Cette adresse ne sort pas de nulle part : on peut la déduire de l'adresse de l'instruction en cours d’exécution par divers moyens plus ou moins simples. Généralement, on profite du fait que le programmeur/compilateur place les instructions les unes à la suite des autres en mémoire, dans l'ordre où elles doivent être exécutées. Ainsi, on peut calculer l'adresse de la prochaine instruction en ajoutant la longueur de l'instruction chargée au program counter. Mais sur d'autres processeurs, chaque instruction précise l'adresse de la suivante. Ces processeurs n'ont pas besoin de calculer une adresse qui leur est fournie sur un plateau d'argent.