Si vous programmez depuis un certain temps, vous savez sûrement qu'il existe plusieurs paradigmes de programmation : le paradigme procédural, l'impératif, l'objet, le fonctionnel, etc. Au départ, les premiers ordinateurs étaient optimisés pour exécuter des langages de programmation impératifs très simples. Puis l'assembleur de ces processeurs a évolué pour supporter les fonctionnalités des langages de haut niveau : le nombre de types supportés par le processeur s'est étoffé, des instructions spéciales pour supporter les sous-programmes ont été inventées, et de nombreux modes d'adressage dédiés aux tableaux et structures ont fait leur apparition. Toutes ces améliorations ont fait que nos processeurs sont particulièrement adaptés à des langages procéduraux de haut niveau comme le C, le Pascal, le BASIC ou le Fortran. Quand la programmation orientée objet s'est démocratisée dans les années 1980, des processeurs prenant en charge la programmation orientée objet ont été inventés (l'Intel iAPX 432, par exemple). De même, il existe de nombreuses architectures spécialement adaptées à l’exécution de langages fonctionnels ou logiques. Ces architectures étaient assez étudiées dans les années 1980, mais sont aujourd’hui tombées en désuétude.
Les machines LISP et SECD
Les premières tentatives se contentaient de quelques fonctionnalités architecturales qui accéléraient l’exécution des langages fonctionnels, tels des architectures à tags pour gérer le typage dynamique en matériel, des ramasse-miettes matériels ou du filtrage par motif en matériel. Dans le genre, on peut citer les machines Lisp.
L'étape suivante allait un peu plus loin que simplement accélérer certaines fonctionnalités des langages fonctionnels. Comme vous le savez sûrement, les langages de programmation sont souvent compilés vers un langage intermédiaire, avant d'être transformés en langage machine. Ce langage intermédiaire peut être vu comme l'assembleur d'une machine abstraite, que l'on appelle une machine virtuelle. Les concepteurs de langages fonctionnels apprécient notamment la machine SECD. Celle-ci a été implémentée en matériel par plusieurs équipes, par l'intermédiaire de micro-code. La première implémentation a été créée par les chercheurs de l'université de Calgary, en 1989. D'autres architectures ont effectué la même chose, en rajoutant des instructions notamment. D'autres processeurs implémentent des machines virtuelles différentes, comme les combinateurs SKIM, ou toute autre machine virtuelle pour langages fonctionnels.
Ce n'est que par la suite que de véritables architectures spécialisées pour les langages fonctionnels ont vu le jour, les architectures par réduction de graphe et les architectures dataflow en étant les deux exemples cardinaux. Nous laissons de côté des architectures dataflow, abordées dans un chapitre précédent pour nous concentrer sur les architectures à réduction et réécriture.
Les architectures à réduction
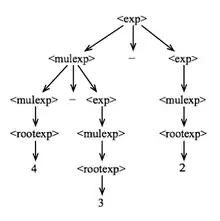
Poursuivre ce chapitre nous demandera quelques rappels sur les langages fonctionnels. Pour rappel, la syntaxe d'un langage de programmation décrit toujours un certain nombre de primitives : des constantes, des variables, des opérateurs, des fonctions, etc. Ces primitives peuvent ensuite être combinées ensemble pour calculer un résultat, une valeur : l'ensemble forme alors une expression. Un programme écrit dans un langage fonctionnel peut être vu comme une grosse expression, elle-même composée de sous-expressions, et ainsi de suite. Exécuter un programme écrit dans un langage fonctionnel, c'est simplement l'évaluer, à savoir lui donner une valeur.
Il existe diverses méthodes pour évaluer une expression, lui donner sa valeur. La première démarre l'évaluation quand toutes les valeurs des primitives sont connues : on parle d'évaluation stricte. L'autre méthode calcule l'expression au fil de l'eau, au fur et à mesure que ses primitives renvoient une valeur : on parle d'évaluation non stricte. Les architectures qui vont suivre sont capables d'évaluer un programme fonctionnel en utilisant une stratégie non stricte. Beaucoup d’entre elles sont des architectures qui n'ont pas été construites en matériel, mais qui ont été inventées en tant que machines virtuelles, à savoir comme jeu d'instruction d'une machine fictive, utilisé lors de la compilation d'un programme. Mais rien n’empêche ces architectrues d'être fabriquées avec des circuits électroniques.
Les architectures à réécriture (réduction de chaines)
Les architectures à réécriture de chaine de caractère stockent le programme sous la forme d'une chaine de caractères qui est éditée au fur et à mesure de l’exécution du programme. Au fur et à mesure que les expressions sont calculées, la chaine de caractères qui leur correspond est réécrite : elle est remplacée par la valeur évaluée. Ces architectures sont des architectures à réécriture. Comme architectures qui fonctionnent sur ce principe, on trouve :
- la Magó's FFP machine ;
- la GMD reduction machine ;
- la Newcastle reduction machine ;
- la cellular tree machine.
Les architectures à réduction de graphes
Sur les architectures à réduction de graphe, l'expression est représentée sous la forme d'un graphe dont les nœuds sont des constantes, variables, opérateurs ou fonctions. Évaluer une expression, c'est simplement remplacer les nœuds correspondant aux opérateurs, par les valeurs calculées. Le graphe est ainsi progressivement réduit, jusqu'à ce qu'il n'y ait plus qu'un seul nœud : le résultat. Les architectures à réduction de graphe sont conçues pour effectuer automatiquement cette réduction.
Chaque nœud d'un graphe est stocké sous la forme d'une structure, dont le format dépend de l'ordinateur. Réduire un nœud demande de créer un nouveau nœud pour le résultat de la réduction, et de mettre à jour les pointeurs vers le nœud initial (pour qu'il pointe vers le résultat et non l'opérateur). La conséquence, c'est que les architectures à réduction de graphe doivent allouer elles-mêmes les nœuds et doivent mettre à jour les pointeurs automatiquement. Ces architectures effectuent aussi le ramasse-miettes en matériel.
Diverses architectures spécialisées dans la réduction de graphes ont été implémentées. Certaines de ces architectures étaient des processeurs normaux auxquels des instructions de réduction de graphe étaient ajoutées via microcode. D'autres sont des machines multiprocesseurs. Plus récente, on pourrait citer le Reduceron, une architecture monoprocesseur qui exécute du code machine fonctionnel sans microcode. Voici une liste non exhaustive de ces architectures à réduction de graphe :
- la machine ALICE ;
- la machine GRIP ;
- la machine de COBWEB ;
- la machine de COBWEB-2 ;
- la machine Rediflow ;
- la SKIM machine ;
- la machine PACE ;
- l'architecture AMPS ;
- l'APERM machine ;
- la machine MaRS-Lisp ;
- le Reduceron ;
- la machine NORMA.