De nos jours, les processeurs avec plusieurs cœurs sont devenus la norme. L'utilité de tels processeurs est très simple : la performance ! Ils exécutent des instructions indépendantes dans des processeurs séparés, ce qui porte le doux nom de parallélisme. Mais les processeurs multicœurs ne sont pas les seuls processeurs permettant de faire ceci. Entre les ordinateurs embarquant plusieurs processeurs, les architectures dataflow, les processeurs vectoriels et les autres architectures parallèles, il y a de quoi être perdu. Pour se faciliter la tâche, diverses classifications ont été inventées pour mettre un peu d'ordre dans cette jungle de processeurs.
Le partage de la mémoire
On peut classer les architectures parallèles suivant comment se partage la mémoire entre les processeurs.
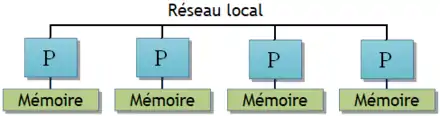
La première catégorie utilise une mémoire partagée entre tous les processeurs. Rien n’empêche plusieurs processeurs de vouloir accéder à la mémoire en même temps, ce qui demande d'implémenter de quoi arbitrer les accès à la mémoire entre les processeurs (interruptions inter-processeurs, instructions atomiques, cohérence des caches et autres). Les couts de synchronisation peuvent être conséquents et peuvent réduire les performances.

Viennent ensuite les architectures distribuées où chaque processeur possède sa propre mémoire. Les processeurs peuvent accéder à la mémoire d'un autre processeur via le réseau local, qui permet les transferts entre processeurs. Les communications entre les différents processeurs peuvent prendre un temps relativement long, loin d'être négligeable. Il va de soi que les communications sur le réseau peuvent prendre du temps : plus le réseau est rapide, meilleures seront les performances.
Il est possible d'utiliser des caches aussi bien sur des architectures distribuées qu'avec la mémoire partagée. Néanmoins, la gestion des caches peut poser quelques problèmes quand une donnée est présente dans plusieurs caches distincts. Chaque processeur pouvant modifier cette donnée indépendamment des autres, les données dans un cache peuvent ne pas être à jour. Or, éviter tout problème demande d'avoir une valeur à jour de la donnée dans l'ensemble de ses caches : cela s'appelle la cohérence des caches. Pour cela, les mises à jour dans un cache doivent être propagées dans les caches des autres processeurs. Nous aborderons le sujet en détail plus tard, dans quelques chapitres.
 Architecture à mémoire partagée avec des caches dédiés pour chaque CPU. |
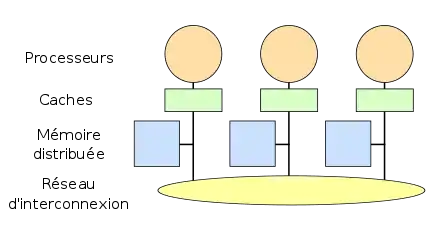 Architecture distribuée avec des caches. |
La taxonomie de Flynn
Dans les années 1966, un scientifique américain assez connu dans le milieu du hardware qui se nomme Flynn a classé ces architectures en 4 grandes catégories : SISD, SIMD, MISD, et MIMD.
Les architectures SISD sont incapables de toute forme de parallélisme.
Les architectures SIMD exécutent une instruction sur plusieurs données à la fois. Avec cette solution, les processeurs exécutent un seul et unique programme ou une suite d'instructions, mais chaque processeur travaille sur une donnée différente.
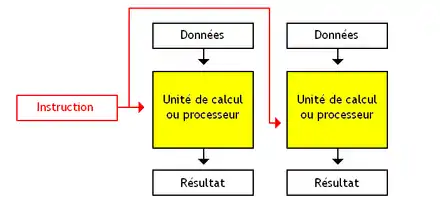
Les architectures MISD exécutent des instructions différentes en parallèle sur une donnée identique. Les architectures MISD sont vraiment très rares et les seuls exemples sont les architectures systoliques et cellulaires.
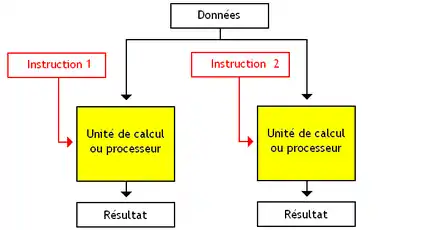
Les architectures MIMD exécutent des instructions différentes sur des données différentes. La catégorie MIMD est elle-même découpée en deux sous-catégories.
- Le Single Program Multiple Data , ou SPMD, consiste à exécuter un seul programme sur plusieurs données à la fois : la différence avec le SIMD est que le SPMD peut exécuter des instructions différentes d'un même programme sur des données.
- Le Multiple Program Multiple Data, qui consiste à exécuter des programmes en parallèle sur des données différentes. On peut ainsi découper un programme en sous-programmes indépendants exécutables en parallèle ou exécuter plusieurs copies d'un programme. Dans les deux cas, chaque copie ou morceau de programme est appelé un thread.
Les processeurs multicœurs et multiprocesseurs font partie de la catégorie MIMD.
| \ | Données traitées en série | Données traitées en parallèle |
|---|---|---|
| Instructions traitées en série | SISD | SIMD |
| Instructions traitées en parallèle | MISD | MIMD |
La taxinomie de Flynn n'est pas parfaite, dans le sens où certaines architectures sont difficiles à classer. Mais cette classification, bien que simpliste, est particulièrement didactique et a remarquablement tenu le coup au fil du temps.
Le parallélisme de données et de tâches
Les architectures SIMD et SPMD effectuent ce qu'on appelle du parallélisme de données, à savoir exécuter un même programme sur des données différentes, en parallèle. La quasi-totalité des processeurs est aujourd'hui de ce type, qu'il s'agisse des processeurs Intel et AMD actuels ou de leurs confrères de chez ARM, MIPS et VIA. Le parallélisme de donnée est aussi massivement utilisé dans les cartes graphiques : chaque calcul sur un pixel est plus ou moins indépendant des transformations qu'on effectue sur ses voisins.
Le parallélisme de données s'oppose au parallélisme de tâches, qui exécute plusieurs programmes en parallèle. Il s'exploite en découpant un programme en sous-programmes indépendants qu'on peut exécuter en parallèle. Ces sous-programmes indépendants sont ce qu'on appelle des Threads. Les architectures permettant d’exécuter des threads en parallèle sont les architectures multiprocesseurs ou multicœurs, ainsi que quelques autres processeurs un peu spéciaux. Le découpage d'un programme en threads est avant tout un problème logiciel, du ressort du compilateur, du programmeur, voire du langage de programmation. Mais, plus étonnant, certains processeurs sont capables de découper un programme à l’exécution, éventuellement grâce à des indications fournies par le programme lui-même ! C'est tout de même assez rare, même si cela a déjà été tenté : on reviendra dessus quand je parlerai des architectures EDGE et du speculative multithreading dans ce tutoriel.
Les deux formes de parallélisme n'ont pas du tout la même efficacité, comme nous allons le voir. Pour faire la comparaison entre les deux, nous allons voir la loi d'Amdhal, qui décrit le parallélisme de tâche, et la loi de Gustafson, qui décrit le parallélisme de données.
Le parallélisme de tâches : la loi d'Amdhal
La loi d'Amdhal donne l’amélioration maximale que l'on peut obtenir d'un programme parallèle, quand il s’exécute sur plusieurs processeurs. Pour la calculer, on suppose que ce code parallèle peut tout aussi bien exploiter la puissance d'un seul processeur, que de 2, 20, voir 10 000 000 processeurs. Bref, le code est quasiment parfait et on s'interdit les situations du style : on observe un gain énorme avec 2 ou 4 processeurs, mais pas au-delà. De plus, ce programme est exécuté sur la même quantité de données : on ne rajoute pas de données en même temps qu'on ajoute des processeurs, et ces données ont toujours la même taille, histoire de comparer ce qui est comparable.
La limite du parallélisme de tâches tient dans le fait que tous les programmes ne peuvent pas utiliser plusieurs processeurs à la perfection. Tout programme conserve une certaine portion de code qui ne profite pas du parallélisme. Appelons cette portion de code le code série, tandis que la portion de code qui profite du parallélisme sera appelée le code parallèle. Le ou les processeurs passeront un certain temps à exécuter le code série, et un autre temps dans le code parallèle. Notons ces deux temps et . On sait que le temps mis par un programme à s'exécuter vaut donc :




Seconde hypothèse : le code parallèle profite au mieux de la présence de plusieurs processeurs. Dit autrement, si on possède processeurs, tous auront une part égale du code parallèle, en temps d'exécution. Dans ces conditions, le temps d'exécution du programme devient celui-ci :


Ces deux formules nous permettent de calculer le rapport entre le temps sans parallélisme et celui avec. On a alors :

Maintenant, notons et le pourcentage de temps d’exécution passé respectivement dans le code série et dans le code parallèle. Par définition, ces deux pourcentages valent et . Dans l'équation précédente, on peut identifier ces deux pourcentages (leur inverse, précisément). On a alors, en faisant le remplacement :





Cette formule nous permet de calculer le gain obtenu grâce au parallélisme. Ce gain se calcule en divisant le temps avant parallélisation et le temps obtenu après. C'est intuitif : si un programme va deux fois plus vite, c'est que son temps d’exécution a été divisé par deux entre avant et après. Dit autrement, il s'agit de l'inverse du rapport calculé précédemment. L'équation obtenue ainsi, qui donne le gain en performance que l'on peut attendre en fonction du nombre de processeur et du pourcentage de code parallèle, est appelée la loi d'Amdhal.

Cette formule, la loi d'Amdhal proprement dit, nous donne donc une estimation du gain en temps d’exécution d'une application exécutée sur plusieurs processeurs. Mais que peut-on en déduire d'utile ? Peut-on trouver des moyens de gagner en performance efficacement grâce à cette loi ? Oui, et c'est ce qu'on va voir.
La limite du code série
On peut déduire de cette loi qu'il existe une limite maximale du gain obtenu par parallélisme de tâche. Quand on fait tendre le nombre de processeurs vers l'infini, le gain atteint un maximum qui vaut :

Quand N tend vers l'infini, le code parallélisé est exécuté en un temps qui tend vers 0 et seul reste le code série. Dit autrement, le temps d’exécution d'un programme ne peut pas descendre en dessous du temps d’exécution du code série, même avec une infinité de processeurs. La solution la plus simple est donc réduire S et augmenter P le plus possible. Seul problème : tous les programmes ne se laissent pas paralléliser aussi facilement. Certains programmes se parallélisent facilement parce que les calculs qu'ils ont à faire sont assez indépendants. Mais d'autres n'ont pas cette particularité et sont très très difficilement parallélisables, voire pas du tout.
L'influence du nombre de CPU
La loi d'Amdhal nous dit qu'augmenter le ombre de processeur permet de diminuer le terme et d'augmenter le gain. Mais cette solution a une efficacité assez limitée : il faut que la part de code parallélisable soit suffisante pour que cela ait un impact suffisant. Imaginons un exemple simple : 20% du temps d’exécution de notre programme (quand il est exécuté sur un seul processeur) est passé à exécuter du code parallèle. Si on calcule le gain en fonction du nombre de processeurs, on obtient alors la tableau suivant.

| Nombre de processeurs | Gain maximal |
|---|---|
| 2 | 11.11% |
| 3 | 15.38% |
| 4 | 17.64% |
| 5 | 19.04% |
| 6 | 20% |
| 7 | 20.6% |
| 8 | 21.21% |
| ... | ... |
| 16 | 23% |
| ... | ... |
| 25% |

Les chiffres précédents nous disent qu'aller au-delà de 5 ou 6 processeurs ne sert pas vraiment à grand-chose. Doubler leur nombre revient souvent à augmenter les performances d'un misérable pourcent. Pour prendre un autre exemple, au-delà de 8 processeurs, un code passant 50% de son temps à exécuter du code parallèle ne sera pas vraiment exécuté plus vite. Pour résumer, le rendement du parallélisme diminue rapidement avec le nombre de processeurs. Passer de 2 à 4 processeurs permet d'obtenir des gains substantiels, alors que passer de 16 à 32 processeurs ne donne de gains sensibles que si P est extrêmement élevé.

Les limites pratiques
Il faut préciser que la loi d'Amdhal est optimiste : elle a été démontrée en postulant que le code parallèle peut être réparti sur autant de processeurs qu'on veut et peut profiter d'un grand nombre de processeurs. Dans la réalité, rares sont les programmes de ce genre : certains programmes peuvent à la rigueur exploiter efficacement 2, 4 , voir 8 processeurs mais pas au-delà. Elle ne tient pas compte des nombreux problèmes techniques, aussi bien logiciels que matériels qui limitent les performances des programmes conçus pour exploiter plusieurs processeurs. La loi d'Amdhal donne une borne théorique maximale au gain apporté par la présence de plusieurs processeurs, mais le gain réel sera quasiment toujours inférieur au gain calculé par la loi d'Amdhal.
Le parallélisme de données : la loi de Gustafson
Le parallélisme de données est très utilisé pour des applications où les données sont indépendantes, et peuvent se traiter en parallèle. Un bon exemple est le calcul des graphismes d'un jeu vidéo. Chaque pixel étant colorié indépendamment des autres, on peut rendre chaque pixel en parallèle. C'est pour cela que les cartes vidéo contiennent un grand nombre de processeurs et sont des architectures SIMD capables d’exécuter un grand nombre de calculs en parallèle.
Le parallélisme de données n'a pas les limitations intrinsèques au parallélisme de tâches. En effet, celui-ci est avant tout limité certes par le code série, mais aussi par la quantité de données à traiter. Prenons le cas d'une carte graphique, par exemple : ajouter des processeurs ne permet pas de diminuer le temps de calcul, mais permet de traiter plus de données en même temps. Augmenter la résolution permet ainsi d'utiliser des processeurs qui auraient été en trop auparavant. Reste à quantifier de tels gains, si possible avec une loi similaire à celle d'Amdhal. Pour cela, nous allons partir du cas où on dispose d'un processeur qui doit traiter N données. Celui-ci met un temps à éxecuter le code série et un temps pour traiter une donnée. On a donc :

Avec N processeurs, le traitement des N données s'effectuera en un temps , vu qu'il y a une donnée est prise en charge par un processeur, sans temps d'attente.

Le gain est donc :

On peut utiliser les définitions et pour reformuler l'équation précédente :



On voit que le gain est proportionnel au nombre de données à traiter. Plus on a de données à traiter, plus on gagnera à utiliser un grand nombre de processeurs. Il n'y a pas de limites similaires à celles obtenues à la loi d'Amdhal, du moins, tant qu'on dispose de suffisamment de données à traiter en parallèle.
