Dans les années 1970 à 1980, les chercheurs tentaient de créer des architectures parallèles sans program counter. Les architectures dataflow furent une de ces réponses. Sur ces architectures, une instruction s’exécute dès que ses opérandes sont disponibles, comme sur les architectures à exécution dans le désordre. Sauf que cette fois-ci, le jeu d'instruction et le compilateur qui s'occupent de la gestion des dépendances. Il va de soi qu'un programme sur une architecture dataflow doit préciser les dépendances de données entre instructions, vu que le program counter a disparu. Pour cela, chaque instruction indique l'adresse mémoire de toute instruction qui a besoin de son résultat. Vu que chaque instruction ne s'exécute que si ses opérandes sont disponibles — ont été calculés — détecter la disponibilité des opérandes des instructions est alors primordial.
Pour supprimer ces dépendances, les compilateurs ajoutent une contrainte simple : impossible de modifier la valeur d'une donnée/variable après son initialisation. Or, les langages fonctionnels permettent d'initialiser une variable lors de sa création, mais pas de la modifier !
Le modèle de calcul dataflow théorique

Il va de soi qu'avec ce qu'on a dit plus haut, un programme conçu pour une architecture dataflow n'est pas une simple suite d'instruction. Un programme de ce type contient les instructions du programme et précise les dépendances de données entre instructions. Sur ces processeurs, un programme sera ce qu'on appelle un graphe orienté acyclique, un objet mathématique assez particulier qu'on va décrire assez rapidement. Pour faire simple, un graphe est un ensemble de points qu'on relie par des flèches. Avec un graphe orienté, les flèches ont un sens. Le terme acyclique signifie qu'il n'y a pas de boucles dans le graphe.
Sur les processeurs dataflow, les points du graphe sont les instructions du programme, alors que les flèches entre instructions représentent chacune une dépendance de donnée de type RAW.
La représentation du programme
Les instructions arithmétiques et logiques consomment leurs entrées et fournissent un résultat sans rien faire d'autre : elles sont sans aucun effet de bord. Mine de rien, cela n'est pas le cas sur les autres architectures, où ces instructions peuvent écraser une donnée, modifier des bits de contrôle du registre d'état, lever des exceptions matérielles, etc. Rien de tout cela n'est permis sur les architectures dataflow, afin de limiter les effets de bords, honnis dans le paradigme fonctionnel. Cela permet de plus de garder un maximum d'opportunités de parallélisation.

Outre les instructions normales, on trouve des instructions équivalentes aux instructions de tests et de branchements, appelées switch et merge. Pour faire simple, les merges sont des instructions qui effectuent des comparaisons ou des tests et qui fournissent un résultat du style : la propriété testée est vraie (ou fausse). Les switch quant à eux, sont l'équivalent des instructions de branchements, vues plus haut.
 Switch. |
 Merge. |
Deux instructions seront reliées par une flèche si elles ont une dépendance de donnée. La flèche va de l'instruction qui calcule l'opérande vers celle qui va utiliser le résultat. Rien n’empêche à une instruction de manipuler le résultat de plusieurs instructions différentes, mais il n'y a pas de boucles, du fait de l'acyclicité du graphe. Le stockage de ce graphe, ce programme, dépend de l'ordinateur utilisé, mais vous pouvez être certains qu'il est stocké quelque part (même si parfois de manière implicite) dans la mémoire de l'ordinateur et que le processeur utilise celui-ci pour savoir quelles instructions exécuter et dans quel ordre.
 Extrait de programme dataflow (graphe simple) avec plusieurs instructions arithmétiques. |
 Code dataflow avec une conditionnelle (un IF/ELSE). |
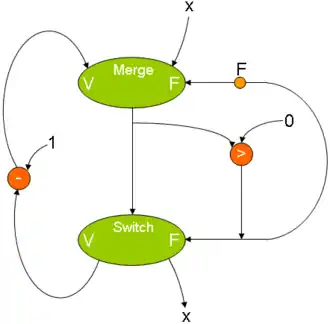 Code dataflow avec une boucle WHILE. |
La gestion de la disponibilité des opérandes
Il n'est pas rare qu'une instruction doive attendre un certain évènement avant que ses opérandes soient disponibles. Par exemple, c'est le cas si une instruction attend que des opérandes soient tapés au clavier ou proviennent d'une carte réseau. Dans ce cas, certaines flèches partiront de données, qui seront fournies par des périphériques ou qui seront présentes en mémoire au lancement du programme. Reste que lorsque le programme s’exécute, il faut que le processeur sache s'il peut sauter d'un point à un autre, ce qui correspond à déclencher l’exécution d'une nouvelle instruction. Pour cela, il a besoin de savoir quelles sont les données disponibles (ainsi que les instructions auxquelles elles sont destinées).
Pour cela, il va attribuer aux données disponibles ce qu'on appelle un jeton. Il permet de se repérer dans le graphe vu au-dessus en mémorisant, pour une donnée, l'adresse mémoire de la prochaine instruction à exécuter. Qui plus est, ce jeton contient aussi la donnée qui se voit attribuer le jeton et peut aussi éventuellement contenir certains renseignements supplémentaires. Il est stocké en mémoire, et va y attendre bien sagement qu'une instruction veulent bien l'utiliser. Le schéma qui suit montre la propagation des jetons suite à l’exécution d'une instruction sur un graphe dataflow.
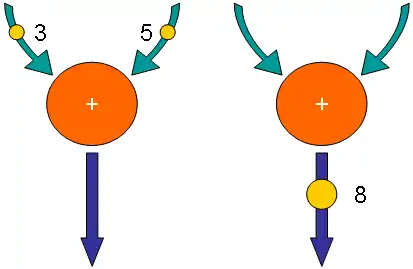
Chaque donnée de départ, fournie par un périphérique ou enregistrée en mémoire au lancement d'un programme, se voit attribuer un jeton qui signifie tout simplement que la donnée est disponible. Lorsque tous les opérandes d'une instruction ont leur jeton actif, l'instruction supprime les jetons de ses données et fournit un résultat, auquel on attribuera un nouveau jeton. En clair, les opérandes auront été utilisés et ne sont plus disponibles, tandis que le résultat l'est. Un nouveau jeton sera alors crée pour le résultat et rebelote. L’exécution du programme consiste à propager les jetons à travers le graphe, ce qui se fera suivant les disponibilités des jetons. Quoi qu’il en soit, pour exécuter une instruction, il faudra détecter la disponibilité des jetons qu'elle manipule. Et c'est le processeur qui se chargera de vérifier la disponibilité des opérandes d'une instruction. Plus précisément, ce sera le rôle d'un circuit spécialisé, comme on le verra plus tard.
Les architectures dataflow statiques
La détection de la disponibilité des opérandes est primordiale sur les architectures dataflow. Dans ce qui va suivre, on va voir qu'il existe différentes façons de gérer ce jeton, qui peuvent être plus ou moins évoluées suivant l'ordinateur dataflow utilisé. Le principal problème avec les jetons, c'est qu'ils doivent parfois attendre que leur instruction ait réuni toutes ses opérandes pour être utilisés. Dans pas mal de cas, les jetons n'attendent pas longtemps et un nouveau jeton n'a pas le temps d'arriver entre-temps. Mais il se peut qu'un nouveau jeton arrive avant que le précédent soit consommé. On est alors face à un problème : comment faire pour différencier l'ancienne donnée, qui doit être utilisée dans le calcul à faire, de la donnée du jeton nouveau venu ?
La première solution est celle utilisée sur les architectures dataflow statiques. Sur ces architectures, on n'a qu'un seul jeton de disponible pour chaque opérande, par construction. Une instruction ne peut pas avoir plusieurs valeurs différentes d'une même opérande en attente, chose qui serait possible avec l'usage de boucles, par exemple. Dit autrement, chaque flèche du graphe ne doit contenir qu'un seul jeton à la fois lors de l’exécution du programme.
Le codage des instructions
Une instruction contient, outre son opcode, un espace pour stocker les opérandes (les jetons) et des bits de présence qui indiquent si l'opérande associé est disponible. Les jetons sont donc stockés dans l'instruction et sont mis à jour par réécriture directe de l'instruction en mémoire. De plus, chaque instruction contient l'adresse de l'instruction suivante, celle à laquelle envoyer le résultat. Tout cela ressemble aux entrées des stations de réservation sur les processeurs à exécution dans le désordre, à un détail près : tout est stocké en mémoire, dans la suite de bits qui code l'instruction. Vu qu'une instruction contient ses propres opérandes, on préfère parfois utiliser un autre terme que celui d'instruction et on parle d'activity template.
 Illustration du codage de haut niveau d'une instruction sur une architecture dataflow statique. On voit bien que chaque instruction a un espace réservé pour chaque opérande. |
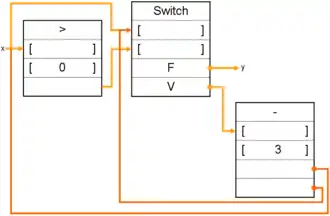 Même chose, mais avec des instructions Switch et Merge. |
Avec cette technique, il faut empêcher une instruction de fournir un résultat si une autre donnée est en train d'attendre sur la même flèche. Pour empêcher cela, chaque instruction contient un bit qui indique si elle peut calculer un nouveau résultat. Ce bit est appelé le jeton d'autorisation. Quand une instruction s’exécute, elle prévient les instructions qui ont calculé ses opérandes qu'elle est prête à accepter un nouvel opérande. Les jetons de celles-ci sont mis à jour. Pour que cela fonctionne, chaque instruction doit savoir quelle est la ou les instructions qui la précédent dans l'ordre des dépendances, ce qui implique de mémoriser leurs adresses.

La microarchitecture d'une architecture dataflow statique
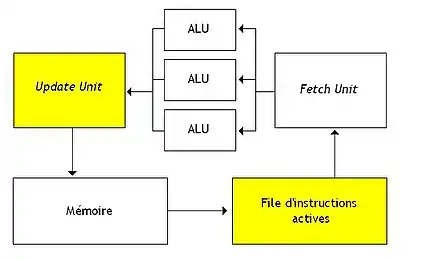
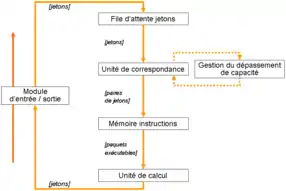
Dans les grandes lignes, une architecture dataflow statique est composée de plusieurs éléments, représentés sur le schéma que vous pouvez voir en dessous. La file d'instructions est une mémoire qui met en attente les instructions dont toutes les données sont prêtes : elle contient leurs adresses, qu'elle peut fournir à l'unité de chargement. L'unité de mise à jour enregistre les résultats des instructions en mémoire et met à jour les bits de présence. Elle vérifie aussi que l'instruction de destination du résultat a tous ses opérandes disponibles et charge celle-ci dans la file d'instructions si c'est le cas.
Les défauts de ces architectures
Ces architectures dataflow statiques ont de gros défauts. Le plus important est que certaines fonctionnalités importantes des langages de programmation fonctionnels ne sont pas implémentables sur ces architectures. Exemples : pas de fonctions de première classe, pas de fonctions réentrantes, ni de récursivité. Autant vous dire que ces architectures ne servent pas à grand chose. De plus, les boucles sont systématiquement exécutées en série, itérations après itérations, au lieu d’exécuter des itérations en parallèle quand c'est possible. En effet, lorsqu'on exécute plusieurs itérations d'une boucle, plusieurs versions des mêmes instructions peuvent s’exécuter en même temps : une version de la fonction par itération. Et chaque version va vouloir écrire dans les champs opérandes et mettre à jour les bits de présence. Heureusement, les jetons d'autorisation vont éviter tout problème, en ne laissant qu'une seule version (la plus ancienne) s'exécuter, en faisant attendre les autres.
Les architectures dataflow dynamiques
Pour résoudre les défauts des architectures dataflow statiques, il faut faire sauter la règle du "un jeton par flèche", ce qui est fait sur les architectures dataflow dynamiques. L'idée de ces architectures est d'associer, pour chaque jeton, l'exemplaire d'une fonction ou d'une boucle ils sont destinés. Pour cela, on ajoute des informations à côté de l'opérande, regroupées dans ce qu'on appelle le tag. Dorénavant, une instruction s’exécute une fois que tous ses opérandes ayant le même tag sont disponibles.
Sur les architectures statiques, les jetons avaient un emplacement pré-réservé dans les instructions mêmes. Mais sur les architectures dynamiques, on ne peut réserver de la place pour les opérandes à l'avance, vu qu'une instruction dans une boucle ou une fonction peut s’exécuter en un nombre indéterminé d'exemplaires. C'est maintenant aux jetons d'indiquer quelle est l'instruction qui doit les manipuler, en mémorisant son adresse. Les opérandes sont mémorisés à part des instructions, dans une mémoire séparée de la mémoire d'instructions (en clair, les architectures dynamiques sont de type Harvard). Les opérandes sont mis en attente dans une file d'attente. À chaque ajout d'un opérande dans la file d'attente, le processeur vérifie quels sont les opérandes de la file qui possèdent le même tag et la même adresse d'instruction.
La gestion des jetons change du tout au tout. Les jetons contiennent l'opérande, leur tag, et l'adresse de l'instruction de destination, ainsi que le nombre d'opérandes de cette instruction (afin de faciliter la détection de la disponibilité des opérandes de celle-ci). Dès qu'un jeton a été calculé par l'ALU, il est stocké dans la file d'attente des jetons disponibles. Reste à vérifier la disponibilité des opérandes. Si l'instruction a toutes ses opérandes disponibles dans cette file d'attente, il y a juste à les récupérer et à lancer l'instruction. Ainsi, à chaque ajout d'un jeton dans la file d'attente des jetons, on va vérifier quels sont les jetons présents dans cette file qui possèdent le même Tag, afin de charger celle-ci le cas échéant.

Il va de soi que vu les contraintes de fonctionnement de la file d’attente, celle-ci est une mémoire adressable par contenu, et précisément une mémoire associative. Le seul problème (car il y en a un) est que les performances d'une architecture dynamique dépendent fortement de la vitesse de cette mémoire adressable par contenu.
Les architectures Explicit Token Store
Les architectures Explicit Token-Store utilisent une sorte de pile. L'opérande est remplacé par deux choses : un pointeur vers le cadre de pile qui contient la donnée et de quoi localiser l'opérande dans la pile. Elle représente une amélioration assez conséquente des architectures précédentes. Sur ces machines, lorsqu’une fonction ou une boucle s’exécute, elle réserve un cadre de pile et y stocke ses opérandes et ses variables locales. A chaque appel d'une fonction ou à chaque itération d'une boucle, on crée un nouveau cadre pour les opérandes de la dite version. Ainsi, chaque fonction ou itération de boucle pourra avoir son propre jeu d'opérandes et de variables locales, permettant ainsi l'utilisation de fonctions ré-entrantes ou récursives et un déroulage matériel des boucles.
Ces cadres de pile sont localisés par leur adresse mémoire et les instructions ont juste à repérer la position dans le cadre de pile. La différence avec la pile des architectures usuelles tient dans le fait que les cadres de pile ne sont pas contiguës, mais peuvent être dispersées n'importe où et n'importe comment (ou presque) en mémoire. Qui plus est, les cadres de pile ne sont pas organisés avec une politique d'ajout et de retraits de type LIFO. Chaque donnée présente dans un cadre de pile possède des bits de présence, comme toutes les autres données.
Dans ces architectures, la mémoire est encore séparée en deux : une mémoire pour les instructions et une autre pour les cadres de pile. L’organisation est similaire aux architectures dynamiques, à un détail prêt : les cadres de pile sont stockées dans une mémoire tout ce qu'il y a de plus normale, avec des adresses et tout le reste.
Les architectures dataflow hybrides
Les architectures dataflow sont certes très belles et créatives, mais celles-ci souffrent de défauts qui empêchent de les utiliser de façon réellement efficace.
Premièrement, la gestion des jetons et des instructions est compliquée et utilise beaucoup de circuits. La détection de la disponibilité des opérandes d'une instruction est assez coûteuse et prend un certain temps, vu qu'elle est faite avec des mémoires associatives. Hors, les mémoires associatives sont redoutablement lentes, ce qui pose de gros problèmes de performances. Le temps d'accès à la mémoire est suffisant pour compenser tous les gains apportés par la parallélisation. Autre problème : la répartition des instructions prêtes sur les différentes unités de calcul prend un certain temps, difficile à amortir. Autre problème : les tags prennent de la mémoire, suffisamment pour devenir un problème. Ensuite, l'immutabilité des variables fait que la gestion des structures de données est laborieuse pour le compilateur et le programmeur, entraîne beaucoup d'allocations mémoires et augmente fortement le nombre de lectures et écritures en mémoire, comparé à un programme impératif.
Et ensuite, le plus gros problème de tous : ces architectures sont limitées par la rapidité de la mémoire RAM principale. La même chose a lieu dans les programmes impératifs sur des architectures normales, à la différence que celles-ci ont des caches et une hiérarchie mémoire, afin d'amortir le coût des accès mémoires. Mais ces techniques ne fonctionnent correctement que lorsque le code exécuté a une bonne localité temporelle et spatiale. Ce qui n'est franchement pas le cas des programmes conçus pour les architectures dataflow et des programmes fonctionnels en général (à cause de l'immutabilité de variables, d'allocations mémoires fréquentes, des structures de donnée utilisées, etc).
On peut toujours compenser ces défauts en exécutant beaucoup d'instructions en parallèle, mais rares sont les programmes capables d’exécuter un grand nombre d'instructions à exécuter en parallèle. Il faut dire que les dépendances de données sont légion et qu'il n'y a pas de miracles. On ne peut pas toujours trouver suffisamment d'instructions à paralléliser, sauf dans certains programmes, qui résolvent des problèmes particuliers. En conséquence, les architectures dataflow ont été abandonnées, après pas mal de recherches, en raison de leurs faibles performances. Mais certains chercheurs ont quand même décidé de donner une dernière chance au paradigme dataflow, en le modifiant de façon à le rendre un peu plus impératif.
Les architectures Threaded Dataflow
Ainsi sont nées les architectures Threaded Dataflow ! Sur ces architectures, un programme est découpé en plusieurs blocs d'instructions. À l'intérieur de ces blocs, les instructions s’exécutent les unes à la suite des autres. Par contre, les blocs eux-mêmes seront exécutés dans l'ordre des dépendances de données : un bloc commence son exécution quand tous les opérandes nécessaires à son exécution sont disponibles.
Les architecture Explicit Data Graph Execution
Les architectures Explicit Data Graph Execution se basent sur le fonctionnement des compilateurs modernes pour découper un programme procédural ou impératif en blocs de code. Généralement, ceux-ci vont découper un programme en petits morceaux de code qu'on appelle des blocs de base, qui sont souvent délimités par des branchements (ou des destinations de branchements). Ce sont ces blocs de base qui seront exécutés dans l'ordre des dépendances de données. Certaines architectures de ce type ont déjà été inventées, comme les processeurs WaveScalar et TRIPS.
Conclusion
Pour finir, sachez qu'il existe peu de documentation sur le sujet. Il s'agit d'un sujet de recherche assez ancien, et qui est un peu délaissé des dernières années. Quoi qu’il en soit, je recommande la lecture des liens qui suivent, pour se renseigner un peu plus sur le sujet :
Quelques liens sur l'architecture wavescalar :