Dans le chapitre sur les performances d'un ordinateur, on a vu que le temps d’exécution d'une instruction dépend du CPI, le nombre moyen de cycles d'horloge par instruction et de la durée P d'un cycle d'horloge. En conséquence, rendre les instructions plus rapides demande de diminuer le CPI ou d'augmenter la fréquence. Monter en fréquence a commencé à monter ses limites avec le processeur Pentium 4, les contraintes de consommation énergétique se faisant de plus en plus lourdes. Les concepteurs de processeurs ont alors cherché à optimiser au mieux les instructions les plus utilisées et se sont plus ou moins heurtés à un mur. Il est devenu évident au fil du temps qu'il fallait réfléchir hors du cadre et trouver des solutions innovantes, ne ressemblant à rien de connu. Ils ont fini par trouver une solution assez incroyable : exécuter plusieurs instructions en même temps ! Pour cela, il a bien fallu trouver quelques solutions diverses et variées, dont le pipeline est la plus importante.
Le pipeline : rien à voir avec un quelconque tuyau à pétrole !
Pour expliquer en quoi il consiste, il va falloir faire un petit rappel sur les différentes étapes d'une instruction. Dans le chapitre sur la micro-architecture d'un processeur, on a vu qu'une instruction est exécutée en plusieurs étapes bien distinctes : le chargement, le décodage, et diverses étapes pour exécuter l'instruction, ces dernières dépendant du processeur, du mode d'adressage, ou des manipulations qu'elle doit effectuer. Sans pipeline, ces étapes sont réalisées les unes après les autres et une instruction doit attendre que la précédente soit terminée avant de démarrer.
Avec un pipeline, on peut commencer à exécuter une nouvelle instruction sans attendre que la précédente soit terminée. Par exemple, on peut charger la prochaine instruction pendant que l'instruction en cours d’exécution en est à l'étape d'exécution. Après tout, ces deux étapes sont complètement indépendantes et utilisent des circuits séparés. Le principe du pipeline est simple : exécuter plusieurs instructions différentes, chacune étant à une étape différente des autres. Chaque instruction passe progressivement d'une étape à la suivante dans ce pipeline et on charge une nouvelle instruction par cycle dans le premier étage. Le nombre total d'étapes nécessaires pour effectuer une instruction (et donc le nombre d'étages du pipeline) est appelé la profondeur du pipeline. Il correspond au nombre maximal théorique d'instructions exécutées en même temps dans le pipeline.
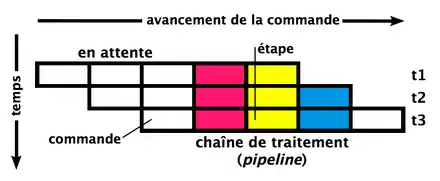
Pour comprendre ce que cela signifie, comparons l’exécution de cette instruction sans et avec pipeline. Pour l'exemple, nous allons utiliser une organisation relativement générale, où chaque instruction passe par les étapes suivantes :
- chargement : on charge notre instruction depuis la mémoire ;
- décodage : décodage de l'instruction ;
- exécution : on exécute l'instruction ;
- accès mémoire : accès à la mémoire RAM ;
- enregistrement : si besoin, le résultat de l’instruction est enregistré en mémoire.
Sans pipeline, on doit attendre qu'une instruction soit finie pour exécuter la suivante. L'instruction exécute toutes ses étapes, avant que l'instruction suivante démarre à l'étape 1.
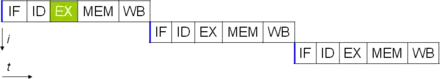
Avec un pipeline, on démarre une nouvelle instruction par cycle (dans des conditions optimales).

L'isolation des étages du pipeline
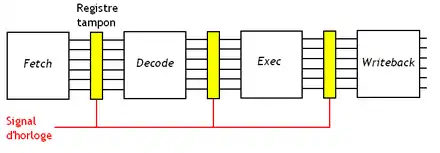
Concevoir un processeur avec un pipeline nécessite quelques modifications de l'architecture de notre processeur. Tout d'abord, chaque étape d'une instruction doit s'exécuter indépendamment des autres, ce qui signifie utiliser des circuits indépendants pour chaque étage. Il est donc impossible de réutiliser un circuit dans plusieurs étapes, comme on le fait dans certains processeurs sans pipeline. Par exemple, sur un processeur sans pipeline, l'additionneur de l'ALU peut être utilisé pour mettre à jour le program counter lors du chargement, calculer des adresses lors d'un accès mémoire, les additions, etc. Mais sur un processeur doté d’un pipeline, on ne peut pas se le permettre, ce qui fait que chaque étape doit utiliser son propre additionneur. De même, l'étage de chargement peut entrer en conflit avec d'autres étages pour l'accès à la mémoire ou au cache, notamment pour les instructions d'accès mémoire. On peut résoudre ce conflit entre étage de chargement et étage d’accès mémoire en dupliquant le cache L1 en un cache d'instructions et un cache de données. Et ce principe est général : il est important de séparer les circuits en charge de chaque étape. Chaque circuit dédié à une étape est appelé un étage du pipeline.
Les pipelines synchrones et asynchrones
La plupart des pipelines intercalent des registres entre les étages, pour les isoler. Les transferts entre registres et étages peuvent être synchronisés par une horloge, ou de manière asynchrone.
Si le pipeline est synchronisé sur l'horloge du processeur, on parle de pipeline synchrone. Chaque étage met un cycle d'horloge pour effectuer son travail, à savoir, lire le contenu du registre qui le relie à l'étape précédente et déduire le résultat à écrire dans le registre suivant. Ce sont ces pipelines que l'on trouve dans les processeurs Intel et AMD les plus récents.
Sur d'autres pipelines, il n'y a pas d'horloge pour synchroniser les transferts entre étages, qui se font via un « bus » asynchrone. On parle de pipeline asynchrone.
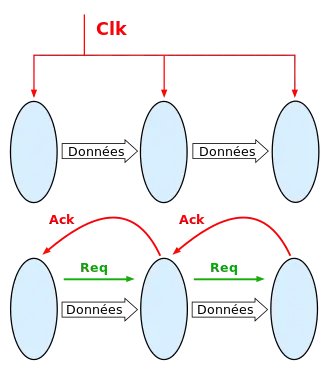
Les signaux de commande des pipelines asynchrones peuvent se créer facilement avec des portes C.
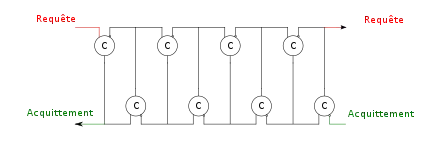
Le paradoxe des pipelines
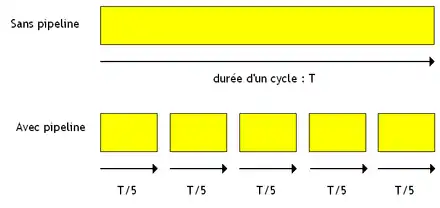
Revenons un peu sur les pipelines synchrones. Sur ceux-ci, un étage fait son travail en un cycle d'horloge. Sur un pipeline à N étages, une instruction met N cycles d'horloge à s’exécuter, contre un seul cycle sur un processeur sans aucun pipeline. Mais alors à quoi bon exécuter N instructions simultanément, si chaque instructions prend N fois plus de temps ? Le temps d’exécution d'un paquet d'instructions n'est pas censé changer ! Sauf que ce raisonnement oublie un paramètre important : un étage de pipeline a un temps de propagation plus petit qu'un processeur complet; ce qui permet d'en augmenter la fréquence. Cela permet donc de multiplier la fréquence par un coefficient plus ou moins proportionnel aux nombres d'étages.
On peut formaliser ce raisonnement mathématiquement, en posant :
- la latence de l’instruction avec pipeline en secondes ;
- la latence de l’instruction sans pipeline en secondes ;
- la latence d'un étage du pipeline en secondes ;
- le nombre d'étages du pipeline.




Supposons que les circuits du processeur peuvent être découpés en étages qui ont la même latence, à savoir qui mettent le même temps pour faire leur travail. Le temps mis par un étage pour faire son travail est donc de :

Sur un pipeline, une instruction doit passer par étages pour s’exécuter. Son temps d’exécution total est le produit de la latence d'un étage par leur nombre :
- .

En simplifiant, on trouve :

Dit autrement, le temps d’exécution d'une instruction ne change pas : l'augmentation de la fréquence compense l'augmentation du nombre d'étages. Par contre, le fait que plusieurs instructions puisse s’exécuter en même temps augmente les performances : si la latence reste la même, le débit du processeur augmente.
Maintenant, regardons plus en détail ce qui arrive à la fréquence. Sur un processeur sans pipeline, on suppose que l'instruction met un cycle d'horloge à l’exécuter (pour simplifier). La fréquence du processeur est donc l'inverse du temps d’exécution de l'instruction, soit :

Sur un processeur avec pipeline, le temps de latence d'un étage est égal, par définition, à la durée d'un cycle d'horloge. La fréquence est l'inverse de cette durée, ce qui fait qu'elle vaut :

On voit que la fréquence a été multipliée par le nombre d'étages avec un pipeline ! On a bien étages au lieu d'un seul, mais chaque étage va fois plus vite, ce qui compense. Encore une fois, l'augmentation en performance provient de l'augmentation de l'IPC.
L'influence des registres inter-étages
En théorie, le raisonnement précédent nous dit que le temps d’exécution d'une instruction est le même sans ou avec un pipeline. Cependant, il faut prendre en compte les registres intercalés entre étages du pipeline, qui ajoutent un petit peu de latence. On a donc, en posant :
- la latence avec pipeline ;
- la latence sans pipeline ;
- la latence d'un registre inter-étage ;
- le nombre d'étages du pipeline.


Dans ces conditions, la latence d'un étage du pipeline vaut simplement :

La fréquence du processeur est l'inverse de cette latence. Elle est donc égale à :

Le débit, à savoir le nombre d'instructions exécutées par secondes, s'exprime à partir de cette équation assez simplement. Pour un processeur sans pipeline, ce débit est simplement égal à . Le pipeline peut exécuter instructions en même temps, ce qui multiplie le débit par , ce qui donne :


Cette équation nous donne le débit maximal théorique que peut atteindre un pipeline. Il suffit pour cela de faire tendre le nombre d'étages vers l'infini, ce qui donne un débit maximal de . Le débit est donc limité par le temps de latence des registres. Évidemment, cette limite est une limite théorique : la latence d'un étage ne peut pas être nulle !

L'hétérogénéité des latences entre étages
Su les processeurs réels, les raisonnements précédents sont cependant invalides, vu que certains étages possèdent un chemin critique plus long que d'autres. On est alors obligé de se caler sur l'étage le plus lent, ce qui réduit quelque peu le gain. La durée d'un cycle d'horloge doit être supérieure au temps de propagation de l'étage le plus lent. Mais dans tous les cas, l'usage d'un pipeline permet au mieux de multiplier la fréquence par le nombre d'étages. Cela a poussé certains fabricants de processeurs à créer des processeurs ayant un nombre d'étages assez élevé pour les faire fonctionner à très haute fréquence. Par exemple, c'est ce qu'a fait Intel avec le Pentium 4, dont le pipeline faisait 20 étages pour les Pentium 4 basés sur l'architecture Willamette et Northwood, et 31 étages pour ceux basés sur l'architecture Prescott et Cedar Mill.
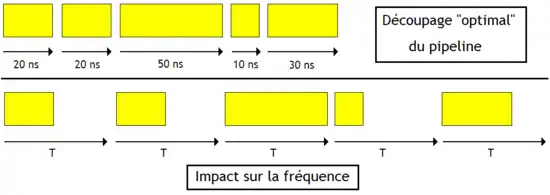
Les pipelines de longueur fixe
Découper un processeur en pipeline peut se faire de différentes manières, le nombre et la fonction des étages variant fortement d'un processeur à l'autre. Dans ce qui va suivre, nous allons utiliser une organisation relativement générale, où chaque instruction passe par les étapes suivantes :
- PC : mise à jour du program counter ;
- chargement : chargement de l'instruction depuis la mémoire ;
- décodage : décodage de l'instruction ;
- chargement d’opérandes : si besoin, les opérandes sont lus depuis la mémoire ou les registres ;
- exécution: exécution de l'instruction ;
- accès mémoire : accès à la mémoire RAM ;
- enregistrement : si besoin, le résultat de l’instruction est enregistré en mémoire.
L'étage de PC gère le program counter. L'étage de chargement utilise l'interface de communication avec la mémoire. L'étage de décodage contient l'unité de décodage d'instruction. L'étage de lecture de registre contient le banc de registres. L'étage d'exécution contient l'ALU, l'étage d’accès mémoire a besoin de l'interface avec la mémoire et l'étage d’enregistrement a besoin des ports d'écriture du banc de registres. Naïvement, on peut être tenté de relier l'ensemble de cette façon.
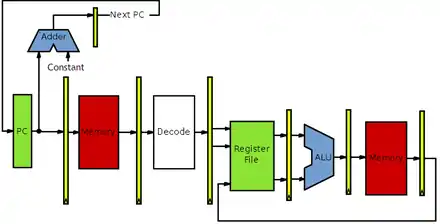
Le chemin de données
Toutes les instructions n'ont pas besoin d’accéder à la mémoire, tout comme certaines instructions n'ont pas à utiliser l'ALU ou lire des registres. Par exemple, certaines instructions n'ont pas besoin d’accéder à la RAM : on doit donc court-circuiter l'étage d’accès mémoire. De même, l'ALU aussi doit être court-circuitée pour les opérations qui ne font pas de calculs. En clair, certains étages sont « facultatifs » pour certaines instructions. L'instruction doit passer par ces étages, mais ceux-ci ne doivent rien faire, être rendus inactifs. Pour inactiver ces circuits, il suffit juste que ceux-ci puisse effectuer une instruction NOP, qui ne fait que recopier l'entrée sur la sortie. Pour les circuits qui ne s'inactivent pas facilement, on peut les court-circuiter en utilisant diverses techniques, la plus simple d'entre elle consistant à utiliser des multiplexeurs.
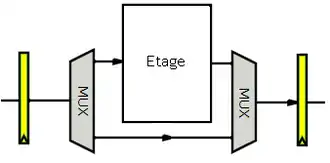
La lecture dans les registres peut être court-circuitée lors de l'utilisation de certains modes d'adressage. C'est notamment le cas lors de l'usage du mode d'adressage absolu. Pour le gérer, on envoye l'adresse, fournie par l'unité de décodage, sur l’entrée d'adresse de l'interface de communication avec la mémoire. Le principe est le même avec le mode d'adressage immédiat, sauf que l'on envoie une constante sur une entrée de l'ALU. On peut aller relativement loin comme cela.
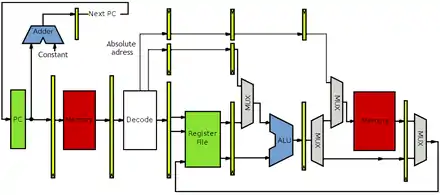
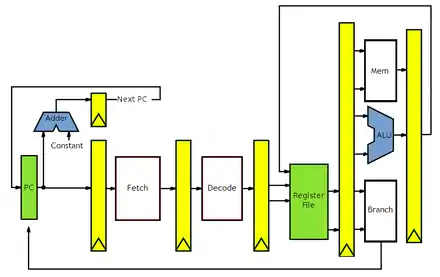
L'illustration ci-dessous montre ce que peut donner un pipeline MIPS à 5 étages qui gère les modes d'adressage les plus courants.
.svg.png.webp)
Les signaux de commande
Les signaux de commande qui servent à configurer le chemin de données sont générés par l'unité de décodage, dans la second étage du pipeline. Comment faire pour que ces signaux de commande traversent le pipeline ? Relier directement les sorties de l'unité de décodage aux circuits incriminés ne marcherait pas. Les signaux de commande arriveraient immédiatement aux circuits, alors que l'instruction n'a pas encore atteint ces étages ! La réponse consiste à faire passer ces signaux de commande d'un étage à l'autre en utilisant des registres.
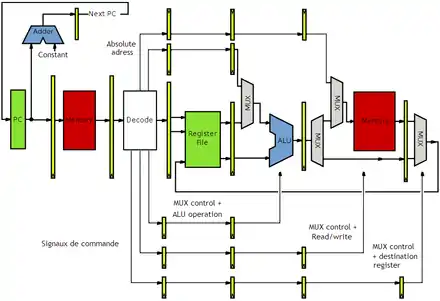
Les pipelines de longueur variable
Avec un pipeline de longueur fixe, toutes les instructions ont le même nombre d'étages, les étages inutiles étant court-circuités ou inactivés. Par exemple, si je prends une instruction qui effectue une addition entre deux registres, un des étages ne servira à rien : l'étage MEM. Normal, notre instruction n'accédera pas à la mémoire. Et on peut trouver beaucoup d'exemples de ce type. Par exemple, si je prends une instruction qui copie le contenu d'un registre dans un autre, ai-je besoin de l'étage d'Exec ou de MEM ? Non ! En clair : c'est un peu du gâchis. Si on regarde bien, on s’aperçoit que ce problème de nombre de micro-opérations variable vient du fait qu'il existe diverses classes d'instructions, qui ont chacune des besoins différents.
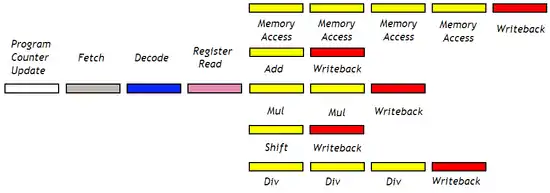
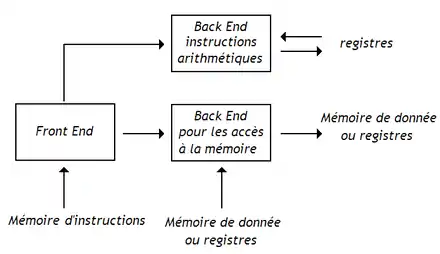
Sur un processeur non pipeliné, on peut éviter ces étapes inutiles en faisant varier le nombre de micro-opérations par instruction, certaines instructions pouvant prendre 7 cycles, d'autres 9, d'autres 25, etc. Il est possible de faire la même chose sur les processeurs pipelinés, dans une certaine limite, en utilisant plusieurs pipelines de longueurs différentes. Avec cette technique, le pipeline du processeur est décomposé en plusieurs parties. La première partie, l’amont (front end), prend en charge les étages communs à toutes les instructions : la mise à jour du program counter, le chargement, l'étage de décodage, etc. L'amont est suivi par le chemin de données, découpé en plusieurs unités adaptées à un certain type d'instructions, chacune formant ce qu'on appelle un aval (back end). Un aval est spécialisé dans une classe d'instructions : un pour les instructions arithmétiques et logiques, un autre pour les opérations d'accès mémoire, un autre pour les instructions d'échange de données entre registres, et ainsi de suite.
.png.webp)
La longueur de l’aval peut varier suivant le type d'instructions.
Les pipelines variables des processeurs load-store
Les processeurs load-store peuvent se contenter de deux avals : un pour les accès mémoire et un pour les calculs.
On peut aussi utiliser une unité de calcul séparée pour les instructions de tests et branchements.
Il est possible de scinder les avals précédents en avals plus petits. Par exemple, l'aval pour les instructions arithmétiques peuvent être scindés en plusieurs avals séparés pour l'addition, la multiplication, la division, etc. Niveau accès mémoire, certains processeurs utilisent un aval pour les lectures et un autre pour les écritures.
Mais la séparation des avals n'est pas optimale pour les instructions qui se pipelinent mal, auxquelles il est difficile de leur créer un aval dédié. C'est notamment le cas de la division, dont les unités de calcul ne sont jamais totalement pipelinées, voire pas du tout. Il n'est ainsi pas rare d'avoir à gérer des unités de calcul dont chaque étage peut prendre deux à trois cycles pour s’exécuter : il faut attendre un certain nombre de cycles avant d'envoyer une nouvelle instruction dans l’aval.
Les pipelines variables des processeurs non load-store
Les modes d'adressage complexes se marient mal avec un pipeline, notamment pour les modes d'adressages qui permettent plusieurs accès mémoire par instructions. La seule solution est de découper ces instructions machines en sous-instructions prises en charge par le pipeline. Ces instructions complexes sont transformées par le décodeur d’instructions en une suite de micro-instructions directement exécutables par le pipeline. Il va de soi que cette organisation complique pas mal le fonctionnement du séquenceur.