Ce chapitre va aborder le langage machine, à savoir un standard qui définit les instructions du processeur, le nombre de registres, etc. Dans ce chapitre, on considérera que le processeur est une boite noire au fonctionnement interne inconnu. Nous verrons le fonctionnement interne d'un processeur dans quelques chapitres. Les concepts que nous allons aborder ne sont rien d'autre que les bases nécessaires pour apprendre l'assembleur. Nous allons surtout parler des instructions du processeur. Pour simplifier, on peut classer les instructions en trois grands types :
- les échanges de données entre mémoires ;
- les calculs et autres opérations arithmétiques ;
- les instructions de comparaison ;
- les instructions de branchement.
À côté de ceux-ci, on peut trouver d'autres types d'instructions plus exotiques, pour gérer du texte, pour modifier la consommation en électricité de l'ordinateur, pour chiffrer ou de déchiffrer des données de taille fixe, générer des nombres aléatoires, etc.
Les instructions d'accès mémoire
Les instructions d’accès mémoire permettent de copier ou d'échanger des données entre le processeur et la RAM. On peut ainsi copier le contenu d'un registre en mémoire, charger une donnée de la RAM dans un registre, initialiser un registre à une valeur bien précise, etc. Il en existe plusieurs, les plus connues étant les suivantes : LOAD, STORE et MOV.
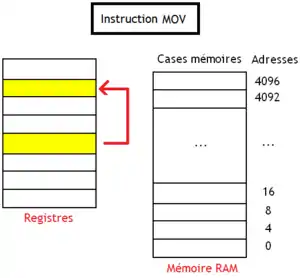
L'instruction MOV copie le contenu d'un registre dans un autre sans passer par la mémoire. C'est donc un échange de données entre registres, qui n'implique en rien la mémoire RAM, mais MOV est quand même considérée comme une instruction d'accès mémoire. Les données sont copiées d'un registre source vers un registre de destination. Le contenu du registre source est conservé, alors que le contenu du registre de destination est écrasé (il est remplacé par la valeur copiée). Cette instruction est utile pour gérer les registres, notamment sur les architectures avec peu de registres et/ou sur les architectures avec des registres spécialisés. Mais quelques rares architectures ne disposent pas d'instruction MOV, qui n'est formellement pas nécessaire, même si bien utile.
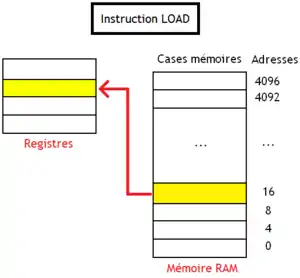
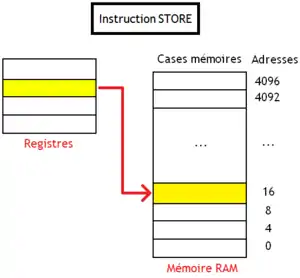
LOAD et STORE sont deux instructions qui permettent d'échanger des données entre la mémoire RAM et les registres. Elles copient le contenu d'un registre dans la mémoire, ou au contraire une portion de mémoire RAM dans un registre.
- LOAD est une instruction de lecture : elle copie le contenu d'un ou plusieurs mots mémoire consécutifs dans un registre. Le contenu du registre est remplacé par le contenu des mots mémoire de la mémoire RAM.
- STORE fait l'inverse : elle copie le contenu d'un registre dans un ou plusieurs mots mémoire consécutifs en mémoire RAM.
 |
 |
Les instructions de calcul
Tout ordinateur gère des instructions qui font des calculs arithmétiques simples. Ces instructions dépendent de la représentation utilisée pour coder ces nombres : on ne manipule pas de la même façon des nombres signés, des nombres codés en complément à 1, des flottants simple précision, des flottants double précision, etc. Pour gérer ces différents types de données, le processeur dispose souvent d'une instruction par type à manipuler : on peut avoir une instruction de multiplication pour les flottants, une autre pour les entiers codés en complément à deux, etc. Sur d'autres machines assez anciennes, on stockait le type de la donnée (est-ce un flottant, un entier codé en BCD, etc.) dans la mémoire. Chaque nombre manipulé par le processeur incorporait un tag, une petite suite de bits qui permettait de préciser son type. Le processeur ne possédait pas d'instructions en plusieurs exemplaires pour faire la même chose, et utilisait le tag pour déduire comment faire ses calculs. Par exemple, ces processeurs n'avaient qu'une seule instruction d'addition, qui pouvait traiter indifféremment flottants, nombres entiers codés en BCD, en complément à deux, etc. Le traitement effectué par cette instruction dépendait du tag incorporé dans la donnée. Des processeurs de ce type s'appellent des architectures à tags, ou tagged architectures.
Les tous premiers ordinateurs pouvaient manipuler des données de taille arbitraire. Alors certes, ces processeurs n'utilisaient pas vraiment les encodages de nombres qu'on a vus au premier chapitre. À la place, ils stockaient leurs nombres dans des chaines de caractères ou des tableaux encodés en BCD. De nos jours, les ordinateurs utilisent des entiers de taille fixe. La taille des données à manipuler peut dépendre de l'instruction. Ainsi, un processeur peut avoir des instructions pour traiter des nombres entiers de 8 bits, et d'autres instructions pour traiter des nombres entiers de 32 bits, par exemple. On peut aussi citer le cas des flottants : il faut bien faire la différence entre flottants simple précision et double précision !
Les instructions arithmétiques
Les instructions arithmétiques sont les plus courantes et comprennent au minimum l'addition, la soustraction, la multiplication, éventuellement la division, parfois les opérations plus complexes comme la racine carrée. La division est une opération très complexe et particulièrement lente, bien plus qu'une addition ou une multiplication. Pour information, sur les processeurs actuels, la division est 20 à 80 fois plus lente qu'une addition/soustraction, et presque 7 à 26 fois plus lente qu'une multiplication. Mais on a de la chance : c'est aussi une opération assez rare.
Un programme effectue rarement des divisions, les plus rares étant les divisions entières tandis que les plus fréquentes sont les divisons entre deux nombres flottants. Les plus couramment utilisées dans un programme sont des divisions par une constante : un programme devant manipuler des nombres décimaux aura tendance à effectuer des divisions par 10, un programme manipulant des durées pourra faire des divisions par 60 (gestion des minutes/secondes) ou 24 (gestion des heures). Diverses astuces permettent de remplacer les divisions par une constante par des suites d'instructions plus simples mais qui donnent le même résultat. J'ai parlé auparavant des décalages, qui permettent de remplacer de divisions par . Mais il existe d'autres méthodes, qui fonctionnent pour un grand nombre de constantes. Par exemple, on peut les remplacer par une multiplication un peu bizarre : la multiplication par un entier réciproque.

Sachant cela, certains processeurs ne possèdent pas d'instruction de division. Inclure une instruction de division n'accélérerait qu'un faible nombre d'instructions, et ne donnerait pas lieu à des gains assez importants en termes de performance : accélérer 1% des instructions d'un programme (ici, les divisions) en implémentant un circuit complexe et gourmand en transistors alors qu'on pourrait utiliser ces circuits pour câbler des instructions plus utiles serait du gâchis. Certains processeurs implémentent toutefois la division dans une instruction machine, disposant souvent d'un circuit dédié. Les gains ne sont pas forcément faramineux, mais ne sont pas forcément négligeables non plus.
Les instructions flottantes
Les processeurs peuvent aussi gérer les calculs sur des nombres flottants. IEEE 754 standardise aussi quelques instructions sur les flottants qui doivent impérativement être supportées : les quatre opérations arithmétiques de base, les comparaisons et la racine carrée. Certains processeurs vont même plus loin et implémentent non seulement les instructions de la norme, mais aussi d'autres instructions sur les flottants qui ne sont pas supportées par la norme IEEE 754. Par exemple, certaines fonctions mathématiques telles que sinus, cosinus, tangente, arctangente et d'autres, sont supportées par certaines FPU. Le seul problème, c'est que ces instructions peuvent mener à des erreurs de calcul incompatibles avec la norme IEEE 754. Heureusement, les compilateurs peuvent mitiger ces désagréments.
Le support matériel et logiciel des flottants
Le support de ces instructions est souvent matériel : le processeur possède souvent des circuits capables d'effectuer des comparaisons, additions, soustractions, multiplications, divisions et racines carrées. De nos jours, ces instructions sont directement câblées dans les circuits du processeur et ne sont plus émulées, sauf pour quelques-unes. Le choix du mode d'arrondi ou la gestion des exceptions sont implémentés directement dans le matériel et sont souvent configurables grâce à un registre du processeur : suivant la valeur mise dans celui-ci, le processeur arrondira les résultats des calculs d'une certaine façon et pas d'une autre, ou réagira d'une certaine manière aux exceptions vues au-dessus.
Autrefois, à savoir il y a une quarantaine d'années, nos processeurs n'étaient capables d'utiliser que des nombres entiers et aucune instruction machine ne pouvait manipuler de nombres flottants. On devait alors émuler les calculs flottants par une suite d'instructions machine effectuées sur des entiers. Cette émulation était effectuée par une bibliothèque logicielle, fournie par un programmeur, voire par le système d'exploitation. Quand le système d'exploitation fournissait de quoi émuler les flottants, les instructions flottantes étaient alors émulées par le biais d'exceptions matérielles (nous verrons ce concept dans quelques chapitres) : le processeur interrompt temporairement l'exécution du programme en cours et exécute un sous-programme capable de traiter l'exception. Dans tous les cas, les calculs sur des nombres flottants étaient alors vraiment lents et la manière de stocker des flottants en mémoire dépendait de l'application ou du système d'exploitation.
Pour améliorer les performances, les concepteurs de processeurs ont incorporé des instructions de calculs sur des nombres flottants dans les jeux d'instruction. Les premiers processeurs de ce type n'incorporaient néanmoins pas le moindre circuit capable d'effectuer des opérations flottantes. Sur ces processeurs, chaque instruction machine capable de gérer des nombres flottants était convertie en interne (c'est-à-dire dans le processeur) en une suite d'instructions entières qui émulaient l'instruction voulue. Nous verrons dans quelques chapitres comment cette conversion était faite - pour ceux qui savent, ces instructions étaient microcodées. Nous allons juste dire que le processeur incorporait une petite mémoire ROM. Celle-ci stockait, pour chaque instruction à émuler, une suite de calculs qui l'émulait. Lorsqu'une instruction à émuler doit être exécutée, notre processeur lisait la suite de calculs dans la mémoire ROM et l'exécutait.

Il faut signaler qu'il a existé des processeurs spécialisés dans les calculs flottants. A une époque, un ordinateur de type PC pouvait contenir un processeur normal, secondé par un processeur annexe dédié aux flottants. Un emplacement dans la carte mère était réservé à un de ces processeurs spécialisés. On appelait ces processeurs spécialisés dans les calculs flottants des coprocesseurs arithmétiques. Ces coprocesseurs étaient très chers et relativement peu utilisés. Seules certaines applications assez rares étaient capables d'en tirer profit : des logiciels de conception assistée par ordinateur, par exemple.
Le support des formats de flottants
Il faut néanmoins préciser que le support de la norme IEEE 754 par la FPU/le jeu d'instruction n'est pas une obligation : certains processeurs s'en moquent royalement. Dans certaines applications, les programmeurs ont souvent besoin d'avoir des calculs qui s'effectuent rapidement et se contentent très bien d'un résultat approché. Dans ces situations, on peut utiliser des formats de flottants différents de la norme IEEE 754 et les circuits de la FPU sont simplifiés pour être plus rapides. Par exemple, certains circuits ne gèrent pas les underflow, overflow, les NaN ou les infinis, voir utilisent des formats de flottants exotiques. Sur d'autres processeurs, le processeur peut être configuré de façon à soit ignorer ces exceptions en fournissant un résultat, soit déclencher une exception matérielle (à ne pas confondre avec les exceptions de la norme). Il suffit pour cela de modifier la valeur d'un registre de configuration intégré dans le processeur. Le choix du mode d'arrondi ou la gestion des exceptions flottantes sont implémentés directement dans le matériel et sont souvent configurables grâce à un registre du processeur : suivant la valeur mise dans celui-ci, le processeur arrondira les résultats des calculs d'une certaine façon et pas d'une autre, ou réagira d'une certaine manière aux exceptions vues au-dessus.
Sur certains processeurs, tous les formats de flottants IEEE754 ne sont pas supportés. Il arrive que certains ne supportent que les flottants simple précision, mais pas les double précision ou d'autres formats assez courants. Si un processeur ne supporte pas un format de flottant, il doit émuler son support, généralement par logiciel. Exemple : les premiers processeurs Intel ne géraient que les flottants double précision étendue. Un autre exemple est la gestion des flottants dénormalisés, qui n'est pas forcément supportée par les processeurs. Sur quelques architectures, les dénormaux sont émulés en logiciel. Mais même lorsque la gestion des dénormaux est implémentée en hardware (comme c'est le cas sur certains processeurs AMD), celle-ci reste malgré tout très lente.
Plus rarement, il arrive que certains processeurs gèrent des formats de flottants spéciaux qui ne font pas partie de la norme IEEE 754.
Les instructions logiques
À côté des instructions de calcul, on trouve des instructions logiques qui travaillent sur des bits ou des groupes de bits. Les opérations bit à bit ont déjà été vues dans les premiers chapitres, ceux sur l'électronique. Pour rappel, les plus courantes sont :
- La négation, ou encore le NON bit à bit, inverse tous les bits d'un nombre : les 1 deviennent des 0 et les 0 deviennent des 1.
- Le ET bit à bit, qui agit sur deux nombres : il va prendre les bits qui sont à la même place et va effectuer un ET (l’opération effectuée par la porte logique ET). Exemple : 1100·1010=1000.
- Les instructions similaires avec le OU ou le XOR.
Les instructions de décalage décalent tous les bits d'un nombre vers la gauche ou la droite. Pour rappel, il existe plusieurs types de décalages : les rotations, les décalages logiques, et les décalages arithmétiques. Nous avions déjà vu ces trois opérations dans le chapitre sur les circuits de décalage et de rotation, ce qui fait que nous allons simplement faire un rappel dans le tableau suivant. Pour résumer, voici la différence entre les trois opérations :
| Schéma | Gestion des bits sortants | Remplissage des vides laissés par le décalage | |
|---|---|---|---|
| Rotation | 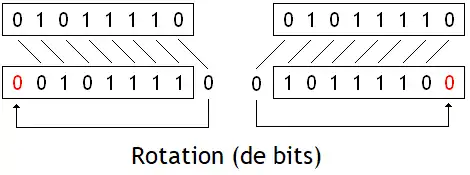 |
Réinjectés dans les vides laissés par le décalage | Remplis par les bits sortants |
| Décalage logique | 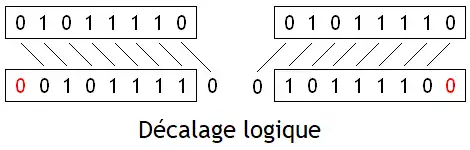 |
Les bits sortants sont oubliés | Remplis par des zéros |
| Décalage arithmétique | 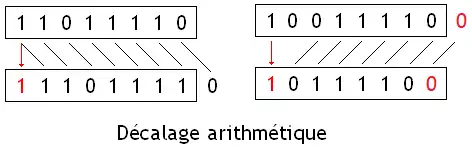 |
Remplis par :
|
Pour rappel, les décalages de n rangs sont équivalents à une multiplication/division par 2^n. Un décalage à gauche est une multiplication par 2^n, alors qu'un décalage à droite est une division par 2^n. Les décalages logiques effectuent la multiplication/division pour un nombre non-signé (positif), alors que les décalages arithmétiques sont utilisés pour les nombres signés. Précisons cependant que pour ce qui est des décalages à droite, les décalages logiques et arithmétiques n'arrondissent pas le résultat de la même manière. Les décalages logiques à droite arrondissent vers zéro, alors que les décalages arithmétiques arrondissent vers la valeur inférieure (vers moins l'infini). De plus, les décalages à gauche entraînent des débordements d'entiers qui ne se gèrent pas de la même manière entre décalage logique et décalage arithmétique.
Les instructions de test
Les instructions de test comparent deux valeurs (des adresses, ou des nombres entiers ou à virgule flottante). Sur la majorité des processeurs, ces instructions ne font qu'une comparaison à la fois. D'autres processeurs ont des instructions de test qui effectuent plusieurs comparaisons en même temps et fournissent plusieurs résultats. Par exemple, un processeur x86 possède une instruction CMP qui vérifie simultanément si deux valeurs A et B sont égales, différentes, si A est inférieur à B, si A est supérieur à B, etc. Les comparaison permettent souvent d'effectuer les comparaisons suivantes :
- A > B (est-ce que A est supérieur à B ?) ;
- A < B (est-ce que A est inférieur à B ?) ;
- A == B (est-ce que A est égal à B ?) ;
- A != B (est-ce que A est différent de B ?).
Il arrive que certaines de ces instructions de test effectuent plusieurs comparaisons en même temps et fournissent plusieurs résultats. Par exemple, un processeur peut très bien posséder une instruction cmp capable de vérifier si deux valeurs A et B sont égales, différentes, si A est inférieure à B, et si A est supérieur à B, en même temps.
Le stockage du résultat d'une comparaison
Le résultat d'une comparaison est un bit, qui dit si la condition testée est vraie ou fausse. Dans la majorité des cas, ce bit vaut 1 si la comparaison est vérifiée, et 0 sinon. Une fois que l'instruction a fait son travail, il reste à stocker son résultat quelque part. Et pour ce faire, il existe plusieurs techniques :
- soit on utilise des registres d'état ;
- soit on utilise des registres à prédicats ;
- soit on ne mémorise pas le résultat.
Certains processeurs incorporent un registre d'état, qui stocke des bits qui ont chacun une signification prédéterminée lors de la conception du processeur. Le ou les bits du registre d'état modifiés par une instruction de test dépendent de l'instruction utilisée : par exemple, on peut utiliser un bit qui indiquera si l'entier testé est égal à un autre, un autre bit qui indiquera si le premier entier testé est supérieur à l'autre, etc. Ce registre peut aussi contenir d'autres bits suivant le processeur, comme le bit de débordement qui prévient quand le résultat d'une instruction est trop grand pour tenir dans un registre, le bit null qui précise que le résultat d'une instruction est nul (vaut zéro), le bit de retenue qui est utile pour les additions, le bit de signe qui permet de dire si le résultat d'une instruction est un nombre négatif ou positif. Le registre d'état a un avantage : certaines instructions arithmétiques peuvent modifier les bits du registre d'état, ce qui leur permet parfois de remplacer une instruction de test. Par exemple, prenons le cas d'un processeur où la soustraction modifie le bit null du registre d'état : on peut tester si deux nombres sont égaux en soustrayant leur contenu, le bit null étant mis à zéro si c'est le cas.
D'autres processeurs utilisent des registres à prédicats, des registres de 1 bit qui peuvent stocker n'importe quel résultat de comparaison. Une comparaison peut enregistrer son résultat dans n'importe quel registre à prédicats : elle a juste à préciser lequel avec son nom de registre. Cette méthode est plus souple que l'utilisation d'un registre d'état dont les bits ont une utilité fixée une fois pour toutes. Les registres à prédicats sont utiles pour accumuler les résultats de plusieurs comparaisons et les utiliser par la suite. Par exemple, une instruction de branchement pourra vérifier la valeur de plusieurs de ces registres pour prendre une décision. Chose impossible avec les autres approches, dont les branchements ne peuvent utiliser qu'un seul résultat de comparaison pour prendre leur décision.
Enfin, sur d'autres processeurs, il n'y a pas de registres pour stocker les résultats de comparaisons : les comparaisons sont fusionnées avec les branchements en une seule instruction, rendant le stockage du résultat inutile.
Les instructions de branchements
Un processeur serait sacrément inflexible s'il ne faisait qu'exécuter des instructions dans l'ordre. Certains processeurs ne savent pas faire autre chose, comme le Harvard Mark I, et il est difficile, voire impossible, de coder certains programmes sur de tels ordinateurs. Mais rassurez-vous : il existe de quoi permettre au processeur de faire des choses plus évoluées. Pour rendre notre ordinateur "plus intelligent", on peut par exemple souhaiter que celui-ci n'exécute une suite d'instructions que si une certaine condition est remplie. Ou faire mieux : on peut demander à notre ordinateur de répéter une suite d'instructions tant qu'une condition bien définie est respectée. Diverses structures de contrôle de ce type ont donc étés inventées.
Voici les plus utilisées et les plus courantes : ce sont celles qui reviennent de façon récurrente dans un grand nombre de langages de programmation actuels. Concevoir un programme (dans certains langages de programmation), c'est simplement créer une suite d'instructions, et utiliser ces fameuses structures de contrôle pour l'organiser. D'ailleurs, ceux qui savent déjà programmer auront reconnu ces fameuses structures de contrôle. On peut bien sur en inventer d’autres, en spécialisant certaines structures de contrôle à des cas un peu plus particuliers ou en combinant plusieurs de ces structures de contrôles de base, mais cela dépasse le cadre de ce tutoriel : ce tutoriel ne va pas vous apprendre à programmer.
| Nom de la structure de contrôle | Description |
|---|---|
| SI...ALORS | Exécute une suite d'instructions si une condition est respectée |
| SI...ALORS...SINON | Exécute une suite d'instructions si une condition est respectée ou exécute une autre suite d'instructions si elle ne l'est pas. |
| Boucle WHILE...DO | Répète une suite d'instructions tant qu'une condition est respectée. |
| Boucle DO...WHILE aussi appelée REPEAT UNTIL | Répète une suite d'instructions tant qu'une condition est respectée. La différence, c'est que la boucle DO...WHILE exécute au moins une fois cette suite d'instructions. |
| Boucle FOR | Répète un nombre fixé de fois une suite d'instructions. |
Pour implémenter ces structures de contrôle, les instructions de test sont combinées avec des instructions de branchement. Ces dernières modifient la valeur stockée dans le registre d'adresse d'instruction, ce qui permet de sauter directement à une instruction et de poursuivre l'exécution à partir de celle-ci. Il existe deux types de branchements :
- les branchements inconditionnels, avec lesquels le processeur passe toujours à l'instruction vers laquelle le branchement va renvoyer ;
- les branchements conditionnels, où le branchement n'est exécuté que si certains bits du registre d'état sont à une certaine valeur.
Sur la plupart des processeurs, les branchements conditionnels sont précédés d'une instruction de test ou de comparaison. Mais d'autres effectuent le test et le branchement en une seule instruction machine, pour se passer de registre d'état ou de registres à prédicats. Sur d'autres processeurs, les instructions de test permettent de zapper l'instruction suivante si la condition testée est fausse : cela permet de simuler un branchement conditionnel à partir d'un branchement inconditionnel. Sur quelques rares processeurs, le program counter est un registre général qui peut être modifié par n'importe quelle opération arithmétique : cela permet de remplacer les branchements par une simple écriture dans le program counter.
Les structures de contrôle conditionnelles
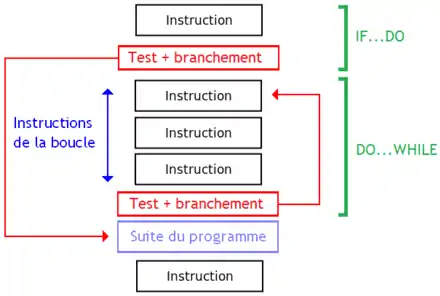
Le IF permet d’exécuter une suite d'instructions si et seulement si une certaine condition est remplie.
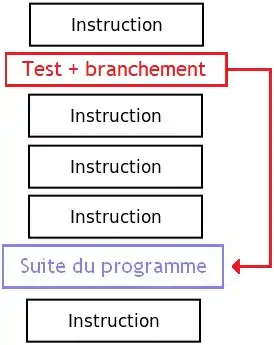
Le IF...ELSE sert à effectuer une suite d'instructions différente selon que la condition est respectée ou non : c'est un SI…ALORS contenant un second cas. Une boucle consiste à répéter une suite d'instructions machine tant qu'une condition est valide (ou fausse).
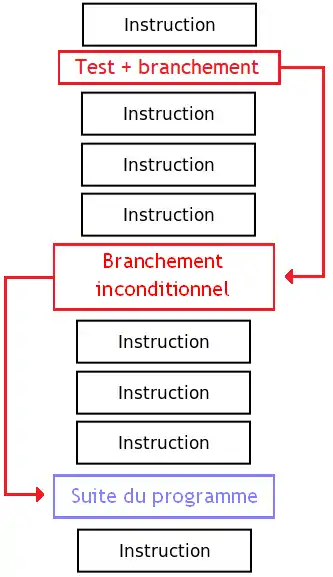
Les structures de contrôle itératives
Les boucles sont une variante du IF dont le branchement renvoie le processeur sur une instruction précédente.
Commençons par la boucle DO…WHILE : la suite d'instructions est exécutée au moins une fois, et est répétée tant qu'une certaine condition est vérifiée. Pour cela, la suite d'instructions à exécuter est placée avant les instructions de test et de branchement, le branchement permettant de répéter la suite d'instructions si la condition est remplie. Si jamais la condition testée est fausse, on passe tout simplement à la suite du programme.
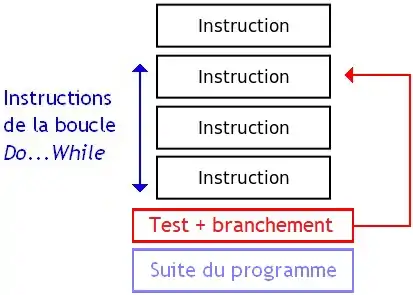
Une boucle WHILE…DO est identique à une boucle DO…WHILE à un détail près : la suite d'instructions de la boucle n'a pas forcément besoin d'être exécutée au moins une fois. On peut donc adapter une boucle DO…WHILE pour en faire une boucle WHILE…DO : il suffit de tester si la boucle doit être exécutée au moins une fois avec un IF, et exécuter une boucle DO…WHILE équivalente si c'est le cas.
Les instructions d'appel et de retour de fonction
Les branchements inconditionnels sont aussi utilisés pour fabriquer des fonctions. Pour comprendre ce que sont ces fonctions, il faut faire quelques rappels.
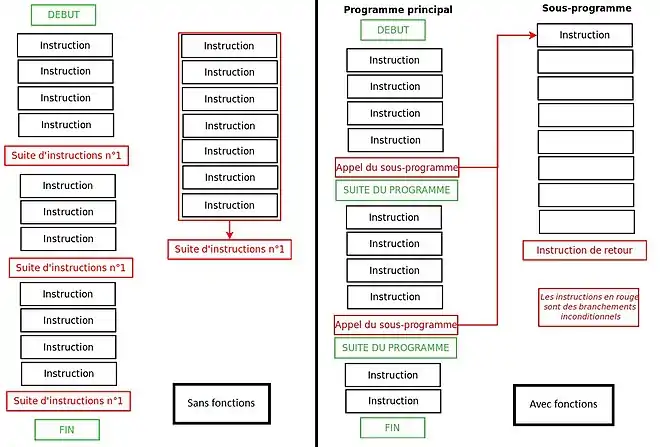
Un programme contient souvent des suites d'instructions présentes en plusieurs exemplaires, qui servent souvent à effectuer une tâche bien précise : calculer un résultat bien précis, communiquer avec un périphérique, écrire un fichier sur le disque dur, ou autre chose encore. Sans utiliser de sous-programmes, ces suites d'instructions sont présentes en plusieurs exemplaires dans le programme. Le programmeur doit donc recopier à chaque fois ces suites d'instructions, ce qui ne lui facilite pas la tache (sauf en utilisant l’ancêtre des sous-programmes : les macros). Et dans certains programmes, devoir recopier plusieurs fois la séquence d'instruction qui permet d'agir sur un périphérique ou de faire une action spéciale est franchement barbant ! De plus, ces suites d'instructions sont présentes plusieurs fois dans le programme final, exécuté par l'ordinateur. Et elles prennent de la place inutilement ! Dans les langages de programmation modernes, il est possible de ne conserver qu'un seul exemplaire en mémoire et l'utiliser au besoin. L'exemplaire en question est ce qu'on appelle une fonction, ou encore un sous-programme. C'est au programmeur de « sélectionner » ces suites d'instructions et d'en faire des fonctions.
Pour exécuter une fonction, il suffit d'exécuter un branchement dont l'adresse de destination est celle de la fonction : on dit qu'on appelle la fonction. Toute fonction se termine par une instruction de retour, qui permet au processeur de revenir là où il en était avant d'appeler la fonction. Certains processeurs disposent d'une instruction de retour dédiée, alors que d'autres l'émulent à partir d'autres instructions. L'instruction de retour a besoin de connaître l'adresse de retour, l'adresse de la suite du programme. Celle-ci est sauvegardée soit par l'instruction d'appel de la fonction, soit par une instruction d'écriture spécialisée.
La sauvegarde de l'adresse de retour
Vu qu'une fonction apparaît plusieurs fois dans notre programme, comment savoir à quelle instruction reprendre l'exécution de notre programme, une fois notre sous-programme terminé ? La seule solution est de sauvegarder l'adresse de l'instruction à laquelle il faut reprendre ! Le programme doit donc reprendre à l'instruction qui est juste après le branchement d'appel de fonction. Pour cela, on doit sauvegarder cette adresse appelée l'adresse de retour.
Cette sauvegarde peut être faite de deux manières. Il arrive que le processeur possède une instruction spéciale, capable de sauvegarder l'adresse de retour et de brancher vers le sous-programme voulu en une seule instruction. Cette instruction spéciale, capable de sauvegarder automatiquement l'adresse de retour et de brancher vers le sous-programme, est appelée une instruction d'appel de fonction. Dans les autres cas, on doit émuler cette instruction avec une instruction qui sauvegarde l'adresse de retour, suivie d'un branchement inconditionnel vers le sous-programme.
Une fois le sous-programme fini, il suffit de charger l'adresse de retour dans le registre pointeur d'instruction pour reprendre l’exécution de notre programme principal là où il s'était arrêté pour laisser la place au sous-programme. Là encore, deux solutions sont possibles pour faire cela. Sur certains processeurs, cela est fait par l'instruction située à la fin du sous-programme, qu'on nomme instruction de retour. C'est un branchement inconditionnel. Cette instruction a pour mode d'adressage, l'adressage implicite (l'adresse vers laquelle brancher est placée au sommet de la pile, pas besoin de la préciser). Sur d'autres, cette instruction spéciale n'existe pas et il faut encore une fois l'émuler avec les moyens du bord. L'astuce consiste souvent à charger l'adresse de retour dans un registre et utiliser un branchement inconditionnel vers cette adresse.
La sauvegarde des registres
Lorsqu'un sous-programme s'exécute, il va utiliser certains registres qui sont souvent déjà utilisés par le programme principal. Pour éviter d'écraser le contenu des registres, on doit donc conserver une copie de ceux-ci dans la pile, une sauvegarde de ceux-ci. Une fois que le sous-programme a fini de s'exécuter, il remet les registres dans leur état original en chargeant la sauvegarde dans les registres adéquats. Ce qui fait que lorsqu'un sous-programme a fini son exécution, tous les registres du processeur reviennent à leur ancienne valeur : celle qu'ils avaient avant que le sous-programme ne s'exécute. Rien n'est effacé ! Cette sauvegarde peut être effectuées automatiquement par l'instruction d'appel de fonction, ou être émulée en logiciel. Plus rarement, certains processeurs ont une instruction pour sauvegarder les registres du processeur.
La pile d'appel
Pour pouvoir exécuter plusieurs fonctions, le processeur contient une ou plusieurs piles d'appel. Sans cela, certaines fonctionnalités de nos langages de programmation actuels n'existeraient pas ! Pour les connaisseurs, cela signifierait qu'on ne pourrait pas utiliser de fonctions réentrantes ou de fonctions récursives. Mais je n'en dis pas plus : vous verrez ce que cela veut dire d'ici quelques chapitres.
Généralités sur la pile d'appel
Cette pile d'appel est une partie de la mémoire RAM, ou une mémoire séparée, qui a une particularité : on stocke les données à l'intérieur d'une certaine façon. Les données sont regroupées dans la pile dans ce qu'on appelle des cadres de pile, des espèces de blocs de mémoire de taille variable.
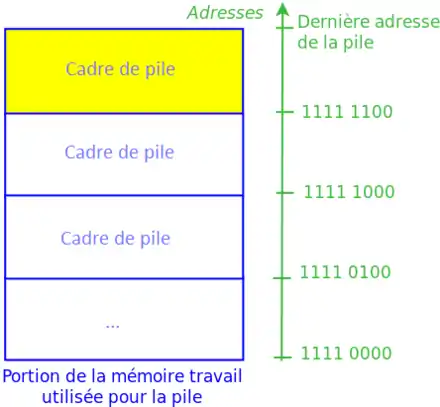
Les cadres sont créés un par uns et sont placés les uns à la suite des autres dans la mémoire. C'est une première contrainte : on ne peut pas créer de cadres n'importe où dans la mémoire. On peut comparer l'organisation des cadres à une pile d'assiette : on peut parfaitement rajouter une assiette au sommet de la pile d'assiette, ou enlever celle qui est au sommet, mais on ne peut pas toucher aux autres assiettes. Sur la pile de notre ordinateur, c'est la même chose : on ne peut accéder qu'à la donnée située au sommet de la pile. Comme pour une pile d'assiette, on peut rajouter ou enlever le cadre au sommet de la pile, mais pas toucher aux cadres en dessous, ni les manipuler.
Le nombre de manipulations possibles sur cette pile se résume donc à trois manipulations de base qu'on peut combiner pour créer des manipulations plus complexes. On peut ainsi :
- détruire le cadre de pile au sommet de la pile, et supprimer tout son contenu de la mémoire : on dépile.
- créer un cadre de pile immédiatement après le dernier cadre de pile existante : on empile.
- utiliser les données stockées dans le cadre de pile au sommet de la pile.
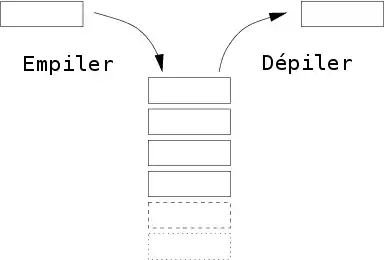
Si vous regardez bien, vous remarquerez que la donnée au sommet de la pile est la dernière donnée à avoir été ajoutée (empilée) sur la pile. Ce sera aussi la prochaine donnée à être dépilée (si on n'empile pas de données au-dessus). Ainsi, on sait que dans cette pile, les données sont dépilées dans l'ordre inverse d'empilement. Ainsi, la donnée au sommet de la pile est celle qui a été ajoutée le plus récemment.
_LIFO.svg.png.webp)
Au fait, la pile peut contenir un nombre maximal de cadres, ce qui peut poser certains problèmes. Si l'on souhaite utiliser plus de cadres de pile que possible, il se produit un débordement de pile. En clair, l'ordinateur plante !
La délimitation des cadres de pile
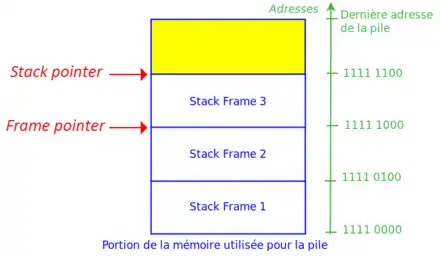
Pour gérer ces piles, on a besoin de sauvegarder deux choses : l'adresse à laquelle commence le cadre de pile en mémoire, et de quoi connaître l'adresse de fin. Le registre qui indique où est le sommet de la pile, quelle est son adresse, est appelé le pointeur de sommet, ou encore le Stack Pointer (SP). A ce registre, on peut rajouter un registre qui sert à donner l'adresse de début du cadre de pile : le Frame Pointer (FP), ou pointeur de contexte.
Pour localiser une donnée dans un cadre de pile, on utilise sa position par rapport au début ou la fin du cadre de pile. On peut donc calculer l'adresse de la donnée en additionnant cette position avec le contenu du pointeur de pile.
Certains processeurs possèdent deux registres spécialisés qui servent respectivement de pointeur de contexte et de pointeur de pile : on ne peut pas les utiliser pour autre chose. Si ce n'est pas le cas, on est obligé de stocker ces informations dans deux registres normaux, et se débrouiller avec les registres restants.
D'autres processeurs arrivent à se passer de Frame Pointer. Ceux-ci n'utilisent pas de registres pour stocker l'adresse de la base du cadre, mais préfèrent calculer cette adresse à partir de l'adresse de fin du cadre et de sa longueur. Cette longueur peut être stockée directement dans certaines instructions censées manipuler la pile : si chaque cadre a toujours la même taille, cette solution est clairement la meilleure. Cette solution est idéale si le cadre de pile a toujours la même taille. Mais il arrive que les cadres aient une taille qui ne soit pas constante : dans ce cas, on a deux solutions : soit stocker cette taille dans un registre, soit la stocker dans les instructions qui manipulent la pile, soit utiliser du code automodifiant.
Piles d'appel séparées contre pile d'appel unifiée
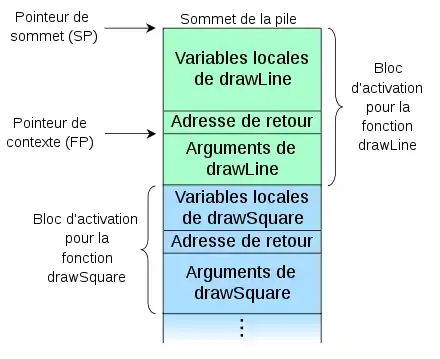
Pour exécuter plusieurs fonctions imbriquées les unes dans les autres, on doit sauvegarder plusieurs adresses de retour dans l'ordre. Pour cela, on utilise une pile d'adresses de retour. L'adresse de retour de la fonction en cours est toujours située au sommet de la pile. Certains processeurs émulent cette pile avec des registres généraux, ou sauvegardent une partie de la pile dans des registres cachés au lieu de tout mémoriser en RAM. La sauvegarde des registres peut aussi utiliser la pile d'appel, si ce n'est avoir une pile de sauvegarde des registres dédiée. Enfin, le processeur dispose souvent d'une autre pile, souvent fusionnée avec les deux précédentes, qui contient des données utiles pour chaque fonction.
Par exemple, certaines valeurs calculées hors de la fonction lui sont communiquées : ce sont des arguments ou paramètres. On peut communiquer ces valeurs de deux manières, soit en en fournissant une copie, soit en fournissant leur adresse. Dans les deux cas, cette transmission peut se faire par copie soit sur la pile, soit dans les registres. Dans le cas d'un passage par les registres, les registres qui contiennent les paramètres ne sont pas sauvegardés lors de l'appel de la fonction. Généralement, le passage par la pile est très utilisé sur les processeurs avec peu de registres, alors que les processeurs avec beaucoup de registres privilégient le passage par les registres.
De même, la fonction peut calculer un ou plusieurs résultats, qui sont récupérés par le programme principal et seront utilisés dans divers calculs. Ces résultats sont appelés des valeurs de retour. Généralement, c'est le programmeur qui décide de conserver une donnée et d'en faire une valeur de retour. Celui-ci peut avoir besoin de conserver le résultat d'un calcul pour pouvoir l'utiliser plus tard, par exemple. Ce résultat dépend fortement du sous-programme, et peut être n'importe quelle donnée : nombre entier, nombre flottant, tableau, objet, ou pire encore. Cette donnée, après avoir été "calculée" par le sous-programme, devra être conservée quelque part. Il va de soi que l'on ne peut pas stocker cette valeur de retour dans un registre : elle serait écrasée lors de la restauration des registres. Sans compter que cette valeur ne tient pas toujours dans un registre : un registre contenant 64 bits pourra difficilement contenir une valeur de retour de 5 kilo-octets. Pour éviter cela, on peut dédier certains registres à notre valeur de retour, et on se débrouille pour que la restauration des registres ne touche par ceux-ci. Mais un autre solution consiste à stocker ces valeurs de retour dans une pile dédiée : la pile des valeurs de retour. Ainsi, la valeur de retour est présente au sommet de la pile et peut être utilisée si besoin.
De plus, une fonction peut calculer des données temporaires, souvent appelées des variables locales. Une solution pour gérer ces variables consiste à réserver une portion de la mémoire statique pour chaque, dédiée au stockage de ces variables locales, mais cela gère mal le cas où une fonction s'appelle elle-même (fonctions récursives). Une autre solution est de réserver un cadre de pile pour les variables locales. Le processeur dispose de modes d'adressages spécialisés pour adresser les variables automatiques d'un cadre de pile. Ces derniers ajoutent une constante au stack pointer.
Pour gérer les fonctions, certains processeurs possèdent deux ou plusieurs piles spécialisées pour les adresses de retour, les registres à sauvegarder, les paramètres et les variables locales. Mais d'autres processeurs ne possèdent qu'une seule pile à la fois pour les adresses de retour, les variables locales, les paramètres, et le reste. Pour cela, il faut utiliser une pile avec des cadres de pile de taille variable, dans lesquels on peut ranger plusieurs données. Les variables locales sont souvent regroupées, de même que les arguments, le reste étant placé à une position bien précise dans le cadre de pile.
Résumé
| Instruction | Utilité |
|---|---|
| Instructions arithmétiques | Ces instructions font simplement des calculs sur des nombres. On peut citer par exemple :
|
| Instructions logiques | Elles travaillent sur des bits ou des groupes de bits. On peut citer :
|
| Instructions de test | Elles peuvent comparer deux nombres entre eux pour savoir si une condition est remplie ou pas.
Pour citer quelques exemples, il existe certaines instructions qui peuvent vérifier si :
|
| Instructions de contrôle (branchements) | Elles permettent de contrôler la façon dont notre programme s’exécute sur notre ordinateur. Elles permettent notamment de choisir la prochaine instruction à exécuter, histoire de répéter des suites d'instructions, de ne pas exécuter des blocs d'instructions dans certains cas, et bien d'autres choses. |
| Instructions d’accès mémoire | Elles permettent d'échanger des données entre le processeur et la mémoire, ou encore permettent de gérer la mémoire et son adressage. |
| Instructions de manipulation de chaînes de caractères | Certains processeurs intègrent des instructions capables de manipuler ces chaînes de caractères directement. Mais autant être franc : ceux-ci sont très rares. Dans notre ordinateur, une lettre est stockée sous la forme d'un nombre souvent codé sur 1 octet (rappelez-vous le premier chapitre sur la table ASCII). Pour stocker du texte, on utilise souvent ce que l'on appelle des chaînes de caractères : ce ne sont rien de plus que des suites de lettres stockées les unes à la suite des autres dans la mémoire, dans l'ordre dans lesquelles elles sont placées dans le texte. |
| Les inclassables | Il existe une grande quantité d'autres instructions, qui sont fournies par certains processeurs pour des besoins spécifiques.
|