Dans ce qui précède, nous avons abordé divers paramètres, qui sont souvent indiqués lorsque vous achetez un processeur, de la mémoire, ou tout autre composant électronique :
- la finesse de gravure ;
- le nombre de transistors ;
- la fréquence ;
- et la tension d'alimentation.
Ces paramètres ont une influence indirecte sur les performances d'un ordinateur, ou sur sa consommation énergétique. Dans ce qui va suivre, nous allons voir comment déduire la performance d'un processeur ou d'une mémoire suivant ces paramètres. Nous allons aussi étudier quel est l'impact de la finesse de gravure sur la consommation d'énergie d'un composant électronique. Cela nous amènera à étudier les tendances de l'industrie.
Pour commencer, il faut d'abord définir ce qu'est la performance d'un ordinateur. C'est loin d'être une chose triviale : de nombreux paramètres font qu'un ordinateur sera plus rapide qu'un autre. De plus, la performance ne signifie pas la même chose selon le composant dont on parle. La performance d'un processeur n'est ainsi pas comparable à la performance d'une mémoire ou d'un périphérique. La finesse de gravure n'a pas d'impact en elle-même sur la performance ou la consommation d'énergie : elle permet juste d'augmenter le nombre de transistors et la fréquence, tout en diminuant la tension d'alimentation. Et ce sont ces trois paramètres qui vont nous intéresser.
La performance des entrées-sorties
Pour une entrée-sortie, la mesure de la performance dépend énormément du composant en question. On ne mesure pas la vitesse d'un disque dur de la même manière que celle d'un écran. Par exemple, le nombre de plateaux d'un disque dur n'a pas d'équivalent pour un écran. Divers cours seront consacrés à chaque périphérique, aussi nous aborderons plus en détail les mesures de performances des différents périphériques dans ceux-ci. Cependant, on peut donner le principe de base pour les mémoires de masse.
Le débit d'une mémoire de masse ou d'un périphérique est le produit de deux facteurs : le nombre d'opérations d'entrée-sortie par secondes, et la taille des données échangée par opération. Ces opérations d'entrée-sortie correspondent chacune à un échange de données entre le périphérique et le reste de l'ordinateur, via le bus. Cela peut se résumer par la formule suivante, avec D le débit du HDD, IOPS le nombre d'opérations disque par secondes, et la quantité de données échangée lors d'une opération d'entrée-sortie : . Augmenter la taille des données transmises augmente donc le débit, mais cette technique est rarement utilisée. Les bus ne sont extensibles à l'infini. A la place, la majorité des périphériques incorpore diverses optimisations pour augmenter l'IOPS, ce qui permet un meilleur débit pour une taille T identique.


La performance du processeur
Concevoir un processeur n'est pas une chose facile et en concevoir un qui soit rapide l'est encore moins, surtout de nos jours. Pour comprendre ce qui fait la rapidité d'un processeur, nous allons devoir déterminer ce qui fait qu'un programme lancé sur notre processeur va prendre plus ou moins de temps pour s’exécuter.
Le temps d’exécution d'une instruction : CPI et fréquence
Le temps que met un programme pour s’exécuter est le produit :
- du nombre moyen d'instructions exécutées par notre programme ;
- de la durée moyenne en seconde d'une instruction.

Le nombre d'instructions peut varier suivant les données manipulées par le programme, leur taille, leur quantité, etc. Ce nombre a un petit nom : il s'appelle l'Instruction path length. On ne peut pas simplifier ce terme, qui dépend essentiellement du programmeur et du compilateur, contrairement à la durée moyenne d'une instruction, intégralement dépendante de la conception du processeur.
Il se trouve qu'il est possible de reformuler l'équation précédente en faisant intervenir la fréquence du processeur. Intuitivement, plus la fréquence du processeur est élevée, plus il sera puissant. Faire intervenir la fréquence demande de reformuler le temps d’exécution d'une instruction en nombre de cycles d'horloge. En effet, chaque opération prend un certain temps, un certain nombre de cycles d'horloge. Par exemple, sur les processeurs modernes, une addition va prendre un cycle d'horloge, une multiplication entre 1 et 2 cycles, etc. Cela dépend du processeur, de l'opération, et d'autres paramètres assez compliqués. Mais on peut calculer un nombre moyen de cycle d'horloge par opération : le CPI (Cycle Per Instruction). La durée moyenne en seconde d'une instruction dépend alors :
- du nombre moyen de cycles d'horloge nécessaires pour exécuter une instruction, qu'on notera CPI (ce qui est l'abréviation de Cycle Per Instruction) ;
- et de la durée d'un cycle d'horloge.
En notant N ce nombre moyen d'instruction, et P la durée d'un cycle d'horloge (P pour période), le temps T d’exécution d'un programme est égal à :

Quand on sait que la fréquence n'est rien d'autre que l'inverse de la période d'un cycle d'horloge, on peut récrire cette équation comme ceci :

La puissance de calcul : IPC et fréquence
On peut rendre compte de la puissance du processeur par une seconde approche. Au lieu de faire intervenir le temps mis pour exécuter une instruction, on peut utiliser son inverse : la puissance de calcul, à savoir le nombre de calculs que l'ordinateur peut faire par secondes. En toute rigueur, cette puissance de calcul se mesure en nombre d'instructions par secondes, une unité qui porte le nom de IPS. On a alors :

En pratique, la puissance de calcul se mesure en MIPS : Million Instructions Per Second, (million de calculs par seconde en français). Plus un processeur a un MIPS élevé, plus il sera rapide : un processeur avec un faible MIPS mettra plus de temps à faire une même quantité de calcul qu'un processeur avec un fort MIPS. Le MIPS est surtout utilisé comme estimation de la puissance de calcul sur des nombres entiers. Mais il existe cependant une mesure annexe, utilisée pour la puissance de calcul sur les nombres flottants : le FLOPS, à savoir le nombre d'opérations flottantes par seconde. Qu'il s'agisse des FLOPS ou des MIPS, on observe que la puissance de calcul augmente du fil du temps.
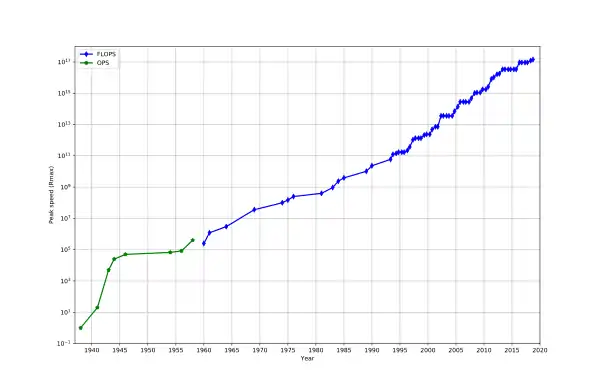
MIPS et FLOPS dépendent de la fréquence : plus la fréquence est élevée, plus le processeur sera rapide. Mais la relation entre fréquence et puissance de calcul dépend fortement du processeur. Par exemple, deux processeurs différents peuvent avoir des puissances de calcul très différentes avec des fréquences identiques. La raison à cela est que la puissance de calcul dépend aussi du CPI. La raison à cela est simple : elle vient de la définition même de la puissance de calcul. Par définition, on a :

En remplaçant le temps d’exécution d'une instruction par sa valeur, on a :

On voit que la puissance de calcul dépend de la fréquence : plus celle-ci est élevée, plus la puissance de calcul l'est aussi. Par contre, elle ne dépend pas du CPI, mais de son inverse : le nombre de calculs qui sont effectués par cycle d'horloge. Celui-ci porte le doux nom d'IPC (Instruction Per Cycle). Celui-ci a plus de sens sur les processeurs actuels, qui peuvent effectuer plusieurs calculs en même temps, dans des circuits différents (des unités de calcul différentes, pour être précis). Sur ces ordinateurs, l'IPC est supérieur à 1. En remplacant l'inverse du CPI par l'IPC, on a alors :


La puissance de calcul est égale à la fréquence multipliée par l'IPC. En clair, plus la fréquence ou l'IPC sont élevés, plus le processeur sera rapide. La fréquence est généralement une information qui est mentionnée lors de l'achat d'un processeur. Malheureusement, l'IPC ne l'est pas. La raison vient du fait que la mesure de l'IPC n'est pas normalisée et qu'il existe de très nombreuses façons de le mesurer. Il faut dire que l'IPC varie énormément suivant les opérations, le programme, diverses optimisations matérielles, etc.
Comment Augmenter les performances d'un processeur ?
On vient de voir que le temps d’exécution d'un programme est décrit par la formule suivante :

Les équations précédentes nous disent qu'il existe trois moyens pour accélérer un programme :
- diminuer le nombre d'instructions à exécuter ;
- diminuer le CPI (nombre de cycles par instruction) ou augmenter l'IPC ;
- augmenter la fréquence.
Voyons en détail ces trois solutions.
Diminuer l'instruction path length
Pour cela, il existe plusieurs solutions : demander au programmeur d'optimiser son programme ou améliorer le jeu d'instruction. Cette dernière solution peut s'implémenter facilement. Il suffit de créer des instructions plus complexes, capables de remplacer des suites d'instructions simples : il n'est pas rare qu'une grosse instruction complexe fasse exactement la même chose qu'une suite d'instructions plus élémentaires. Par exemple, on peut implémenter des instructions pour le calcul de la racine carrée, de l'exponentielle, des puissances, des fonctions trigonométriques : cela évite d'avoir à simuler ces calculs à partir d'additions ou de multiplications. Les programmes qui font alors usage de ces opérations compliquées seront naturellement plus rapides.
Cependant, cette solution a un défaut : les occasions d'utiliser les instructions complexes sont assez rares, ce qui fait que les compilateurs ou programmeurs ne les utilisent pas, même quand elles peuvent être utiles. De plus, ajouter des instructions complexes est quelque chose qui doit se faire sur le long terme, avec le poids de la compatibilité, ce qui n'est pas sans poser quelques problèmes. Par exemple, un programme qui utiliserait des instructions complexes récentes ne peut pas fonctionner sur les anciens processeurs ne possédant pas ces instructions. Ainsi, on a beau rajouter des tas d'instructions dans nos processeurs, il faut attendre que tout le monde ait un processeur avec ces nouvelles instructions pour les utiliser. Pour donner un exemple très simple : à votre avis, sur les nouvelles instructions rajoutées dans chaque nouveau processeur Intel, AMD, ou ARM, combien sont réellement utilisées dans les programmes que vous utilisez ? Combien utilisent les instructions SSE, AVX ou autres extensions récentes ? Très peu.
Diminuer le CPI
Il existe différentes solutions pour diminuer CPI.
Tout d'abord, on peut concevoir notre processeur de façon à diminuer le temps mis par notre processeur pour exécuter une instruction. C'est particulièrement difficile et nécessite de refaire les circuits de notre processeur, trouver de nouveaux algorithmes matériels pour effectuer une instruction, améliorer le fonctionnement de notre processeur et sa conception, etc.
Une autre solution consiste à mieux choisir les instructions utilisées. Comme je l'ai dit plus haut, le nombre CPI est un nombre moyen : certaines instructions sont plus rapides que d'autres. En utilisant de préférence des instructions rapides au lieu d'instructions plus lentes pour faire la même chose, on peut facilement diminuer le CPI. De nos jours, les programmeurs n'ont que très peu d'influence sur le choix des instructions à utiliser : les langages de haut niveau comme le C++ ou le Java se sont démocratisés et ont délégués cette tache aux compilateurs (qui se débrouillent particulièrement bien, en passant).
La dernière solution consiste à exécuter plusieurs instructions à la fois, à augmenter le débit d’instructions. L'idée est d'augmenter l'IPC non pas en jouant sur le temps d'une instruction, mais en exécutant plusieurs instructions durant un même cycle. Ce faisant, on peut augmenter l'IPC, même sans changer le temps que met une instruction à s’exécuter. Les processeurs récents utilisent beaucoup ce genre d'astuce et sont capables d’exécuter plusieurs dizaines, voire centaines d'instructions en parallèle. Une bonne partie de la fin du cours est d'ailleurs dédiée aux techniques qui permettent ce genre de prouesses.
Augmenter la fréquence
Augmenter la fréquence demande d'utiliser des composants électroniques plus rapides. Généralement, cela nécessite de miniaturiser les transistors de notre processeur : plus un transistor est petit, plus il est rapide. Diminuer la taille des transistors permet de les rendre plus rapides. C'est un scientifique du nom de Robert Dennard qui a découvert un moyen de rendre un transistor plus rapide en diminuant certains de ses paramètres physiques. De plus, la vitesse de transmission des bits dans les fils d'interconnexions est proportionnelle à leur longueur : plus ces fils seront courts, plus la transmission sera rapide. Ce qui est clairement un second effet positif de la miniaturisation sur la fréquence.
Sachant que la loi de Moore nous dit que le nombre de transistors d'un processeur est multiplié par 2 tous les deux ans, on peut s'attendre à ce qu'il en soit de même pour la fréquence. En réalité, la fréquence ne dépend pas du nombre de transistor, mais de la longueur de leur côté, la finesse de gravure. La loi de Moore dit que les transistors prennent 2 fois moins de place tous les deux ans. Or, les transistors sont réunis sur une surface : qui dit diminution par deux de la surface signifie division par de la longueur d'un transistor, de sa finesse de gravure. Ainsi, la finesse de gravure est divisée par tous les deux ans. La fréquence ces processeurs est, en conséquence, multipliée par tous les deux ans, ce qui donne environ 40% de performances en plus tous les deux ans. Du moins, c'est la théorie… En réalité, cette augmentation de 40% n'est qu'une approximation : la fréquence effective d'un processeur dépend fortement de sa conception (de la longueur du pipeline, notamment) et des limites imposées par la consommation thermique.

L'évolution de la performance dans le temps
On vient de voir comment quantifier la performance d'un processeur : avec sa fréquence, et avec son IPC/CPI. Il va de soi que les nouveaux processeurs sont plus puissants que les anciens. La raison à cela vient des optimisations apportées par les concepteurs de processeurs. La plupart de ces optimisations ne sont cependant possibles qu'avec la miniaturisation des transistors, qui leur permet d'aller plus vite. On a vu plus haut que la vitesse des transistors est proportionnelle à la finesse de gravure. En conséquence, tous deux augmentent de 40 % tous les deux ans (elle est multipliée par la racine carrée de deux). Pour cette raison, la fréquence devrait augmenter au même rythme. Cependant, la fréquence dépend aussi de la rapidité du courant dans les interconnexions (les fils) qui relient les transistors, celles-ci devenant de plus en plus un facteur limitant pour la fréquence.
De plus, si la miniaturisation permet d'augmenter la fréquence, elle permet aussi d'améliorer l'IPC et le CPI. Cependant, si l'effet est direct sur la fréquence, il est assez indirect en ce qui concerne le CPI. La loi de Pollack dit que l'augmentation de l'IPC d'un processeur est approximativement proportionnelle à la racine carrée du nombre de transistors ajoutés : si on double le nombre de transistors, la performance est multipliée par la racine carrée de 2. En utilisant la loi de Moore, on en déduit qu'on gagne approximativement 40% d'IPC tous les deux ans, à ajouter aux 40 % d'augmentation de fréquence.
On peut expliquer cette loi de Pollack assez simplement. Il faut savoir que les processeurs modernes peuvent exécuter plusieurs instructions en même temps (on parle d’exécution superscalaire), et peuvent même changer l'ordre des instructions pour gagner en performances (on parle d’exécution dans le désordre). Pour cela, les instructions sont préchargées dans une mémoire tampon de taille fixe, interne au processeur, avant d'être exécutée en parallèle dans divers circuits de calcul. Cependant, le processeur doit gérer les situations où une instruction a besoin du résultat d'une autre pour s'exécuter : si cela arrive, on ne peut exécuter les instructions en parallèle. Pour détecter une telle dépendance, chaque instruction doit être comparée à toutes les autres, pour savoir quelle instruction a besoin des résultats d'une autre. Avec N instructions, vu que chacune d'entre elles doit être comparée à toutes les autres, ce qui demande N^2 comparaisons. En doublant le nombre de transistors, on peut donc doubler le nombre de comparateurs, ce qui signifie que l'on peut multiplier le nombre d'instructions exécutables en parallèle par la racine carrée de deux.
On peut cependant contourner la loi de Pollack, qui ne vaut que pour un seul processeur. Mais en utilisant plusieurs processeurs, la performance est la somme des performances individuelles de chacun d'entre eux. C'est pour cela que les processeurs actuels sont double, voire quadruple cœurs : ce sont simplement des circuits imprimés qui contiennent deux, quatre, voire 8 processeurs différents, placés sur la même puce. Chaque cœur correspond à un processeur. En faisant ainsi, doubler le nombre de transistors permet de doubler le nombre de cœurs et donc de doubler la performance, ce qui est mieux qu'une amélioration de 40%.
La performance d'une mémoire
Toutes les mémoires ne sont pas faites de la même façon et les différences entre mémoires sont nombreuses. Dans cette partie, on va passer en revue les différences les plus importantes.
La capacité mémoire
Pour commencer, une mémoire ne peut pas stocker une quantité infinie de données : qui n'a jamais eu un disque dur ou une clé USB plein ? Et à ce petit jeu là, toutes les mémoires ne sont pas égales : elles n'ont pas la même capacité. Cette capacité mémoire n'est autre que le nombre maximal de bits qu'une mémoire peut contenir. Dans la majorité des mémoires, les bits sont regroupés en paquets de taille fixe : des cases mémoires, aussi appelées bytes. De nos jours, le nombre de bits par byte est généralement un multiple de 8 bits : ces groupes de 8 bits s'appellent des octets. Mais toutes les mémoires n'ont pas des bytes d'un octet ou plusieurs octets : certaines mémoires assez anciennes utilisaient des cases mémoires contenant 1, 2, 3, 4, 7, 18, 36 bits.
Unités de capacité mémoire : kilo, méga et gigas
Le fait que les mémoires aient presque toutes des bytes faisant un octet nous arrange pour compter la capacité d'une mémoire. Au lieu de compter cette capacité en bits, on préfère mesurer la capacité d'une mémoire en donnant le nombre d'octets que celle-ci peut contenir. Mais les mémoires des PC font plusieurs millions ou milliards d'octets. Pour se faciliter la tâche, on utilise des préfixes pour désigner les différentes capacités mémoires. Vous connaissez surement ces préfixes : kibioctets, mébioctets et gibioctets, notés respectivement Kio, Mio et Gio.
| Préfixe | Capacité mémoire en octets | Puissance de deux |
|---|---|---|
| Kio | 1024 | 210 octets |
| Mio | 1 048 576 | 220 octets |
| Gio | 1 073 741 824 | 230 octets |
On peut se demander pourquoi utiliser des puissances de 1024, et ne pas utiliser des puissances un peu plus communes ? Dans la majorité des situations, les électroniciens préfèrent manipuler des puissances de deux pour se faciliter la vie. Par convention, on utilise souvent des puissances de 1024, qui est la puissance de deux la plus proche de 1000. Or, dans le langage courant, kilo, méga et giga sont des multiples de 1000. Quand vous vous pesez sur votre balance et que celle-ci vous indique 58 kilogrammes, cela veut dire que vous pesez 58000 grammes. De même, un kilomètre est égal à 1000 mètres, et non 1024 mètres.
Autrefois, on utilisait les termes kilo, méga et giga à la place de nos kibi, mebi et gibi, par abus de langage. Mais peu de personnes sont au courant de l'existence de ces nouvelles unités, et celles-ci sont rarement utilisées. Et cette confusion permet aux fabricants de disques durs de nous « arnaquer » : Ceux-ci donnent la capacité des disques durs qu'ils vendent en kilo, mega ou giga octets : l’acheteur croit implicitement avoir une capacité exprimée en kibi, mebi ou gibi octets, et se retrouve avec un disque dur qui contient moins de mémoire que prévu.
L'évolution de la capacité suivant le type de mémoire
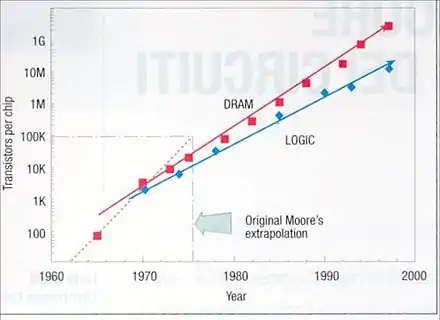
De manière générale, les mémoires électroniques sont plus rapides que les mémoires magnétiques ou optiques, mais ont une capacité inférieure. La loi de Moore a une influence certaine sur la capacité des mémoires électroniques. En effet, une mémoire électronique est composée de bascules de 1 bit, elles-mêmes composées de transistors : plus la finesse de gravure est petite, plus la taille d'une bascule sera faible. Quand le nombre de transistors d'une mémoire double, on peut considérer que le nombre de bascules, et donc la capacité double. D'après la loi de Moore, cela arrive tous les deux ans, ce qui est bien ce qu'on observe pour les mémoires RAM.
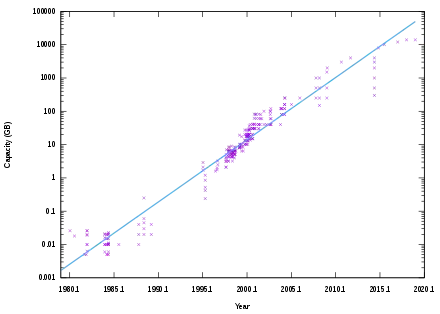
Par contre, les mémoires magnétiques, comme les disques durs, augmentent à un rythme différent, celles-ci n'étant pas composées de transistors.
Le temps d’accès d'une mémoire
La vitesse d'une mémoire correspond au temps qu'il faut pour récupérer une information dans la mémoire, ou pour y effectuer un enregistrement. Lors d'une lecture/écriture, il faut attendre un certain temps que la mémoire finisse de lire ou d'écrire la donnée : ce délai est appelé le temps d'accès, ou aussi temps de latence. Plus celui-ci est bas, plus la mémoire est rapide. Il se mesure en secondes, millisecondes, microsecondes pour les mémoires les plus rapides. Généralement, le temps de latence dépend de temps de latences plus élémentaires, qui sont appelés les timings mémoires.
Cependant, tous les accès à la mémoire ne sont pas égaux en termes de temps d'accès. Généralement, lire une donnée ne prend pas le même temps que l'écrire. Dit autrement, le temps d'accès en lecture est souvent inférieur au temps d'accès en écriture. Il faut dire qu'il est beaucoup plus fréquent de lire dans une mémoire qu'y écrire, et les fabricants préfèrent donc réduire le temps d'accès en lecture.
Voici les temps d'accès moyens en lecture de chaque type de mémoire :
- Registres : 1 nanoseconde (10-9)
- Caches : 10 - 100 nanosecondes (10-9)
- Mémoire RAM : 1 microseconde (10-6)
- Mémoires de masse : 1 milliseconde (10-3)
Le débit d'une mémoire
Enfin, toutes les mémoires n'ont pas le même débit binaire. Par débit, on veut dire que certaines sont capables d'échanger un grand nombre de donnée par secondes, alors que d'autres ne peuvent échanger qu'un nombre limité de données sur le bus. Le débit binaire est la quantité de données que la mémoire peut envoyer ou recevoir par seconde. Il se mesure en en octets par secondes ou en bits par secondes. Évidemment, plus ce débit est élevé, plus la mémoire sera rapide. Il ne faut pas confondre le débit et le temps d'accès. Pour faire une analogie avec les réseaux, le débit binaire peut être vu comme la bande passante, alors que le temps d'accès serait similaire au ping. Il est parfaitement possible d'avoir un ping élevé avec une connexion qui télécharge très vite, et inversement. Pour la mémoire, c'est similaire. D'ailleurs, le débit binaire est parfois improprement appelé bande passante.
Dans presque tous les cas, le débit dépend fortement de la fréquence de la mémoire. Or, l'évolution de la fréquence des mémoires suit plus ou moins celle des processeurs, elle double au même rythme. Mais malheureusement, cette fréquence reste inférieure à celle des processeurs. Cette augmentation de fréquence permet au débit des mémoires d'augmenter avec le temps. En effet, à chaque cycle d'horloge, la mémoire peut envoyer ou recevoir une quantité fixe de donnée. En multipliant cette largeur du bus par la fréquence, on obtient le débit. Par contre, la fréquence n'a aucun impact sur le temps de latence.
La performance des mémoires caches
Ce qui a été dit précédemment vaut aussi pour les mémoires caches, qui ont un débit, une fréquence, un temps de latence et une capacité. Mais l'analyse de la performance des mémoires est cependant plus riche pour les caches que pour les autres mémoires. Pour comprendre pourquoi, il faut savoir que le cache contient une copie de certaines données présentes en RAM. La copie présente dans le cache est accessible bien plus rapidement que celle en RAM, le cache étant beaucoup plus rapide que la RAM. Mais seule une faible partie de ces données sont présentes dans le cache, les autres données devant être lues ou écrites dans la RAM. Tout accès mémoire provenant du processeur est intercepté par le cache, qui vérifie si la donnée demandée est présente ou non dans le cache. Si c'est le cas, la donnée voulue est présente dans le cache : on a un succès de cache (cache hit) et on accède à la donnée depuis le cache. Sinon, c'est un défaut de cache (cache miss) : on est obligé d’accéder à la RAM ou de recopier notre donnée de la RAM dans le cache.
Le taux de succès ou de défauts
Le taux de succès (hit ratio) est un premier indicateur des performances du cache, mais un indicateur assez imparfait. C'est le pourcentage d'accès mémoire qui ne déclenchent pas de défaut de cache. Plus il est élevé, plus le processeur accède au cache à la place de la RAM et plus le cache est efficace. Certains chercheurs préfèrent utiliser le taux de défauts, à savoir le pourcentage d'accès mémoire qui entrainent un défaut de cache. Plus il est bas, meilleures sont les performances. Le taux de défaut est relié au taux de succès par l'équation . Par définition, il est égal à :


Plutôt que de comparer le nombre de défauts/succès de cache au nombre d'accès mémoire, il est aussi possible de diviser le nombre de défauts par le nombre total d'instructions. On obtient alors le taux de défauts/succès par instruction, une autre métrique utile. Par définition, elle est égale à :

Le taux de succès ne dépend pas que du cache, mais aussi de la conception des programmes exécutés. Une bonne utilisation du cache (ainsi que de la mémoire virtuelle) repose sur le programmeur qui doit prendre en compte les principes de localités dès la conception de ses programmes. Par exemple, un programmeur peut parfaitement tenir compte du cache au niveau de son algorithme : on peut citer l'existence des algorithmes cache oblivious, qui sont conçus pour être optimaux quelle que soit la taille du cache. Ces algorithmes permettent le plus souvent de gros gains en performances dans la plupart des situations sur les architectures modernes. Le programmeur peut aussi choisir ses structures de données de manière à améliorer la localité. Par exemple, un tableau est une structure de donnée respectant le principe de localité spatiale, tandis qu'une liste chainée ou un arbre n'en sont pas (bien qu'on puisse les implémenter de façon à limiter la casse). D'autres optimisations sont parfois possibles : par exemple, le sens de parcours d'un tableau multidimensionnel peut faire une grosse différence. Cela permet des gains très intéressants pouvant se mesurer avec des nombres à deux ou trois chiffres. Je vous recommande, si vous êtes programmeur, de vous renseigner le plus possible sur les optimisations de code ou algorithmiques qui concernent le cache : il vous suffira de chercher sur Google. Il y a une citation qui résume bien cela, prononcée par un certain Terje Mathisen. Si vous ne le connaissez pas, cet homme est un vieux programmeur (du temps durant lequel on codait encore en assembleur), grand gourou de l’optimisation, qui a notamment travaillé sur le moteur de Quake 3 Arena.
| « | |
| Almost all programming can be viewed as an exercise in caching. | |
| » | |
| — Terje Mathisen |
Si certains défauts de cache sont inévitables quel que soit le cache, d'autres défauts peuvent être évités en augmentant la capacité du cache. En effet, quand le processeur veut charger une donnée dans un cache plein, des données sont rapatriées en RAM pour laisser place aux données à charger. Et si les données rapatriées sont accédées ultérieurement, un défaut de cache s'ensuit. Plus le cache est gros, moins il a de chances d'être rempli, moins il doit rapatrier de données, plus son taux de succès augmente. Mais nous reviendrons sur le lien entre taille du cache et taux de défaut plus bas.
La latence moyenne d'un cache
Le temps mis pour lire ou écrire une donnée varie en présence d'un cache. Certaines lectures/écritures vont atterrir directement dans le cache (succès) tandis que d'autres devront aller chercher leur contenu en mémoire RAM (défaut de cache). Dans tous les cas, qu'il y ait défaut ou non, le cache sera consulté et mettra un certain temps à répondre, égal au temps de latence du cache. Tous les accès mémoires auront donc une durée au moins égale au temps de latence du cache, qui sera notée . En cas de succès, le cache aura effectué la lecture ou l'écriture, et aucune action supplémentaire n'est requise. Ce qui n'est pas le cas en cas de défaut : le processeur devra aller lire/écrire la donnée en RAM, ce qui prend un temps supplémentaire égal au temps de latence de la mémoire RAM. Un défaut ajoute donc un temps, une pénalité, à l'accès mémoire. Dans ce qui suivra, le temps d'accès à la RAM sera noté . Fort de ces informations, nous pouvons calculer le temps de latence moyen d'un accès mémoire, qui est la somme du temps d'accès au cache (pour tous les accès mémoire), multiplié par le temps lié aux défauts. On a alors :



On voit que plus le taux de succès est élevé, plus le temps de latence moyen sera bas, et inversement. Ce qui explique l'influence du taux de succès sur les performances du cache, influence assez importante sur les processeurs actuels. De nos jours, le temps que passe le processeur dans les défauts de cache devient de plus en plus un problème au fil du temps, et gérer correctement le cache est une nécessité, particulièrement sur les processeurs multi-cœurs. Il faut dire que la différence de vitesse entre processeur et mémoire est tellement importante que les défauts de cache sont très lents : alors qu'un succès de cache va prendre entre 1 et 5 cycles d'horloge, un cache miss fera plus dans les 400-1000 cycles d'horloge. Tout ce temps sera du temps de perdu que le processeur aura du mal à mitiger. Autant dire que réduire les défauts de cache est beaucoup plus efficace que d'optimiser les calculs effectués par le processeur (erreur courante chez de nombreux programmeurs, notamment débutants).
L'impact de la taille du cache sur le taux de défaut et la latence
Il y a un lien entre taille du cache, taux de défaut, débit binaire et latence moyenne. Globalement, plus un cache est gros, plus il est lent. Simple application de la notion de hiérarchie mémoire vue il y a quelques chapitres. Les raisons à cela sont nombreuses, mais nous ne pouvons pas les aborder ici, car il faudrait que nous sachions comment fonctionne un cache et ce qu'il y a à l'intérieur et il vous faudra attendre de nombreux chapitres pour cela. Toujours est-il que la latence moyenne d'un cache assez gros est assez importante. De même, le débit binaire d'un cache diminue avec sa taille, mais dans une moindre mesure. Les petits caches ont donc un gros débit binaire et une faible latence, alors que c'est l'inverse pour les gros caches. D'où l'existence, comme on l'a vu dans le précédent chapitre, d'une hiérarchie de mémoires caches.
Un cache de grande capacité améliore donc le taux de succès, mais cela se fait au détriment de son temps de latence et de son débit, ce qui fait qu'il y a un compromis assez difficile à trouver entre taille du cache, latence et débit. Il peut arriver qu'augmenter la taille du cache augmente son temps d'accès au point d'entrainer une baisse de performance. Par exemple, les processeurs Nehalem d'Intel ont vus leurs performances dans certains jeux vidéos baisser de 2 à 3 %, malgré de nombreuses améliorations architecturales, parce que la latence du cache L1 avait augmentée de 2 cycles d'horloge. Pour résoudre ce problème, les concepteurs de processeur utilisent plusieurs caches au sein d'un processeur : certains sont petits mais rapides, d'autres de grande capacité mais lents, avec parfois des caches intermédiaires.
Pour avoir une petite idée du compromis à faire, regardons la relation entre taille du cache et taux de défaut. Il existe une relation approximative entre ces deux variables, appelée la loi de puissance des défauts de cache. Elle donne le nombre total de défaut de cache en fonction de la taille du cache et de deux autres paramètres. Voici cette loi :
- , avec et deux coefficients qui dépendent du programme exécuté.



Le coefficient est généralement compris entre 0.3 et 0.7, guère plus, et varie suivant le programme exécuté. Précisons que cette loi ne marche que si le cache est assez petit par rapport aux données à utiliser. Pour un cache assez gros et des données très petites, la relation précédente est mise en défaut. Pour s'en rendre compte, il suffit d'étudier le cas extrême où toutes les données nécessaires tiennent dans le cache. Dans ce cas, il n'y a qu'un nombre fixe de défauts de cache : autant qu'il faut charger de données dans le cache. Le nombre de défauts de cache observé dans cette situation n'est autre que le coefficient de la situation précédente, mais il n'y a aucune dépendance entre taux de défaut et taille du cache.
L'origine de cette relation s'explique quand on regarde combien de fois chaque donnée est réutilisée lors de l’exécution d'un programme. .a plupart des données finissent par être ré-accédées à un moment ou un autre et il se passe un certain temps entre deux accès à une même donnée. Sur la plupart des programmes, les observations montrent que beaucoup de réutilisations de données se font après un temps très court et qu'inversement, peu de ré-accès se font après un temps inter-accès long. Si on compte le nombre de réutilisation qui ont un temps inter-accès bien précis, on retrouve une loi de puissance identique à celle vue précédemment :
- , avec t le temps moyen entre deux réutilisations.

Le coefficient est ici compris entre 1.7 et 1.3. De manière générale, les coefficients et sont reliés par la relation , ce qui montre qu'il y a un lien entre les deux relations.


Précisons cependant que la loi de puissance précédente ne vaut pas pour tous les programmes informatiques, mais seulement pour la plupart d’entre eux. Il n'est pas rare de trouver quelques programmes pour lesquels les accès aux données sont relativement prédictibles et où une bonne optimisation du code fait que la loi de puissance précédente n'est pas valide.
La loi de puissance des défauts de cache peut se démontrer à partir de la relation précédente, sous certaines hypothèses. Si un suppose que le cache est assez petit par rapport aux données, alors les deux relations sont équivalentes. L'idée qui se cache derrière la démonstration est que si le temps entre deux accès à une donnée est trop long, alors la donnée accédée aura plus de chance d'être rapatriée en RAM, ce qui cause un défaut de cache. La chance de rapatriement dépend de la taille du cache, un cache plus gros peut conserver plus de données et a donc un temps avant rapatriement plus long.