Un programme peut être exécuté sur des ordinateurs ayant des capacités mémoires diverses et variées et dans des conditions très différentes. Et il faut faire en sorte qu'un programme fonctionne sur des ordinateur ayant peu de mémoire sans poser problème. Après tout, quand on conçoit un programme, on ne sait pas toujours quelle sera la quantité mémoire que notre ordinateur contiendra, et encore moins comment celle-ci sera partagée entre nos différentes programmes en cours d’exécution : s'affranchir de limitations sur la quantité de mémoire disponible est un plus vraiment appréciable. Ce besoin est appelé l'abstraction matérielle de la mémoire.
Enfin, plusieurs programmes sont présents en même temps dans notre ordinateur, et doivent se partager la mémoire physique. Si un programme pouvait modifier les données d'un autre programme, on se retrouverait rapidement avec une situation non prévue par le programmeur. Cela a des conséquences qui vont de comiques à catastrophiques, et cela fini très souvent par un joli plantage. Il faut donc introduire des mécanismes de protection mémoire. Pour éviter cela, chaque programme a accès à des portions de la mémoire dans laquelle lui seul peut écrire ou lire. Le reste de la mémoire est inaccessible en lecture et en écriture, à part pour la mémoire partagée entre différents programmes. Toute tentative d'accès à une partie de la mémoire non autorisée déclenchera une exception matérielle (rappelez-vous le chapitre sur les interruptions) qui devra être traitée par une routine du système d'exploitation. Généralement, le programme fautif est sauvagement arrêté et un message d'erreur est affiché à l'écran.
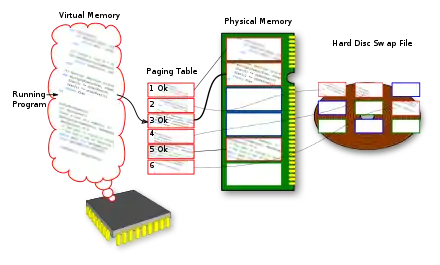
Ces détails concernant l'organisation et la gestion de la mémoire sont assez compliqués à gérer, et faire en sorte que les programmes applicatifs n'aient pas à s'en soucier est un plus vraiment appréciable. Ce genre de problèmes a eu des solutions purement logicielles, mais quelques techniques règlent ces problèmes directement au niveau du matériel : on parle de mémoire virtuelle. Avec la mémoire virtuelle, tout se passe comme si notre programme était seul au monde et pouvait lire et écrire à toutes les adresses disponibles à partir de l'adresse zéro. Chaque programme a accès à autant d'adresses que ce que le processeur peut adresser : on se moque du fait que des adresses soient réservées aux périphériques, de la quantité de mémoire réellement installée sur l'ordinateur, ou de la mémoire prise par d'autres programmes en cours d’exécution. Pour éviter que ce surplus de fausse mémoire pose problème, on utilise une partie des mémoires de masse (disques durs) d'un ordinateur en remplacement de la mémoire physique manquante.
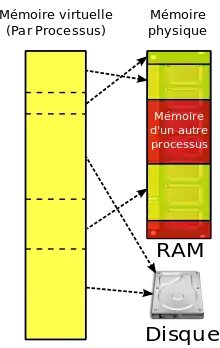

Bien sûr, les adresses de la fausse mémoire vue par le programme sont des adresses fictives, qui devront être traduites en adresses mémoires réelles pour être utilisées. Les fausses adresses sont ce qu'on appelle des adresses logiques, alors que les adresses réelles sont appelées adresses physiques. Pour implémenter cette technique, il faut rajouter un circuit qui traduit les adresses logiques en adresses physiques : ce circuit est appelé la memory management unit. Il faut préciser qu'il existe différentes méthodes pour gérer ces adresses logiques et les transformer en adresses physiques : les principales sont la segmentation et la pagination. La suite du chapitre va détailler ces deux techniques.
Le bank switching
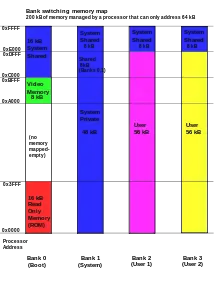
Le bank switching, aussi appelé commutation de banque, permet d'utiliser un bus d'adresse plus grand que les adresses du processeur. L'adresse réelle est plus grande que l'adresse utilisée par le processeur, les bits manquants étant fournit par un registre configurable du processeur : le registre de banque. L'espace mémoire du processeur est présent en plusieurs exemplaires, sélectionnés par la valeur du registre de banque. Chaque exemplaire de l'ensemble des adresses du processeur s'appelle une banque. On peut changer de banque en changeant le contenu de ce registre : le processeur dispose souvent d'instructions spécialisées qui en sont capables.
En répartissant les données utiles dans différentes banques, le processeur peut donc adresser beaucoup plus de mémoire. De plus, cette technique se marie assez bien avec les entrées-sorties mappées en mémoire. Par exemple, supposons que j'ai besoin d'adresser une mémoire ROM de 4 kibioctets, une RAM de 8 kibioctets, et divers périphériques. Le processeur a un bus d'adresse de 12 bits, ce qui limite à 4kibioctets. Dans ce cas, je peux réserver 4 banques : une pour la ROM, une pour les périphériques, et deux banques qui contiennent chacune la moitié de la RAM. La simplicité et l'efficacité de cette technique font qu'elle est beaucoup utilisée dans l'informatique embarquée.
 |
 |
La segmentation

Sur les vieux systèmes d'exploitation, chaque programme recevait un bloc de RAM pour lui tout seul, une partition mémoire. La segmentation est une amélioration de cette technique, qui affecte une ou plusieurs partitions par programme. Cela permet à un seul processus d'avoir plusieurs espaces d'adressages, plusieurs mémoires virtuelles à lui tout seul. L'utilité est qu'un programme est rarement un tout unique, mais peut souvent être décomposé en plusieurs ensembles de données/instructions séparés, qui peuvent grossir ou se réduire suivant les circonstances. Par exemple, la pile a une taille qui varie beaucoup, tandis que le code du programme ne change pas. La segmentation permet de découper la mémoire virtuelle d'un processus en sous-partitions de taille variable qu'on appelle improprement des segments. Ainsi, un programme peut utiliser des segments différents pour la pile, le tas, le programme lui-même, et les variables globales. Chaque segment pourra grandir ou diminuer à sa guise, suivant les besoins, ce qui serait beaucoup plus difficile avec une seule partition mémoire.
La relocation avec la segmentation
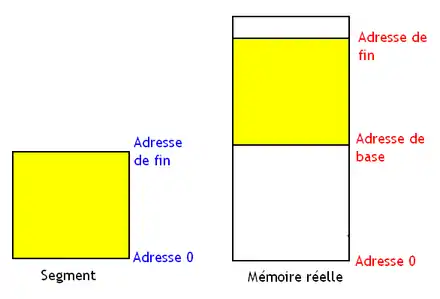
Chaque segment peut être placé n'importe où en mémoire physique par l'OS, ce qui fait qu'il n'a pas d'adresse fixée en mémoire physique et peut être déplacé comme bon nous semble. C'est le système d'exploitation qui gère le placement des partitions/segments dans la mémoire physique. Ainsi, les adresses de destination des branchements et les adresses des données ne sont jamais les mêmes. Il faut donc trouver un moyen pour que les programmes fonctionnent avec des adresses qui changent d'une exécution à l'autre. Ce besoin est appelé la relocalisation. Pour résoudre ce problème, le compilateur considère que le programme commence à l'adresse zéro et laisse l'OS corriger les adresses du programme. Cette correction d'adresse demande simplement d'ajouter un décalage, égal à la première adresse de la partition mémoire. Cette correction peut se faire de deux manières : soit l'OS corrige chaque adresse lors du lancement du programme, soit le processeur s'en charge à chaque accès mémoire. Dans le second cas, cette première adresse est mémorisée dans un registre de base, mis à jour automatiquement lors de chaque changement de programme.
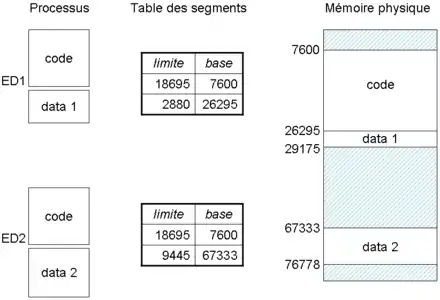
Sur les processeurs x86, la mémoire virtuelle est découpée en 2^16 segments de 2^32 bits, ce qui donne des adresses de 48 bits. Pour identifier un segment, seuls les 16 bits de poids fort de l'adresse 48 bits sont utiles : ils forment ce qu'on appelle un sélecteur de segment. Les 32 bits servent à identifier la position de la donnée dans un segment : ils sont appelés le décalage (offset). La relocalisation se fait de la même manière pour un segment que pour une partition mémoire. Pour cela, l'OS associe chaque segment à son adresse de base dans une table de correspondance, appelée la table des segments. Elle est unique pour chaque programme : la même adresse logique ne donnera pas la même adresse physique selon le programme.

Dans le cas le plus simple, la table des segments est stockée en mémoire RAM, le processeur ne contenant qu'un registre de base mis à jour à chaque changement de segment.
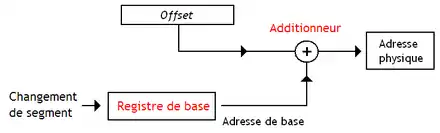
Une autre solution consiste à charger la table de correspondance complète dans un banc de registre dédié.

La protection mémoire avec la segmentation
Un programme ne doit avoir accès qu'à la partition qui lui est dédiée et pas aux autres, sauf dans quelques rares exceptions. Toute tentative d'accès à une autre partition doit déclencher une exception matérielle, qui entraine souvent l'apparition d'un message d'erreur. Tout cela est pris en charge par le système d'exploitation, par l'intermédiaire de mécanismes de protection mémoire, que nous allons maintenant aborder.
Pour commencer, le processeur (ou l'OS) doivent détecter les accès hors-partition, à savoir un programme qui lit/écrit de la mémoire au-delà de la partition qui lui réservée. La solution est de mémoriser les limites du segment dans la page des segments et de vérifier que les accès mémoire ne se font pas au-delà de cette limite. L'adresse de fin de segment est mémorisée dans la table des segments et est récupérée lors de chaque accès. Le processeur vérifie si l'accès se fait dans les clou, en comparant l'adresse accédée avec l'adresse limite. Une autre solution consiste à mémoriser non pas l'adresse, mais l'offset maximal possible dans le segment en cours. Cela économise quelques bits par entrée dans la table des tables. Voici comment se passe la traduction d'une adresse avec la segmentation, en tenant compte de la vérification des accès hors-segment.

Vient ensuite la gestion des droits d'accès : chaque partition/segment se voit attribuer un certain nombre d'autorisations d'accès qui indiquent si l'on peut lire ou écrire dedans, si celui-ci contient un programme exécutable, etc. Lorsqu'on exécute une opération interdite, la MMU déclenche une exception matérielle. Pour cela, l'OS ou la MMU mémorisent les autorisations pour chaque segment. Ces autorisations et les autres informations (registre de base et limite) sont rassemblées dans un descripteur de segment. Quand on accède à un segment, son descripteur est chargé dans des registres du processeur. Pour se simplifier la tache, les concepteurs de processeurs et de systèmes d'exploitation ont décidé de regrouper ces descripteurs dans une portion de la mémoire, spécialement réservée pour l'occasion : la table des descripteurs de segment.

Le partage de segments
Il faut préciser qu'il est possible de partager des segments entre applications. Il suffit de configurer les tables de segment convenablement. Cela peut servir quand plusieurs instances d'une même applications sont lancés simultanément : le code n'ayant pas de raison de changer, celui-ci est partagé entre toutes les instance.
Il est aussi possible de faire en sorte que deux segments se recouvrent l'un autre, à savoir que les deux segments partagent la même mémoire physique. Cela peut servir à partager de la mémoire entre plusieurs applications qui doivent communiquer entre elles.

La pagination
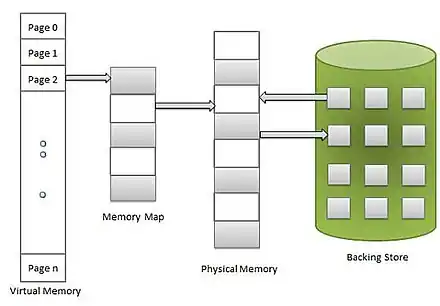
De nos jours, la segmentation est obsolète et n'est plus utilisée : à la place, les OS et processeurs utilisent la pagination. Avec la pagination, la mémoire virtuelle et la mémoire physique sont découpées en blocs de taille fixe, appelés des pages mémoires. La différence avec les segments est que les segments sont de taille variable, alors que les pages sont de taille fixe. La taille des pages varie suivant le processeur et le système d'exploitation et tourne souvent autour de 4 kibioctets. Le contenu d'une page en mémoire fictive est rigoureusement le même que le contenu de la page correspondante en mémoire physique. Cependant, le nombre total de pages en mémoire virtuelle dépasse celui de la mémoire physique.
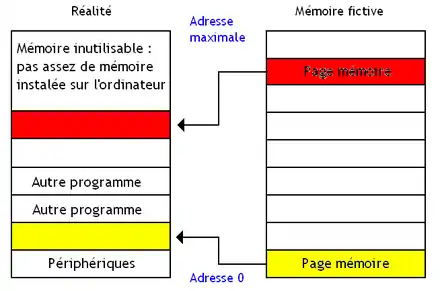
Le surnombre est simplement placé sur le disque dur, dans un fichier appelé le fichier d'échange. Les pages virtuelles vont ainsi faire référence soit à une page en mémoire physique, soit à une page sur le disque dur. Tout accès à une page sur le disque dur va charger celle-ci dans la mémoire RAM, dans une page vide. Les pages font ainsi une sorte de va et vient entre le fichier d'échange et la RAM, suivant les besoins.
La protection mémoire avec la pagination
La protection mémoire est garantie avec des clés de protection, un nombre unique à chaque programme. Le processeur mémorise, pour chaque page, la clé de protection du programme qui a réservé la page. A chaque accès mémoire, le processeur compare la clé de protection du programme en cours d’exécution, et celle de la page adressée. Si les deux clés sont différentes, alors un programme a effectué un accès hors des clous et il se fait sauvagement arrêter.
Comme avec la segmentation, chaque page a des droits d'accès précis, qui permettent d'autoriser ou interdire les accès en lecture, écriture, exécution, etc.
La traduction d'adresse avec la pagination
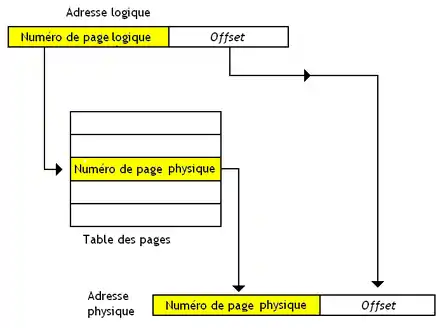
Une adresse (logique ou physique) se décompose donc en deux parties : un numéro de page qui identifie la page et un numéro permettant de localiser la donnée dans la page. Traduire l'adresse logique en adresse physique demande de remplacer le numéro de la page logique en un numéro de page physique. Pour faire cette traduction, il faut se souvenir des correspondances entre numéro de page et adresse de la page en mémoire fictive. Elles sont stockées dans une sorte de table, nommée la table des pages. Celle-ci contient aussi des bits pour savoir si une page est swappée sur le disque dur ou si elle est présente en RAM.
Les tables des pages simples
Dans le cas le plus simple, il n'y a qu'une seule table des pages, qui est adressée par les numéros de page logique. Ainsi, pour chaque numéro (ou chaque adresse) de page logique, on stocke l'adresse de base de la page correspondante en mémoire physique. La table des pages est unique pour chaque programme, vu que les correspondances entre adresses physiques et logiques ne sont pas les mêmes. Cette table des pages est souvent stockée dans la mémoire RAM, à un endroit bien précis, connu du processeur. Accéder à la mémoire nécessite donc d’accéder d'abord à la table des pages en mémoire, puis de calculer l'adresse de notre donnée, et enfin d’accéder à la donnée voulue. Avec cette méthode, la table des pages a autant d'entrée qu'il y a de pages logiques en mémoire virtuelle.
Les tables des pages inversées
Sur certains systèmes, la taille d'une table des pages serait beaucoup trop grande en utilisant les techniques vues au-dessus. Pour éviter cela, on a inventé les tables des pages inversées. L'idée derrière celles-ci est l'inverse de la méthode précédente. La méthode précédente stocke, pour chaque page logique, son numéro de page physique. Les tables des pages inversées font l'inverse : elles stockent, pour chaque numéro de page physique, la page logique qui correspond. Avec cette méthode table des pages contient ainsi autant d'entrées qu'il y a de pages physiques. Elle est donc plus petite qu'avant, vu que la mémoire physique est plus petite que la mémoire virtuelle.
Quand le processeur voudra convertir une adresse virtuelle en adresse physique, la MMU prendra le numéro de page de l'adresse virtuelle, et le recherchera dans la table des pages. Le numéro de l'entrée à laquelle se trouve ce morceau d'adresse virtuelle est le morceau de l'adresse physique. Pour faciliter le processus de recherche dans la page, les concepteurs de systèmes d'exploitation peuvent stocker celle-ci avec ce que l'on appelle une table de hachage.

Les tables des pages multiples par espace d'adressage
Dans les deux cas précédents, il y a une table des page par processus/programme lancé sur l'ordinateur.

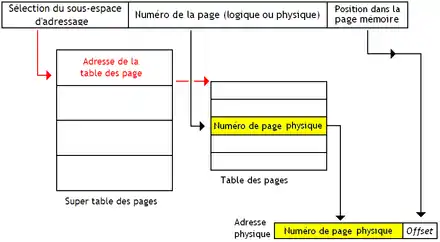
Mais cela a un léger défaut : la table des pages de chaque processus bouffe beaucoup de mémoire. Aussi, les concepteurs de processeurs et de systèmes d'exploitation ont adapté les tables des pages précédentes pour limiter la casse. Ils ont remarqué que les adresses les plus hautes et/ou les plus basses sont les plus utilisées, alors que les adresses situées au milieu de l'espace d'adressage sont peu utilisées en raison du fonctionnement de la pile et du tas. Ainsi, les concepteurs d'OS ont décidé de découper l'espace d'adressage en plusieurs sous-espaces d'adressage de taille identique : certains localisés dans les adresses basses, d'autres au milieu, d'autres tout en haut, etc. Chaque sous-espace d'adressage a sa propre page des tables. Si un sous-espace d'adressage n'est pas utilisé, il n'y a pas besoin d'utiliser de la mémoire pour stocker la table des pages associée. On ne stocke que les tables des pages pour les espaces d'adressage qui contiennent au moins une donnée.
Les premiers bits de l'adresse vont servir à sélectionner quelle table des pages utiliser. Pour cela, il faut connaitre l'adresse à laquelle est stockée chaque table des pages. Pour cela, on utilise une super-table des pages, qui stocke les adresses de début des tables des pages de chaque sous-espace. On peut aussi aller plus loin et découper la table des pages de manière hiérarchique, chaque sous-espace d'adressage étant lui aussi découpé en sous-espaces d'adressages.
Le Translation Lookaside Buffer
Pour éviter d'avoir à lire la table des pages en mémoire RAM à chaque accès mémoire, les concepteurs de processeurs ont décidé d'implanter un cache dédié, le translation lookaside buffer, ou TLB. Il stocke les entrées de la page des tables les plus récemment accédées.

À chaque accès mémoire, le processeur vérifie si le TLB contient l'adresse physique à laquelle accéder. Si c'est le cas, le processeur n'a pas à accéder à la mémoire RAM et va lire directement la donnée depuis ce TLB. L'accès à la RAM est inévitable dans le cas contraire.
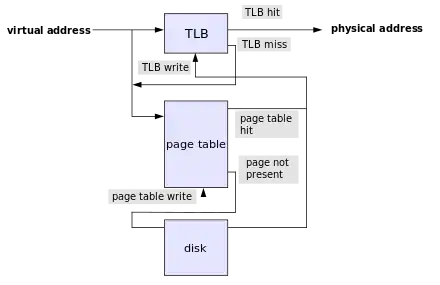
L'accès est géré de deux façon : soit le processeur gère tout seul la situation, soit il délègue cette tâche au système d’exploitation. Dans le second cas, si l'adresse cherchée n'est pas dans le TLB, le processeur va lever une exception matérielle qui exécutera une routine d'interruption chargée de gérer la situation.
Pour des raisons de performances, ce cache est parfois découpé en plusieurs sous-caches L1, L2, L3, etc. Sur les architectures Harvard, on trouve parfois deux TLB séparés : un pour les accès aux instructions, et un pour les accès aux données.
Le remplacement des pages mémoires
La mémoire physique contient moins de pages que la mémoire virtuelle et il faut trouver un moyen pour que cela ne pose pas de problème. La solution consiste à utiliser des mémoires de stockage comme mémoire d'appoint : si on a besoin de plus de pages mémoires que la mémoire physique n'en contient, certaines pages mémoires vont être déplacées sur le disque dur pour faire de la place. Les pages sur le disque dur doivent être chargées en RAM, avant d'être utilisables. Lorsque l'on veut traduire l'adresse logique d'une page mémoire déplacée sur le disque dur, la MMU ne va pas pouvoir associer l'adresse logique à une adresse en mémoire RAM. Elle va alors lever une exception matérielle dont la routine rapatriera la page en mémoire RAM.
Charger une page en RAM ne pose aucun problème tant qu'il existe des pages inoccupée en RAM. Mais si toute la RAM est pleine, il faut déplacer une page mémoire en RAM sur le disque dur pour faire de la place. Tout cela est effectué par le système d'exploitation dont j'ai parlé plus haut. Notons que si on supprime une donnée dont on aura besoin dans le futur, il faudra recharger celle-ci, ce qui prend du temps. Le choix de la page doit être fait avec le plus grand soin et il existe différents algorithmes qui permettent de décider quelle page supprimer de la RAM. Les plus simples sont les suivants.
- Aléatoire : on choisit la page au hasard.
- FIFO : on supprime la donnée qui a été chargée dans la mémoire avant toute les autres.
- LRU : on supprime la donnée qui été lue ou écrite pour la dernière fois avant toute les autres.
- LFU : on vire la page qui est lue ou écrite le moins souvent comparée aux autres.
- etc.
Ces algorithmes ont chacun deux variantes : une locale, et une globale. Avec la version locale, la page qui va être rapatriée sur le disque dur est une page réservée au programme qui est la cause du page miss. Avec la version globale, le système d'exploitation va choisir la page à virer parmi toutes les pages présentes en mémoire vive.
Sur la majorité des systèmes d'exploitation, il est possible d'interdire le déplacement de certaines pages sur le disque dur. Ces pages restent alors en mémoire RAM durant un temps plus ou moins long, parfois en permanence. Cette possibilité simplifie la vie des programmeurs qui conçoivent des systèmes d'exploitation : essayez d'exécuter une interruption de gestion de page miss alors que la page contenant le code de l'interruption est placée sur le disque dur.