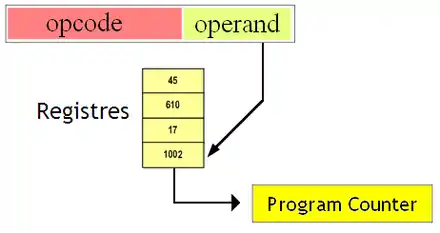
Les instructions sont stockées dans la mémoire sous la forme de suites de bits, tout comme les données. Cette suite de bits n'est pas organisée n'importe comment. Quelques bits de l’instruction indiquent quelle est l'opération à effectuer : est-ce une instruction d'addition, de soustraction, un branchement inconditionnel, un appel de fonction, une lecture en mémoire, etc. Cette portion de mémoire s'appelle l'opcode. Pour la même instruction, l'opcode peut être différent suivant le processeur, ce qui est source d'incompatibilités. Par exemple, les opcodes de l'instruction d'addition ne sont pas les mêmes sur les processeurs x86 (ceux de nos PC) et les anciens macintosh, ou encore les microcontrôleurs. Ce qui fait qu'un opcode de processeur x86 n'aura pas d'équivalent sur un autre processeur, ou correspondra à une instruction totalement différente. De manière générale, on peut dire qu'il existe autant d'opcode que d'instructions pour un processeur. Évidemment, qui dit beaucoup d'opcodes dit processeur plus complexe : les circuits de gestion des opcodes sont naturellement plus complexes quand ces opcodes sont nombreuses. Pour l'anecdote, certains processeurs n'utilisent qu'une seule et unique instruction, et qui peuvent se passer d'opcodes.
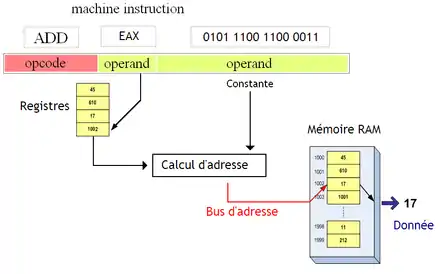
Il arrive que certaines instructions soient composées d'un opcode, sans rien d'autre : elles ont alors une représentation en binaire qui est unique. Mais certaines instructions ajoutent une partie variable, pour préciser la localisation des données à manipuler. Une instruction peut alors fournir au processeur ce qu'on appelle une référence, à savoir quelque chose qui permet de localiser une donnée dans la mémoire. Cette référence pourra ainsi préciser plus ou moins explicitement dans quel registre, à quelle adresse mémoire, à quel endroit sur le disque dur, se situe la donnée à manipuler. Pour les instructions de calcul, ces références peuvent préciser où se situent les opérandes d'un calcul, ou bien préciser où stocker son résultat. Dans le cas d'une instruction d'accès mémoire, elles peuvent préciser ou si situe la donnée à lire ou écrire. Dans le cas des branchements, elle peut donner l'endroit où brancher.
Il faut préciser que toutes les références n'ont pas la même taille : une adresse utilisera plus de bits qu'un nom de registres, par exemple (il y a moins de registres que d'adresses). Et cela retenti sur le nombre de bits d'une instruction, souvent appelée sa taille. Par exemple, une instruction de calcul dont les deux références sont des adresse mémoire prendra plus de place qu'un calcul qui manipule deux registres. En théorie, la taille d'une instruction dépend de la longueur de l'opcode et de la longueur de chaque référence. Mais ce n'est réellement le cas que pour certains processeurs, qui gère des instructions de longueur variable, toutes les instructions n'ayant pas la même taille. Cela permet de gagner un peu de mémoire : avoir des instructions qui font entre 2 et 3 octets est plus avantageux que de tout mettre sur 3 octets. Sur d'autres processeurs, cette longueur est fixe : cela gâche un peu de mémoire, mais permet au processeur de calculer plus facilement l’adresse de l'instruction suivante.
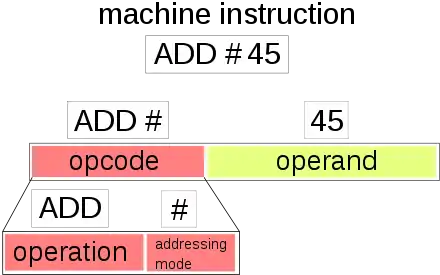
Reste à savoir quelle est la nature de la référence : après tout, c'est une simple suite de bits qui peut représenter une adresse, un nombre, un nom de registre, etc. Chaque manière d’interpréter la partie variable s'appellent un mode d'adressage. Pour résumer, un mode d'adressage indique au processeur que telle référence est une adresse, un registre, autre chose. Il est possible qu'une instruction précise plusieurs références, qui sont chacune soit une adresse, soit une donnée, soit un registre. Par exemple, une addition manipule deux opérandes, ce qui demande d'utiliser une opérande pour chaque (dans le pire des cas). Les instructions manipulant plusieurs références peuvent parfois utiliser un mode d'adressage différent pour chaque. Comme nous allons le voir, certaines instructions supportent certains modes d'adressage et pas d'autres. Généralement, les instructions d'accès mémoire possèdent plus de modes d'adressage que les autres, encore que cela dépende du processeur (chose que nous détaillerons dans le chapitre suivant).
Il existe deux méthodes pour préciser le mode d'adressage utilisé par l'instruction. Dans le premier cas, l'instruction ne gère qu'un mode d'adressage par opérande. Par exemple, toutes les instructions arithmétiques ne peuvent manipuler que des registres. Dans un cas pareil, pas besoin de préciser le mode d'adressage, qui est déduit automatiquement via l'opcode: on parle de mode d'adressage implicite. Dans certains cas, il se peut que plusieurs instructions existent pour faire la même chose, mais avec des modes d'adressages différents. Dans le second cas, les instructions gèrent plusieurs modes d'adressage par opérande. Par exemple, une instruction d'addition peut additionner soit deux registres, soit un registre et une adresse, soit un registre et une constante. Dans un cas pareil, l'instruction doit préciser le mode d'adressage utilisé, au moyen de quelques bits intercalés entre l'opcode et les opérandes. On parle de mode d'adressage explicite. Sur certains processeurs, chaque instruction peut utiliser tous les modes d'adressage supportés par le processeur : on dit que le processeur est orthogonal.
Les modes d'adressages pour les données
Pour comprendre un peu mieux ce qu'est un mode d'adressage, voyons quelques exemples de modes d'adressages assez communs et qui reviennent souvent. Nous allons commencer par aborder l'adressage des données et les modes d'adressages qui correspondent.
L'adressage implicite
Avec l'adressage implicite, la partie variable n'existe pas ! Il peut y avoir plusieurs raisons à cela. Il se peut que l'instruction n'ait pas besoin de données : une instruction de mise en veille de l'ordinateur, par exemple. Ensuite, certaines instructions n'ont pas besoin qu'on leur donne la localisation des données d'entrée et « savent » où sont les données. Comme exemple, on pourrait citer une instruction qui met tous les bits du registre d'état à zéro. Certaines instructions manipulant la pile sont adressées de cette manière : on sait d'avance dans quels registres sont stockées l'adresse de la base ou du sommet de la pile.
L'adressage immédiat
Avec l'adressage immédiat, la partie variable est une constante : un nombre entier, un caractère, un nombre flottant, etc. Avec ce mode d'adressage, la donnée est placée dans la partie variable et est chargée en même temps que l'instruction. Ces constantes sont souvent codées sur 8 ou 16 bits : aller au-delà serait inutile vu que la quasi-totalité des constantes manipulées par des opérations arithmétiques sont très petites et tiennent dans un ou deux octets.

L'adressage direct
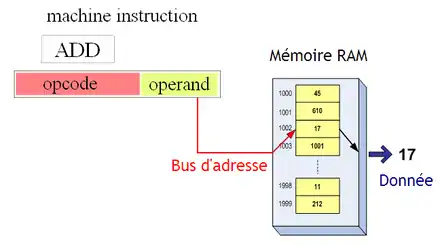
Passons maintenant à l'adressage absolu, aussi appelé adressage direct. Avec lui, la partie variable est l'adresse de la donnée à laquelle accéder. Cela permet de lire une donnée directement depuis la mémoire sans devoir la copier dans un registre.
L'adressage inhérent
Avec le mode d'adressage inhérent, la partie variable va identifier un registre qui contient la donnée voulue.
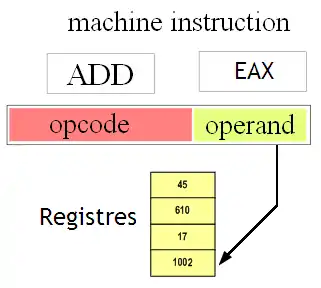
Ce mode d'adressage demande d'attribuer un numéro spécialisé à chaque registre : le nom de registre. Celui-ci sera alors utilisé pour préciser à quel registre le processeur doit accéder. Cela demande d'ajouter un nouveau mode d'adressage, spécialisé pour les registres, afin d'utiliser ces noms de registre : le mode d'adressage inhérent.

L'adressage indirect à registre
Dans certains cas, les registres généraux du processeur peuvent stocker des adresses mémoire. On peut alors décider d'accéder à l'adresse qui est stockée dans un registre : c'est le rôle du mode d'adressage indirect à registre. Ici, la partie variable identifie un registre contenant l'adresse de la donnée voulue. La différence avec le mode d'adressage inhérent vient de ce qu'on fait de ce nom de registre : avec le mode d'adressage inhérent, le registre indiqué dans l'instruction contiendra la donnée à manipuler, alors qu'avec le mode d'adressage indirect à registre, le registre contiendra l'adresse de la donnée.
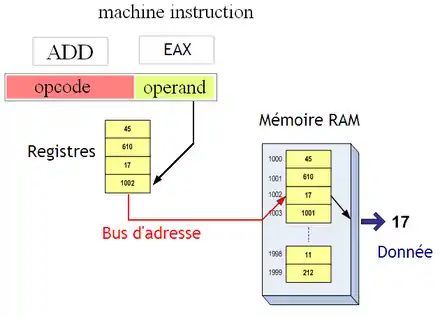
Ce mode d'adressage indirect à registre permet d'implémenter de façon simple ce qu'on appelle les pointeurs. Il s'agit de variables dont le contenu est une adresse mémoire.

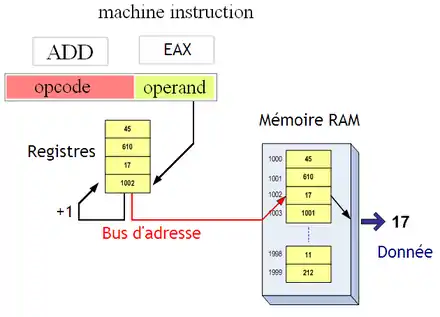
L'adressage indirect à registre avec auto-incrément
Pour faciliter ces parcours de tableaux, on a inventé les modes d'adressages indirect avec auto-incrément (register indirect autoincrement) et indirect avec auto-décrément (register indirect autodecrement), des variantes du mode d'adressage indirect qui augmentent ou diminuent le contenu du registre d'une valeur fixe automatiquement. Cela permet de passer directement à l’élément suivant ou précédent dans un tableau. Il existe une variante où l'incrémentation ou la décrémentation s'effectuent avant l'utilisation effective de l'adresse.
L'adressage indexed absolute
D'autres modes d'adressage permettent de faciliter le calcul de l'adresse d'un élément du tableau. Pour éviter d'avoir à calculer les adresses à la main avec le mode d'adressage indirect à registre, on a inventé un mode d'adressage pour combler ce manque : le mode d'adressage indexed absolute. Celui-ci fournit l'adresse de base du tableau, et un registre qui contient l'indice. À partir de ces deux données, l'adresse de l’élément du tableau est calculée, envoyée sur le bus d'adresse, et l’élément est récupéré.
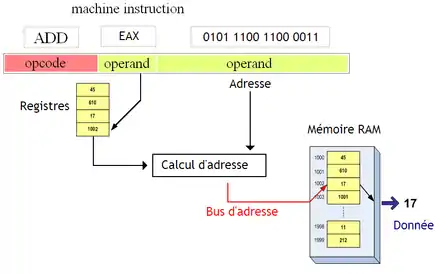
Ce mode d'adressage indexed absolute ne marche que pour des tableaux dont l'adresse est fixée une bonne fois pour toute. Ces tableaux sont assez rares : ils correspondent aux tableaux de taille fixe, déclarée dans la mémoire statique (souvenez-vous de la section précédente).
L'adressage base + index
La majorité des tableaux sont des tableaux dont l'adresse n'est pas connue lors de la création du programme : ils sont déclarés sur la pile ou dans le tas, et leur adresse varie à chaque exécution du programme. On peut certes régler ce problème en utilisant du code automodifiant, mais ce serait vendre son âme au diable ! Pour contourner les limitations du mode d'adressage indexed absolute, on a inventé le mode d'adressage base + index.
Avec ce dernier, l'adresse du début du tableau n'est pas stockée dans l'instruction elle-même, mais dans un registre. Elle peut donc varier autant qu'on veut. Ce mode d'adressage spécifie deux registres dans sa partie variable : un registre qui contient l'adresse de départ du tableau en mémoire, le registre de base, et un qui contient l'indice, le registre d'index. Le processeur calcule alors l'adresse de l’élément voulu à partir du contenu de ces deux registres, et accède à notre élément. En clair : notre instruction ne fait pas que calculer l'adresse de l’élément : elle va aussi le lire ou l'écrire.
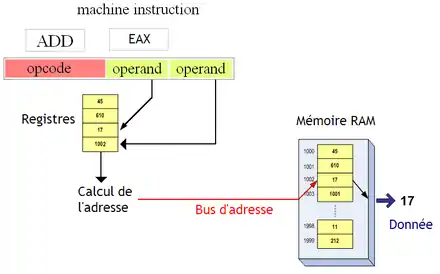
Ce mode d'adressage possède une variante qui permet de vérifier qu'on ne « déborde » pas du tableau, en calculant par erreur une adresse en dehors du tableau, à cause d'un indice erroné, par exemple. Accéder à l’élément 25 d'un tableau de seulement 5 éléments n'a pas de sens et est souvent signe d'une erreur. Pour cela, l'instruction peut prendre deux opérandes supplémentaires (qui peuvent être constants ou placés dans deux registres). L'instruction BOUND sur le jeu d'instruction x86 en est un exemple. Si cette variante n'est pas supportée, on doit faire ces vérifications à la main.
L'adressage base + décalage
Outre les tableaux, les programmeurs utilisent souvent ce qu'on appelle des structures. Ces structures servent à créer des données plus complexes que celles que le processeur peut supporter. Mais le processeur ne peut pas manipuler ces structures : il est obligé de manipuler les données élémentaires qui la constituent une par une. Pour cela, il doit calculer leur adresse, ce qui n'est pas très compliqué. Une donnée a une place prédéterminée dans une structure : elle est donc a une distance fixe du début de celle-ci.
Calculer l'adresse d'un élément de notre structure se fait donc en ajoutant une constante à l'adresse de départ de la structure. Et c'est ce que fait le mode d'adressage base + décalage. Celui-ci spécifie un registre qui contient l'adresse du début de la structure, et une constante. Ce mode d'adressage va non seulement effectuer ce calcul, mais il va aussi aller lire (ou écrire) la donnée adressée.
L'adressage base + index + décalage
Certains processeurs vont encore plus loin : ils sont capables de gérer des tableaux de structures ! Ce genre de prouesse est possible grâce au mode d'adressage base + index + décalage. Avec ce mode d'adressage, on peut calculer l'adresse d'une donnée placée dans un tableau de structure assez simplement : on calcule d'abord l'adresse du début de la structure avec le mode d'adressage base + index, et ensuite on ajoute une constante pour repérer la donnée dans la structure. Et le tout, en un seul mode d'adressage.
Les modes d'adressage pour les branchements
Les instructions de branchement peuvent avoir trois modes d'adressages : direct, relatif ou indirect.
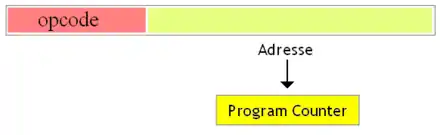
Les branchements directs
Avec un branchement direct, l'opérande est simplement l'adresse de l'instruction à laquelle on souhaite reprendre.
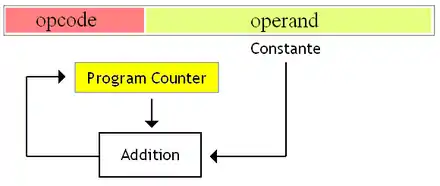
Les branchements relatifs
Les branchements relatifs permettent de localiser la destination d'un branchement par rapport à l'instruction en cours. Cela permet de dire « le branchement est 50 instructions plus loin ». Avec eux, l'opérande est un nombre qu'il faut ajouter au registre d'adresse d'instruction pour tomber sur l'adresse voulue. On appelle ce nombre un décalage (offset).
Les branchements indirects
Avec les branchements indirects, l'adresse vers laquelle on souhaite brancher peut varier au cours de l’exécution du programme. Ces branchements sont souvent camouflés dans des fonctionnalités un peu plus complexes des langages de programmation (pointeurs sur fonction, chargement dynamique de bibliothèque, structure de contrôle switch, et ainsi de suite). Avec ces branchements, l'adresse vers laquelle on veut brancher est stockée dans un registre.