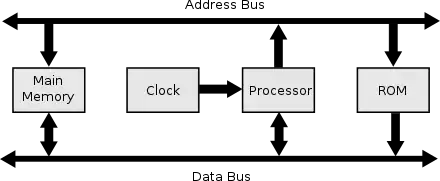
Dans les chapitres précédents, nous avons vu comment représenter de l'information, la traiter et la mémoriser avec des circuits. Mais un ordinateur n'est pas qu'un amoncellement de circuits et est organisé d'une manière bien précise. Il est structuré autour de trois circuits principaux :
- les entrées/sorties, qui permettent à l'ordinateur de communiquer avec l'extérieur ;
- une mémoire qui mémorise les données à manipuler ;
- un processeur, qui manipule l'information et donne un résultat.
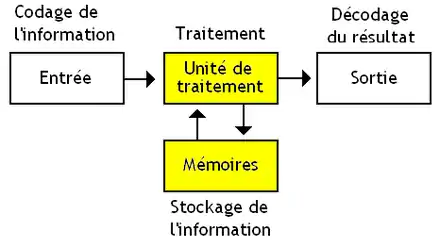
Pour faire simple, le processeur est un circuit qui s'occupe de faire des calculs et de traiter des informations. La mémoire s'occupe purement de la mémorisation des informations. Les entrées-sorties permettent au processeur et à la mémoire de communiquer avec l'extérieur et d'échanger des informations avec des périphériques. Tout ce qui n'appartient pas à la liste du dessus est obligatoirement connecté sur les ports d'entrée-sortie et est appelé périphérique. Ces composants communiquent via un bus, un ensemble de fils électriques qui relie les différents éléments d'un ordinateur.
Parfois, on décide de regrouper la mémoire, les bus, le CPU et les ports d'entrée-sortie dans un seul composant électronique nommé microcontrôleur. Dans certains cas, qui sont plus la règle que l'exception, certains périphériques sont carrément inclus dans le microcontrôleur ! On peut ainsi trouver dans ces microcontrôleurs, des compteurs, des générateurs de signaux, des convertisseurs numériques-analogiques... On trouve des microcontrôleurs dans les disques durs, les baladeurs mp3, dans les automobiles, et tous les systèmes embarqués en général. Nombreux sont les périphériques ou les composants internes à un ordinateur qui contiennent des microcontrôleurs.
Les entrées-sorties
Tous les circuits vus précédemment sont des circuits qui se chargent de traiter des données codées en binaire. Ceci dit, les données ne sortent pas de n'importe où : l'ordinateur contient des composants électroniques qui se chargent de traduire des informations venant de l’extérieur en nombres. Ces composants sont ce qu'on appelle des entrées. Par exemple, le clavier est une entrée : l'électronique du clavier attribue un nombre entier (scancode) à une touche, nombre qui sera communiqué à l’ordinateur lors de l'appui d'une touche. Pareil pour la souris : quand vous bougez la souris, celle-ci envoie des informations sur la position ou le mouvement du curseur, informations qui sont codées sous la forme de nombres. La carte son évoquée il y a quelques chapitres est bien sûr une entrée : elle est capable d'enregistrer un son, et de le restituer sous la forme de nombres.
Si il y a des entrées, on trouve aussi des sorties, des composants électroniques qui transforment des nombres présents dans l'ordinateur en quelque chose d'utile. Ces sorties effectuent la traduction inverse de celle faite par les entrées : si les entrées convertissent une information en nombre, les sorties font l'inverse : là où les entrées encodent, les sorties décodent. Par exemple, un écran LCD est un circuit de sortie : il reçoit des informations, et les transforme en image affichée à l'écran. Même chose pour une imprimante : elle reçoit des documents texte encodés sous forme de nombres, et se permet de les imprimer sur du papier. Et la carte son est aussi une sortie, vu qu'elle transforme les sons d'un fichier audio en tensions destinées à un haut-parleur : c'est à la fois une entrée, et une sortie.
La mémoire
La mémoire est le composant qui mémorise des informations, des données. Bien évidemment, une mémoire ne peut stocker qu'une quantité finie de données. Et à ce petit jeu, certaines mémoires s'en sortent mieux que d'autres et peuvent stocker beaucoup plus de données que les autres. La capacité d'une mémoire correspond à la quantité d'informations que celle-ci peut mémoriser. Plus précisément, il s'agit du nombre de bits que celle-ci peut contenir. Dans la majorité des cas, la mémoire est découpée en plusieurs bytes, des blocs de mémoire qui contiennent chacun un nombre fini et constant de bits. Le plus souvent, ces bytes sont composés de plusieurs groupes de 8 bits, appelés des octets.
L'adressage
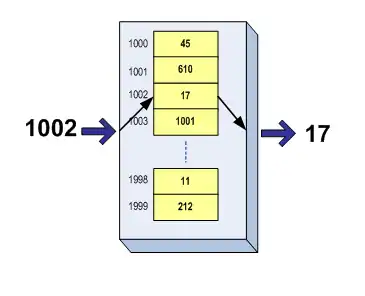
Une mémoire peut être vue comme un rassemblement de "registres" de même taille (qui ont tous une même quantité de bits). Cette description simpliste décrit parfaitement certaines mémoires RWM électroniques, dans le sens où chaque byte correspond bien à un registre dans la mémoire. Cette description est à nuancer quelque peu pour d'autres mémoires RWM et pour les mémoires ROM, qui implémentent leur contenu avec d'autres composants que des bascules.
Quoiqu'il en soit, on ne peut modifier qu'un byte, qu'un registre à la fois : une lecture ou écriture ne peut lire ou modifier qu'un seul byte. Techniquement, le processeur doit préciser à quel byte il veut accéder à chaque lecture/écriture. Pour cela, chaque byte se voit attribuer un nombre binaire unique, l'adresse, qui va permettre de le sélectionner et de l'identifier celle-ci parmi tout les autres. En fait, on peut comparer une adresse à un numéro de téléphone (ou à une adresse d'appartement) : chacun de vos correspondants a un numéro de téléphone et vous savez que pour appeler telle personne, vous devez composer tel numéro. Les adresses mémoires en sont l'équivalent pour les bytes. Il existe des mémoires qui ne fonctionnent pas sur ce principe, mais passons : ce sera pour la suite.
Lecture et écriture : mémoires ROM et RWM
Pour simplifier grandement, on peut grossièrement classer nos mémoire en deux types : les Read Only Memory, et les Read Write Memory. Pour les mémoires ROM (les Read Only Memory), on ne peut pas modifier leur contenu. On peut récupérer une donnée ou une instruction dans notre mémoire : on dit qu'on y accède en lecture. Mais on ne peut pas modifier les données qu'elles contiennent. On utilise de telles mémoires pour stocker des programmes ou pour stocker des données qui ne peuvent pas varier. Par exemple, votre ordinateur contient une mémoire ROM spéciale qu'on appelle le BIOS, qui permet de démarrer votre ordinateur, le configurer à l'allumage, et démarrer votre système d'exploitation. Quant aux mémoires RWM (les Read Write Memory), on peut y accéder en lecture (récupérer une donnée stockée en mémoire), mais aussi en écriture : on peut stocker une donnée dans la mémoire, ou modifier une donnée existante. On trouve forcément au moins une mémoire RWM dans notre ordinateur. Pour l'anecdote, il n'existe pas de Write Only Memory.
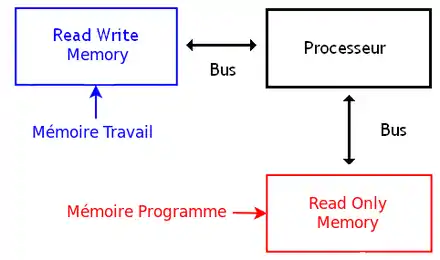
Tout ordinateur contient au moins une mémoire ROM et une mémoire RWM (souvent une RAM). La mémoire ROM stocke un programme, alors que la mémoire RWM sert essentiellement pour maintenir des résultats de calculs.
Mais si tout ordinateur contient au minimum une ROM et une RWM (souvent une mémoire RAM), les deux n'ont pas exactement le même rôle. Sur de nombreux ordinateurs, l'ensemble de la mémoire est séparée en deux gros blocs spécialisés : la mémoire programme et la mémoire travail. Le premier contient le programme à exécuter et parfois les constantes : ce sont des données qui peuvent être lues mais ne sont jamais accédées en écriture durant l'exécution du programme. Elle ne sont donc jamais modifiées et gardent la même valeur quoi qu'il se passe lors de l'exécution du programme. La mémoire travail mémorise les variables du programme à exécuter, qui sont des données que le programme va manipuler. Vu que les variables du programme sont des données qui sont fréquemment mises à jour et modifiées, elles sont naturellement stockées dans une mémoire RWM. Pour ce qui est du programme, c'est autre chose : ceux-ci sont stockés soit totalement en ROM, soit en partie dans la ROM et en partie dans la RWM. C'est notamment le cas sur le PC que vous êtes en train d'utiliser : les programmes sont mémorisés sur le disque dur de votre ordinateur et sont copiés en mémoire RAM à chaque fois que vous les lancez. On peut préciser que le système d'exploitation ne fait pas exception à la règle, vu qu'il est lancé par le BIOS.
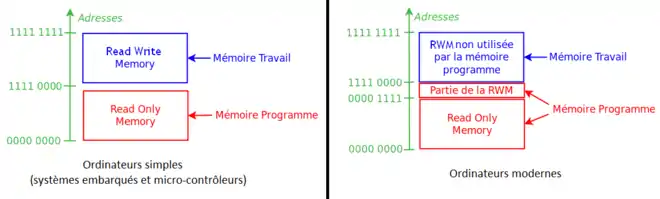
Il y a toujours, dans tous les ordinateurs, une petite mémoire ROM qui contient un programme. Certains ordinateurs très simples s'en contentent. Sur les PC modernes, ce programme est un programme de démarrage nommé le BIOS, qui va charger le système d’exploitation dans la mémoire RWM. Les autres programmes, système d'exploitation compris, sont stockés sur un périphérique dédié au stockage, connecté sur une entrée-sortie : un disque dur, par exemple. Dans ce cas, la mémoire programme n'est pas intégralement stockée dans une ROM, mais l'est en grande partie sur un périphérique. Les programmes sont chargés en mémoire RWM pour être exécutés. L'avantage, c'est qu'on peut modifier le contenu d'un périphérique assez facilement, tandis que ce n'est pas vraiment facile de modifier le contenu d'une ROM (et encore, quand c'est possible). On peut ainsi facilement installer ou supprimer des programmes sur notre périphérique, en rajouter, en modifier, les mettre à jour sans que cela ne pose problème. C'est cette solution qui est utilisée dans nos PC actuels, et la petite mémoire ROM en question s'appelle le BIOS.
La hiérarchie mémoire
Outre leurs capacités respectives, touts les mémoires ne sont pas aussi rapides. La rapidité d'une mémoire se mesure grâce à deux paramètres :
- Le temps de latence correspond au temps qu'il faut pour effectuer une lecture ou une écriture : plus celui-ci est bas, plus la mémoire sera rapide.
- Le débit mémoire correspond à la quantité d'informations qui peut être récupéré ou enregistré en une seconde dans la mémoire : plus celui-ci est élevé, plus la mémoire sera rapide.
La lenteur d'une mémoire dépend de sa capacité : plus la capacité est importante, plus la mémoire est lente. Le fait est que si l'on souhaitait utiliser une seule grosse mémoire dans notre ordinateur, celle-ci serait trop lente et l'ordinateur serait inutilisable. Pour résoudre ce problème, il suffit d'utiliser plusieurs mémoires de taille et de vitesse différentes, qu'on utilise suivant les besoins. Des mémoires très rapides de faible capacité seconderont des mémoires lentes de capacité importante. On peut regrouper ces mémoires en niveaux : toutes les mémoires appartenant à un même niveau ont grosso modo la même vitesse. Pour simplifier, il existe quatre grandes niveaux de hiérarchie mémoire, indiqués dans le tableau ci-dessous.
| Type de mémoire | Temps d'accès | Capacité |
|---|---|---|
| Registres | 1 nanosecondes | Entre 1 et 512 bits |
| Caches | 10 - 100 nanosecondes | Milliers ou millions de bits |
| Mémoire RAM | 1 microsecondes | Milliards de bits |
| Mémoires de masse | 1 millisecondes | Centaines de milliards de bits |
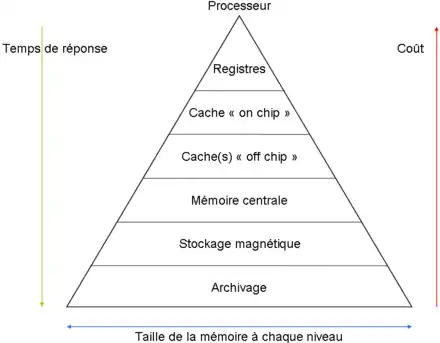
Le but de cette organisation est de placer les données accédées souvent, ou qui ont de bonnes chances d'être accédées dans le futur, dans une mémoire qui soit la plus rapide possible. Le tout est de faire en sorte de placer les données intelligemment, et les répartir correctement dans cette hiérarchie des mémoires. Ce placement se base sur deux principes qu'on appelle les principes de localité spatiale et temporelle :
- un programme a tendance à réutiliser les instructions et données accédées dans le passé : c'est la localité temporelle ;
- et un programme qui s'exécute sur un processeur a tendance à utiliser des instructions et des données consécutives, qui sont proches, c'est la localité spatiale.
On peut exploiter ces deux principes pour placer les données dans la bonne mémoire. Par exemple, si on a accédé à une donnée récemment, il vaut mieux la copier dans une mémoire plus rapide, histoire d'y accéder rapidement les prochaines fois : on profite de la localité temporelle. On peut aussi profiter de la localité spatiale : si on accède à une donnée, autant précharger aussi les données juste à côté, au cas où elles seraient accédées. Ce placement des données dans la bonne mémoire peut être géré par le matériel de notre ordinateur, mais aussi par le programmeur.
Les mémoires de masse
Les mémoires de masse servent à stocker de façon permanente des données ou des programmes qui ne doivent pas être effacés (on dit qu'il s'agit de mémoires non-volatiles). Les mémoires de masse servent toujours à stocker de grosses quantités de données: elles ont une capacité énorme comparée aux autres types de mémoires, et sont donc très lentes. Parmi ces mémoires de masse, on trouve notamment :
- les mémoires magnétiques, comme disques durs ou les fameuses disquettes (totalement obsolètes de nos jours) ;
- les mémoires électroniques, comme les mémoires Flash utilisées dans les clés USB et disques durs SSD ;
- les disques optiques, comme les CD-ROM, DVD-ROM, et autres CD du genre ;
- mais aussi quelques mémoires très anciennes et rarement utilisées de nos jours, comme les rubans perforés et quelques autres.
La mémoire principale
La mémoire principale est appelée, par abus de langage, la mémoire RAM. Il s'agit d'une mémoire qui stocke temporairement des données que le processeur doit manipuler (on dit qu'elle est volatile). Elle sert donc essentiellement pour maintenir des résultats de calculs, contenir temporairement des programmes à exécuter, etc. Avec cette mémoire, chaque donnée ou information stockée se voit attribuer un nombre binaire unique, l'adresse mémoire, qui va permettre de la sélectionner et de l'identifier parmi toutes les autres. On peut comparer une adresse à un numéro de téléphone ou à une adresse d'appartement : chaque correspondant a un numéro de téléphone et vous savez que pour appeler telle personne, vous devez composer tel numéro. Les adresses mémoires, c'est pareil, mais avec des données.
Les caches et local stores
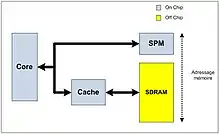
Le troisième niveau est intermédiaire entre les registres et la mémoire principale. Il regroupe deux types distincts de mémoires : les mémoires caches (du moins, certains caches) et les local stores.
Dans la majorité des cas, la mémoire intercalée entre les registres et la mémoire RAM/ROM est ce qu'on appelle une mémoire cache. Celle-ci a quelques particularités qui la rendent vraiment différente d'une mémoire RAM ou ROM. Premièrement, et aussi bizarre que cela puisse paraître, elle n'est jamais adressable ! Le contenu du cache est géré par un circuit qui s'occupe des échanges avec les registres et la mémoire principale : le programmeur ne peut pas gérer directement ce cache. Si cela peut paraitre contre-intuitif, tout s'éclairera dans le chapitre dédié à ces mémoires. De nos jours, ce cache est intégré dans le processeur. Dans le détail, le cache contient une copie de certaines données présentes en RAM. La copie présente dans le cache est accessible bien plus rapidement que celle en RAM, le cache étant beaucoup plus rapide que la RAM. Mais seule une faible partie de ces données sont présentes dans le cache, les autres données devant être lues ou écrites dans la RAM. Tout accès mémoire provenant du processeur est intercepté par le cache, qui vérifie si la donnée demandée est présente ou non dans le cache. Si c'est le cas, la donnée voulue est présente dans le cache : on a un succès de cache (cache hit) et on accède à la donnée depuis le cache. Sinon, c'est un défaut de cache (cache miss) : on est obligé d’accéder à la RAM ou de recopier notre donnée de la RAM dans le cache.
Sur certains processeurs, les mémoires caches sont remplacées par des mémoires RAM appelées des local stores. Ce sont des mémoires RAM, identiques à la mémoire RAM principale, mais qui sont plus petites et plus rapides. Contrairement aux mémoires caches, il s'agit de mémoires adressables, ce qui fait qu'elles ne sont plus gérées automatiquement par le processeur : c'est le programme en cours d'exécution qui prend en charge les transferts de données entre local store et mémoire RAM. Ces local stores consomment moins d'énergie que les caches à taille équivalente : en effet, ceux-ci n'ont pas besoin de circuits compliqués pour les gérer automatiquement, contrairement aux caches. Côté inconvénients, ces local stores peuvent entraîner des problèmes de compatibilité : un programme conçu pour fonctionner avec des local stores ne fonctionnera pas sur un ordinateur qui en est dépourvu.
Les registres du processeur
Enfin, le dernier niveau de hiérarchie mémoire est celui des registres, de petites mémoires très rapides et de faible capacité. Celles-ci sont intégrées à l'intérieur du processeur. La capacité des registres dépend fortement du processeur. Au tout début de l'informatique, il n'était pas rare de voir des registres de 3, 4, voire 8 bits. Par la suite, la taille de ces registres a augmenté, passant rapidement de 16 à 32 bits, voire 48 bits sur certaines processeurs spécialisés. De nos jours, les processeurs de nos PC utilisent des registres de 64 bits. Il existe toujours des processeurs de faible performance qui utilisent des registres relativement petits, de 8 à 16 bits.
Certains processeurs disposent de registres spécialisés, dont la fonction est prédéterminée une bonne fois pour toutes : un registre est conçu pour stocker, uniquement des nombres entiers, ou seulement des flottants, quand d'autres sont spécialement dédiés aux adresses mémoires. Par exemple, les processeurs présents dans nos PC séparent les registres entiers des registres flottants. Pour plus de flexibilité, certains processeurs remplacent les registres spécialisés par des registres généraux, utilisables pour tout et n'importe quoi. Pour reprendre notre exemple du dessus, un processeur peut fournir 12 registres généraux, qui peuvent stocker 12 entiers, ou 10 entiers et 2 flottants, ou 7 adresses et 5 entiers, etc. Dans la réalité, les processeurs utilisent à la fois des registres généraux et quelques registres spécialisés.
Le processeur
L'unité de traitement est un circuit qui s'occupe de faire des calculs et de manipuler l'information provenant des entrées-sorties ou récupérée dans la mémoire. Dans les ordinateurs, l'unité de traitement porte le nom de processeur, ou encore de Central Processing Unit, abrévié en CPU. Tout processeur est conçu pour effectuer un nombre limité d'opérations bien précises, comme des calculs, des échanges de données avec la mémoire, etc. Ces opérations sont appelées des instructions. Elles se classent en quelques grands types très simples :
- Les instructions arithmétiques font des calculs. Un ordinateur peut ainsi additionner deux nombres, les soustraire, les multiplier, les diviser, etc.
- Les instructions de test comparent deux nombres entre eux et agissent en fonction.
- Les instructions d'accès mémoire échangent des données entre la mémoire et le processeur.
- Les instructions d'entrée-sortie communiquent avec les périphériques.
- Etc.
Les logiciels et programmes
Tout processeur est conçu pour exécuter une suite d'instructions dans l'ordre demandé, cette suite s'appelant un programme. Ce que fait le processeur est défini par la suite d'instructions qu'il exécute, par le programme qu'on lui demande de faire. La totalité des logiciels présents sur un ordinateur sont des programmes comme les autres. Ce programme est stocké dans la mémoire de l'ordinateur, comme les données : sous la forme de suites de bits dans notre mémoire. Le programme est donc dans une mémoire, volatile, de type RWM, qui est donc modifiable à loisir. C'est ainsi que notre ordinateur est rendu programmable : on peut parfaitement modifier le contenu de la mémoire (ou la changer, au pire), et donc changer le programme exécuté par notre ordinateur. Mine de rien, cette idée d'automate stockant son programme en mémoire est ce qui a fait que l’informatique est ce qu'elle est aujourd’hui. C'est la définition même d'ordinateur : appareil programmable qui stocke son programme dans une mémoire modifiable.
En théorie, il est impossible de faire la différence entre donnée et instruction. Il arrive assez rarement que le processeur charge et exécute des données, qu'il prend par erreur pour des instructions, mais cela est rare. Cela peut même être un effet recherché : par exemple, on peut créer des programmes qui modifient leurs propres instructions : cela s'appelle du code auto-modifiant. Ce genre de choses servait autrefois à écrire certains programmes sur des ordinateurs rudimentaires (pour gérer des tableaux et autres fonctionnalités de base utilisées par les programmeurs), pouvait aussi permettre de rendre nos programmes plus rapides, servait à compresser un programme, ou pire : permettait de cacher un programme et le rendre indétectable dans la mémoire (les virus informatiques utilisent beaucoup ce genre de procédés). Mais passons ! Ce qu'il faut retenir est que le fait que le programme soit stocké comme les données est ce qui permet à l'ordinateur d'être reprogrammable, et non simplement reconfigurable.
Le Program Counter
Pour exécuter une suite d'instructions dans le bon ordre, le processeur détermine à chaque cycle savoir quelle est la prochaine instruction à exécuter. Il faut donc que notre processeur se souvienne de cette information quelque part, dans une petite mémoire. C'est le rôle du registre d'adresse d'instruction, aussi appelé Program Counter. Ce registre stocke l'adresse de la prochaine instruction à exécuter, adresse qui permet de localiser la prochaine instruction en mémoire. Cette adresse ne sort pas de nulle part : on peut la déduire de l'adresse de l'instruction en cours d’exécution par divers moyens plus ou moins simples qu'on verra dans la suite de ce tutoriel. Généralement, on profite du fait que ces instructions sont exécutées dans un ordre bien précis, les unes après les autres. Sur la grosse majorité des ordinateur, celles-ci sont placées les unes à la suite des autres dans l'ordre où elles doivent être exécutées. L'ordre en question est décidé par le programmeur. Un programme informatique n'est donc qu'une vulgaire suite d'instructions stockée quelque part dans la mémoire de notre ordinateur. En faisant ainsi, on peut calculer facilement l'adresse de la prochaine instruction en ajoutant la longueur de l'instruction juste chargée (le nombre de case mémoire qu'elle occupe) au contenu du registre d'adresse d'instruction. Dans ce cas, l'adresse de la prochaine instruction est calculée par un petit circuit combinatoire couplé à notre registre d'adresse d'instruction, qu'on appelle le compteur ordinal.
Mais certains processeurs n'utilisent pas cette méthode. Sur de tels processeurs, chaque instruction va devoir préciser quelle est la prochaine instruction. Pour ce faire, une partie de la suite de bit représentant notre instruction à exécuter va stocker cette adresse. Dans ce cas, ces processeurs utilisent toujours un registre pour stocker cette adresse, mais ne possèdent pas de compteur ordinal, et n'ont pas besoin de calculer une adresse qui leur est fournie sur un plateau. Les processeurs de ce type contiennent toujours un registre d'adresse d'instruction : la partie de l'instruction stockant l'adresse de la prochaine instruction est alors recopiée dans ce registre, pour faciliter sa copie sur le bus d'adresse. Mais le compteur ordinal n'existe pas. Sur des processeurs aussi bizarres, pas besoin de stocker les instructions en mémoire dans l'ordre dans lesquelles elles sont censées être exécutées. Mais ces processeurs sont très très rares et peuvent être considérés comme des exceptions qui confirment la règle.
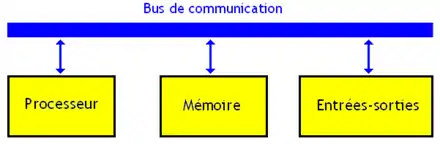
Le bus de communication
Le processeur est relié à la mémoire ainsi qu'aux entrées-sorties par un ou plusieurs bus de communication. Ce bus n'est rien d'autre qu'un ensemble de fils électriques sur lesquels on envoie des zéros ou des uns.
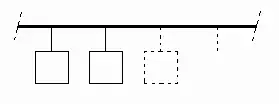
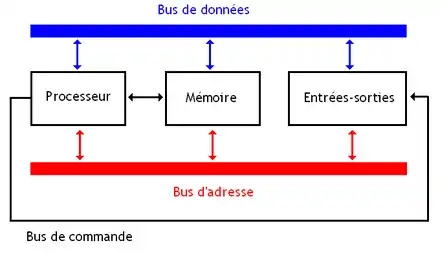
Tout ordinateur contient au moins un bus, qui relie le processeur, la mémoire, les entrées et les sorties ; et leur permet d’échanger des données ou des instructions. Pour permettre au processeur (ou aux périphériques) de communiquer avec la mémoire, il y a trois prérequis que ce bus doit respecter : pouvoir sélectionner la case mémoire (ou l'entrée-sortie) dont on a besoin, préciser à la mémoire s'il s'agit d'une lecture ou d'une écriture, et enfin pouvoir transférer la donnée. Pour cela, on doit donc avoir trois bus spécialisés, bien distincts, qu'on nommera le bus de commande, le bus d'adresse, et le bus de donnée. Le bus de données est un ensemble de fils par lequel s'échangent les données entre les composants. Le bus de commande permet au processeur de configurer la mémoire et les entrées-sorties. Le bus d'adresse, facultatif, permet au processeur de sélectionner l'entrée, la sortie ou la portion de mémoire avec qui il veut échanger des données. Chaque composant possède des entrées séparées pour le bus d'adresse, le bus de commande et le bus de données. Par exemple, une mémoire RAM possédera des entrées sur lesquelles brancher le bus d'adresse, d'autres sur lesquelles brancher le bus de commande, et des broches d'entrée-sortie pour le bus de données.
Il faut noter que certaines architectures utilisent plusieurs bus. Cela vient du fait que les périphériques peuvent être nombreux et avoir chacun droit à des bus dédiés. Mais une autre raison est la présence d'au moins deux mémoires : une ROM et une ou plusieurs RWM/RAM.
L'architecture Von Neumann
Si ces deux mémoires sont reliées au processeur par un bus unique, on a une architecture Von Neumann. Avec l'architecture Von Neumann, tout se passe comme si les deux mémoires étaient fusionnées en une seule mémoire. Une adresse bien précise va ainsi correspondre soit à la mémoire RAM, soit à la mémoire ROM, mais pas aux deux.
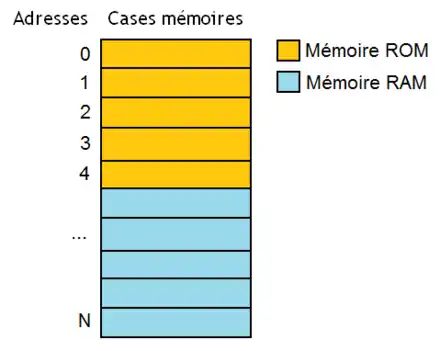
Quand une adresse est envoyée sur le bus, les deux mémoires vont la recevoir mais une seule va répondre.
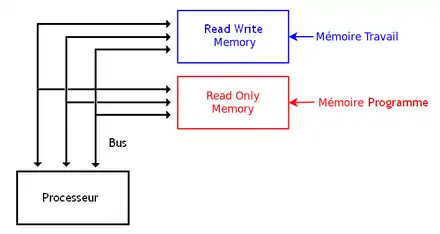
L'architecture Harvard
Si ces deux mémoires sont reliées au processeur par deux bus séparés, on a une architecture Harvard. L'avantage de cette architecture est qu'elle permet de charger une instruction et une donnée simultanément : une instruction chargée sur le bus relié à la mémoire programme, et une donnée chargée sur le bus relié à la mémoire de données.
Sur ces architectures, une adresse peut correspondre soit à la ROM, soit à la RAM : le processeur voit bien deux mémoires séparées.