Une limite à une utilisation efficiente du pipeline tient dans l'existence de dépendances entre instructions. Deux instructions ont une dépendance quand elles manipulent la même ressource : le même registre, la même unité de calcul, la même adresse mémoire. Il existe divers types de dépendances, appelées dépendances structurales, de contrôle et de données. Dans ce chapitre, nous allons nous concentrer sur les dépendances de données. Deux instructions ont une dépendance de données quand elles accèdent (en lecture ou écriture) au même registre ou à la même adresse mémoire. Différents cas se présentent alors :
- Read after read : Deux instructions lisent la même donnée, mais pas en même temps.
- Read after write : La première instruction va écrire son résultat dans un registre ou dans la RAM, et un peu plus tard, la seconde va lire ce résultat et effectuer une opération dessus. La seconde instruction va donc manipuler le résultat de la première.
- Write after read : La première instruction va lire un registre ou le contenu d'une adresse en RAM, et la seconde va écrire son résultat au même endroit un peu plus tard.
- Write after write : Nos deux instructions effectuent des écritures au même endroit : registre ou adresse mémoire.
Pour les dépendances Read after read, on peut mettre les deux instructions dans n'importe quel ordre, cela ne pose aucun problème. Ce ne sont pas de vraies dépendances et je les présente par pur souci d'exhaustivité. Par contre, ce n'est pas le cas avec les trois autres types de dépendances, qui imposent d’exécuter la première instruction avant la seconde. Cela fait que le processeur ou le compilateur doit conserver l'ordre des instructions et ne pas réordonnancer. De plus, la première instruction doit avoir terminé son accès mémoire avant que l'autre ne commence le sien. Et cette contrainte n'est pas forcément respectée avec un pipeline, dont le principe même est de démarrer l’exécution d'une instruction sans attendre que la précédente soit terminée. Dans ces conditions, l'ordre de démarrage des instructions est respecté, mais pas l'ordre des accès mémoire. Reste que les dépendances ne posent problèmes en termes d'accès mémoires que dans certains cas bien précis.
- Les dépendances Read after write apparaissent quand une instruction a besoin du résultat de la précédente alors que celui-ci n'est disponible qu'après avoir été enregistré dans un registre, soit après l'étape d’enregistrement. Si on ne fait rien, la seconde instruction ne lira pas le résultat de la première, mais l'ancienne valeur, encore présente dans le registre.
- Les dépendances WAR n'apparaissent que sur les pipelines où l'écriture des résultats a lieu assez tôt (vers le début du pipeline), et les lectures assez tard (vers la fin du pipeline).
- Les dépendances WAW n'apparaissent que si le pipeline autorise les instructions sur plusieurs cycles d’horloge ou les écritures qui prennent plusieurs étages.
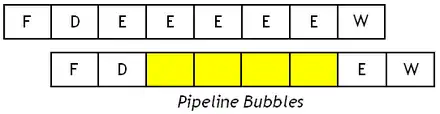
Les bulles de pipeline
Pour éviter tout problème avec ces dépendances, on est obligé d'insérer des instructions qui ne font rien entre les deux instructions dépendantes. Mais insérer ces instructions nécessite de connaitre le fonctionnement du pipeline en détail : niveau portabilité, c'est pas la joie !
Il est possible de déléguer cet ajout de NOP au processeur, à ses unités de décodage. Si une dépendance de données est détectée, l'unité de décodage d'instruction met l'instruction en attente tant que la dépendance n'est pas résolue. Durant ce temps d'attente, on insère des vides dans le pipeline : certains étages seront inoccupés et n'auront rien à faire. Ces vides sont appelés des calages (stall), ou bulles de pipeline (pipeline bubble). Lors de cette attente, les étages qui précédent l'unité de décodage sont bloqués en empêchant l'horloge d'arriver aux étages antérieurs au décodage.
C'est un nouvel étage, l'étage d'émission (issue), qui détecte les dépendances et rajoute des calages si besoin. Pour détecter les dépendances, il compare les registres utilisés par l'instruction à émettre et ceux utilisés par les instructions dans le pipeline. Il n'y a pas de dépendance si ces registres sont différents, alors qu'il y a dépendance dans le cas contraire. L'unité d'émission est donc un paquet de comparateurs reliés par des portes OU. En sortie, elle fournit un signal STALL, qui indique s'il faut caler ou non.
L'unité d'émission doit connaitre les registres de destination des instructions dans le pipeline, ainsi que les registres utilisés par l'instruction à émettre. Obtenir les registres de destination des instructions dans le pipeline peut se faire de deux manières. La première méthode utilise le fait que les noms de registres sont propagés dans le pipeline, comme tous les signaux de commande. Dans ces conditions, rien n’empêche de relier les registres tampons chargés de la propagation à l'unité d'émission.
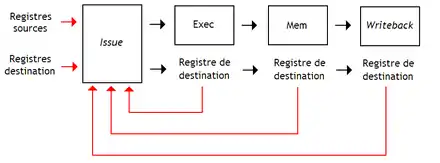
Avec la seconde possibilité, l'unité d'émission mémorise ces registres dans une petite mémoire : le scoreboard. C'est une mémoire dont les mots mémoire font un bit : chaque adresse correspond à un nom de registre, et le bit correspondant à cet adresse indique si le registre est réservé par une instruction en cours d'exécution dans le pipeline. Lors de l'émission, le scoreboard est adressé avec les noms des registres source et destination utilisés dans l’instruction, pour vérifier les bits associés. Le scoreboard est mis à jour lorsqu'une instruction écrit son résultat dans un registre, à l'étape d’enregistrement : le scoreboard met le bit correspondant à zéro.
Le contournement et le réacheminement
Pour diminuer l'effet des dépendances RAW, on peut faire en sorte que le résultat d'une instruction soit disponible rapidement. Avec la technique du contournement (bypass), le résultat est utilisable en sortie de l'unité de calcul, avant d'être enregistré dans les registres.
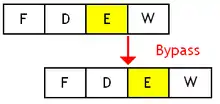
L'implémentation du contournement
Implémenter la technique du contournement demande de relier la sortie de l'unité de calcul sur son entrée en cas de dépendances, et à la déconnecter sinon : cela se fait avec un multiplexeur. Pour détecter les dépendances, il faut comparer le registre destination avec le registre source en entrée : si ce registre est identique, on devra faire commuter le multiplexeur pour relier la sortie de l'unité de calcul.
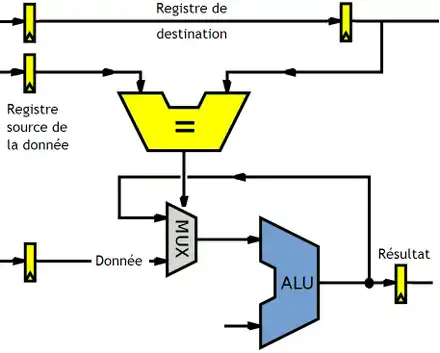
Pour améliorer un peu les performances du système de contournement, certains processeurs ajoutent un petit cache en sortie des unités de calcul : le cache de contournement (bypass cache). Celui-ci mémorise les n derniers résultats produits par l’unité de calcul. Le tag de chaque ligne de ce cache est le nom du registre du résultat.
Le contournement sur les processeurs avec beaucoup d'unités de calcul
Avec le contournement, la sortie d'une unité de calcul doit être reliée aux entrées de toutes les autres, avec les comparateurs qui vont avec ! Sur les processeurs ayant plusieurs d'unités de calculs, cela demande beaucoup de circuits. Pour limiter la casse, on ne relie pas toutes les unités de calcul ensemble. À la place, on préfère regrouper ces unités de calcul dans différents blocs séparés qu'on appelle des agglomérats (cluster). Le contournement est alors rendu possible entre les unités d'un même agglomérat, mais pas entre agglomérats différents. Cette agglomération peut aussi prendre en compte les interconnections entre unités de calcul et registres. C'est à dire que les registres peuvent être agglomérés. Et cela peut se faire de plusieurs façons différentes.
Une première solution, déjà vue dans les chapitres sur la micro-architecture d'un processeur, consiste à découper le banc de registres en plusieurs bancs de registres plus petits. Il faut juste prévoir un réseau d'interconnexions pour échanger des données entre bancs de registres. Dans la plupart des cas, cette séparation est invisible du point de vue de l'assembleur et du langage machine. Le processeur se charge de transférer les données entre bancs de registres suivant les besoins. Sur d'autres processeurs, les transferts de données se font via une instruction spéciale, souvent appelée COPY.
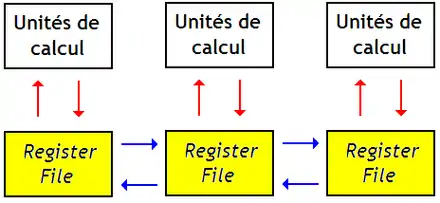
Sur d'autres processeurs, on utilise une hiérarchie de registres : d'un côté, une couche de bancs de registres reliés aux ALU, de l'autre, un banc de registres qui sert à échanger des données entre les bancs de registres.
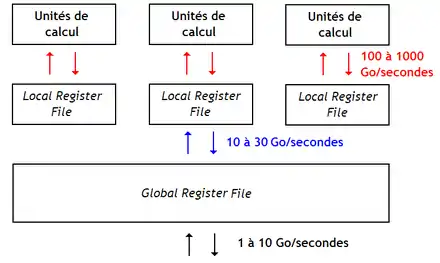
Certains chercheurs ont adapté cette hiérarchie de bancs de registres de façon à ce que les bancs de registres reliés aux unités de calcul se comportent comme des caches. Suivant l’implémentation, les écritures et lecture en mémoire peuvent lire ou écrire dans tous les niveaux de cache, ou uniquement dans le niveau de banc de registres le plus proche de la mémoire. Il faut noter que le préchargement est possible entre bancs de registres. Dans d'autres travaux, on préfère y stocker les résultats qui ne sont pas utilisés après un contournement : ces valeurs sont écrites dans tous les niveaux de la hiérarchie des registres, tandis que les valeurs contournées sont écrites uniquement dans les registres des niveaux inférieurs.
Sur de nombreux processeurs, un branchement est exécuté par une unité de calcul spécialisée. Or les registres à lire pour déterminer l'adresse de destination du branchement ne sont pas forcément dans le même agglomérat que cette unité de calcul. Pour éviter cela, certains processeurs disposent d'une unité de calcul des branchements dans chaque agglomérat. Dans les cas où plusieurs unités veulent modifier le program counter en même temps, un système de contrôle général décide quelle unité a la priorité sur les autres. Mais d'autres processeurs fonctionnent autrement : seul un agglomérat possède une unité de branchement, qui peut recevoir des résultats de tests de toutes les autres unités de calcul, quel que soit l’agglomérat.