Les branchements ont des effets similaires aux exceptions et interruptions. Lorsqu'on charge un branchement dans le pipeline, l'adresse à laquelle brancher sera connue après quelques cycles et des instructions seront chargées durant ce temps. Pour éviter tout problème, on doit faire en sorte que ces instructions ne modifient pas les registres du processeur ou qu'elles ne lancent pas d'écritures en mémoire. La solution la plus simple consiste à inclure des instructions qui ne font rien à la suite du branchement : c'est ce qu'on appelle un délai de branchement. Le processeur chargera ces instructions, jusqu’à ce que l'adresse à laquelle brancher soit connue. Cette technique a les mêmes inconvénients que ceux vus dans le chapitre précédents. Pour éviter cela, on peut réutiliser les techniques vues dans les chapitres précédents, avec quelques améliorations.
Les instructions à prédicat
Une première solution est de remplacer les branchements par d’autres instructions. Cela marche bien pour certains calculs comme la valeur absolue, le maximum de deux nombres, etc. Pour cela, les concepteurs de processeurs ont créé des instructions à prédicat. Ce sont des instructions qui ne font quelque chose que si une condition est respectée, et se comportent comme un NOP (une instruction qui ne fait rien) sinon. Elles sont précédées par une instruction de test, qui vérifier la condition en question. Elles permettent de créer de petites structures de contrôle, sans branchement, contenant peu d'instructions.
Certains processeurs fournissent des instructions à prédicats en plus d'instructions normales : on dit qu'ils implémentent la prédication partielle. Certains d'entre eux ne disposent que d'une seule instruction à prédicat : CMOV, qui copie un registre dans un autre si une condition est remplie. Sur d'autres processeurs, toutes les instructions sont des instructions à prédicat : on parle de prédication totale.
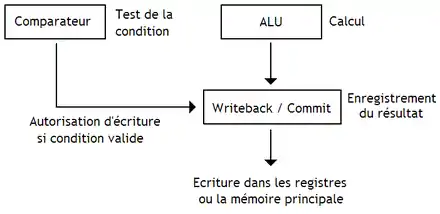
Implémenter ces instructions peut être fait de plusieurs manières, la première n’exécutant pas l'instruction si la condition est invalide, l'autre l’exécutant en avance quitte à l'annuler si la condition se révèle ultérieurement invalide. La première implémentation n'envoie pas l’instruction aux ALU si la condition n'est pas valide. Le résultat de la comparaison doit être connu avant l'envoi aux ALU du calcul,ce qui fait que le calcul est mis en attente tant que le résultat de la comparaison n'est pas disponible. Cette solution est peu pratique, ce qui fait que la seconde méthode est toujours privilégiée. La seconde méthode empêche l'enregistrement du résultat dans les registres ou la mémoire. La comparaison est faite en parallèle du calcul.
La prédiction de branchement
Pour éviter les délais de branchement, les concepteurs de processeurs ont inventé l’exécution spéculative de branchement, qui consiste à deviner l'adresse de destination du branchement et l’exécuter avant que celle-ci ne soit connue. Cela demande de résoudre trois problèmes :
- reconnaitre les branchements ;
- savoir si un branchement sera exécuté ou non : c'est la prédiction de branchement ;
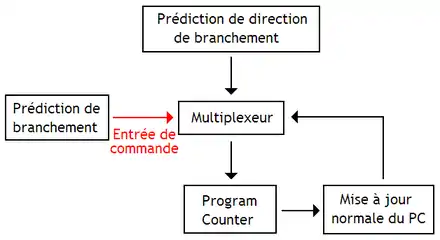
- dans le cas où un branchement serait exécuté, il faut aussi savoir quelle est l'adresse de destination : c'est la prédiction de direction de branchement.
Pour résoudre le second problème, le processeur contient un circuit qui déterminer si le branchement est pris (on doit brancher vers l'adresse de destination) ou non pris (on poursuit l’exécution du programme immédiatement après le branchement) : c'est l'unité de prédiction de branchement. La prédiction de direction de branchement est elle aussi déléguée à un circuit spécialisé : l’unité de prédiction de direction de branchement. C'est l'unité de prédiction de branchement qui autorise l'unité de prédiction de destination de branchement à modifier le program counter. Dans certains processeurs, les deux unités sont regroupées dans le même circuit.
La correction des erreurs de prédiction
Le processeur peut parfaitement se tromper en faisant ses prédictions, ce qui charge des instructions par erreur dans le pipeline. Dans ce cas, on parle d'erreur de prédiction. Pour corriger les erreurs de prédictions, il faut d'abord les détecter. Pour cela, on rajoute un circuit dans le processeur : l’unité de vérification de branchement (branch verification unit). Elle compare l'adresse de destination prédite et celle calculée en exécutant le branchement. Pour cela, l'adresse prédite doit être propagée dans le pipeline jusqu’à ce que l'adresse de destination du branchement soit calculée.
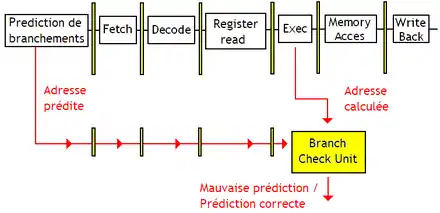
Une fois la mauvaise prédiction détectée, il faut corriger le program counter immédiatement. En effet, si il y a eu erreur de prédiction, le program counter n'a pas été mis à jour correctement, et il faut faire reprendre le processeur au bon endroit. Pour implémenter cette correction du program counter, il suffit d'utiliser un circuit qui restaure le program counter s'il y a eu erreur de prédiction. La gestion des mauvaises prédictions dépend fortement du processeur. Certains processeurs peuvent reprendre l’exécution du programme immédiatement après avoir détecté la mauvaise prédiction (ils sont capables de supprimer les instructions qui n'auraient pas dû être exécutées), tandis que d'autres attendent que les instructions chargées par erreur terminent avant de corriger le program counter.
Second point : il faut que le pipeline soit vidé des instructions chargées par erreur. Tant que ces instructions ne sont pas sorties du pipeline, on doit attendre sans charger d'instructions dans le pipeline. Le temps d'attente nécessaire pour vider le pipeline est égal à son nombre d'étages. En effet, la dernière instruction à être chargée dans le pipeline le sera durant l'étape à laquelle on détecte l'erreur de prédiction. Il faudra attendre que cette instruction quitte le pipeline, et donc qu'elle traverse tous les étages. De plus, il faut remettre le pipeline dans l'état qu'il avait avant le chargement du branchement. Tout se passe lors de la dernière étape d'enregistrement des résultats en mémoire ou dans les registres. Et pour cela, on réutilise les techniques vues dans le chapitre précédent pour la gestion des exceptions et interruptions.
En utilisant une technique du nom de minimal control dependency, seules les instructions qui dépendent du résultat du branchement sont supprimées du pipeline en cas de mauvaise prédiction, les autres n'étant pas annulées. Sans minimal control dependency, toutes les instructions qui suivent un branchement dans notre pipeline sont annulées. Mais pourtant, certaines d'entre elles pourraient être utiles. Prenons un exemple : supposons que l'on dispose d'un processeur de 31 étages (un Pentium 4 par exemple). Supposons que l'adresse du branchement est connue au 9éme étage. On fait face à un branchement qui envoie le processeur seulement 6 instructions plus loin. Si toutes les instructions qui suivent le branchement sont supprimées, les instructions en rouge sont celles qui sont chargées incorrectement. On remarque pourtant que certaines instructions chargées sont potentiellement correctes : celles qui suivent le point d'arrivée du branchement. Elles ne le sont pas forcément : il se peut qu'elles aient des dépendances avec les instructions supprimées. Mais si elles n'en ont pas, alors ces instructions auraient du être exécutées. Il serait donc plus efficace de les laisser enregistrer leurs résultats au lieu de les ré-exécuter à l’identique un peu plus tard. Ce genre de choses est possible sur les processeurs qui implémentent une technique du nom de Minimal Control Dependancy. En gros, cette technique fait en sorte que seules les instructions qui dépendent du résultat du branchement soient supprimées du pipeline en cas de mauvaise prédiction.
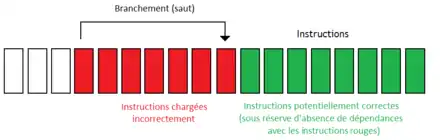
La reconnaissance des branchements
Pour prédire des branchements, le processeur doit faire la différence entre branchements et autres instructions, dès l'étage de chargement. Or, un processeur « normal », sans prédiction de branchement, ne peut faire cette différence qu'à l'étage de décodage, et pas avant. Les chercheurs ont donc du trouver une solution.
La première solution se base sur les techniques de prédécodage vues dans le chapitre sur le cache. Pour rappel, ce prédécodage consiste à décoder partiellement les instructions lors de leur chargement dans le cache d'instructions et à mémoriser des informations utiles dans la ligne de cache. Dans le cas des branchements, les circuits de prédécodage peuvent identifier les branchements et mémoriser cette information dans la ligne de cache.
Une autre solution consiste à mémoriser les branchements déjà rencontrés dans un cache intégré dans l'unité de chargement ou de prédiction de branchement. Ce cache mémorise l'adresse (le program counter) des branchements déjà rencontrés : il appelé le tampon d’adresse de branchement (branch adress buffer). À chaque cycle d'horloge, l'unité de chargement envoie le program counter en entrée du cache. Si il n'y a pas de défaut de cache, l'instruction à charger est un branchement déjà rencontré : on peut alors effectuer la prédiction de branchement. Dans le cas contraire, la prédiction de branchement n'est pas utilisée, et l'instruction est chargée normalement.
La prédiction de direction de branchement
La prédiction de direction de branchement détermine l'adresse de destination d'un branchement. Il faut faire la différence entre un branchement direct, pour lequel l'adresse de destination est toujours la même, et un branchement indirect, pour lequel l'adresse de destination est variable durant l’exécution du programme. Les branchements directs sont plus facilement prévisibles : l'adresse vers laquelle il faut brancher est toujours la même. Pour les branchements indirects, vu que cette adresse change, la prédire celle-ci est particulièrement compliqué (quand c'est possible).
Lorsqu'un branchement est exécuté, on peut se souvenir de l'adresse de destination et la réutiliser lors d'exécutions ultérieures du branchement. Cette technique marche à la perfection pour les branchements directs, mais pas pour les branchements indirects. Pour se souvenir de l'adresse de destination, on a besoin d'un cache qui mémorise les correspondances entre l'adresse du branchement et l'adresse de destination; ce cache est appelé le tampon de destination de branchement (branch target buffer). Ce cache est une amélioration du tampon d’adresse de branchement vu plus haut, auquel on aurait ajouté les adresses de destination des branchements. Précisons que le cache ne mémorise pas les branchements non-pris, ce qui est inutile. Précisons que la capacité limitée du cache de branchement fait que d'anciennes correspondances sont souvent éliminées pour laisser la place à de nouvelles. Le cache utilise généralement un algorithme de remplacement de type LRU. En conséquence, certains branchements peuvent donner des erreurs de prédiction si leur correspondance a été éliminée du cache.
D'autres processeurs mémorisent les correspondances entre branchement et adresse de destination dans les bits de contrôle du cache d'instructions. Cela demande de mémoriser trois paramètres : l'adresse du branchement dans la ligne de cache (stockée dans le branch bloc index), l'adresse de la ligne de cache de destination, la position de l'instruction de destination dans la ligne de cache de destination. Lors de l'initialisation de la ligne de cache, on considère qu'il n'y a pas de branchement dans la ligne de cache. Les informations de prédiction de branchement sont alors mises à jour progressivement, au fur et à mesure de l’exécution de branchements. Le processeur doit en même temps charger l'instruction de destination correcte dans le cache, si un défaut de cache a lieu : il faut donc utiliser un cache multiport. L'avantage de cette technique est que l'on peut mémoriser une information par ligne de cache, comparé à une instruction par entrée dans un tampon de destination de branchement. Mais cela ralentit fortement l'accès au cache et gaspille du circuit (les bits de contrôle ajoutés ne sont pas gratuits). En pratique, on n'utilise pas cette technique, sauf sur quelques processeurs (un des processeurs Alpha utilisait cette méthode).
Passons maintenant aux branchements indirects. Les techniques précédentes marchent pas trop mal, mais elles se trompent à chaque fois qu'un branchement indirect change d'adresse de destination. Tous les processeurs moins récents que le Pentium M prédisent les branchements indirects de cette façon. De nos jours, les processeurs haute performance sont capables de prédire l'adresse de destination d'un branchement indirect avec un tampon de destination de branchement amélioré. Ce dernier mémorise plusieurs adresses de destination pour un seul branchement et des informations qui lui permettent de déduire plus ou moins efficacement quelle adresse de destination est la bonne. Mais même malgré ces techniques avancées de prédiction, les branchements indirects et appels de sous-programmes indirects sont souvent très mal prédits.
Certains processeurs peuvent prévoir l'adresse à laquelle il faudra reprendre lorsqu'un sous-programme a fini de s’exécuter, cette adresse de retour étant stockée sur la pile, ou dans des registres spéciaux du processeur dans certains cas particuliers. Ils possèdent un circuit spécialisé capable de prédire cette adresse : la prédiction de retour de fonction (return function predictor). Lorsqu'une fonction est appelée, ce circuit stocke l'adresse de retour d'une fonction dans des registres internes au processeur organisés en pile. Avec cette organisation des registres en forme de pile, on sait d'avance que l'adresse de retour du sous-programme en cours d'exécution est au sommet de cette pile.
La prédiction de branchement
Maintenant, voyons comment notre processeur fait pour prédire si un branchement est pris ou non. Si on prédit qu'un branchement est non pris, on continue l’exécution à partir de l'instruction qui suit le branchement. À l'inverse si le branchement est prédit comme étant pris, le processeur devra recourir à l'unité de prédiction de direction de branchement.
La prédiction statique de branchement
Avec la prédiction statique, on considère que le branchement est soit toujours pris, soit jamais pris. L'idée est de faire une distinction entre les branchements inconditionnels, toujours pris, et les branchements conditionnels qui sont soit pris, soit non pris. Ainsi, on peut donner un premier algorithme de prédiction dynamique : on suppose que les branchements inconditionnels sont toujours pris alors que les branchements conditionnels ne sont jamais pris (ce qui est une approximation). Cette méthode est particulièrement inefficace pour les branchements de boucle, où la condition est toujours vraie, sauf en sortie de boucle ! Il a donc fallu affiner légèrement l'algorithme de prédiction statique.
Une autre manière d’implémenter la prédiction statique de branchement est de faire une différence entre les branchements conditionnels ascendants et les branchements conditionnels descendants. Un branchement conditionnel ascendant est un branchement qui demande au processeur de reprendre plus loin dans la mémoire : l'adresse de destination est supérieure à l'adresse du branchement. Un branchement conditionnel descendant a une adresse de destination inférieure à l'adresse du branchement : le branchement demande au processeur de reprendre plus loin dans la mémoire. Les branchements ascendants sont rarement pris (ils servent dans les conditions de type SI…ALORS), contrairement aux branchements descendants (qui servent à fabriquer des boucles). On peut ainsi modifier l’algorithme de prédiction statique comme suit :
- les branchements inconditionnels sont toujours pris ;
- les branchements descendants sont toujours pris ;
- les branchements ascendants ne sont jamais pris.
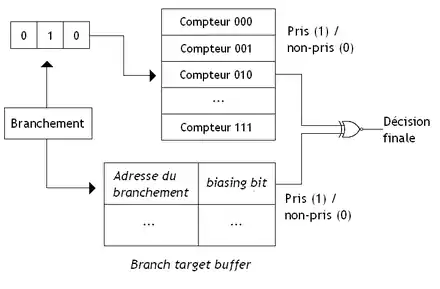
Sur certains processeurs, certains bits de l'opcode d'un branchement précisent si le branchement est majoritairement pris ou non pris. Ils permettent d'influencer les règles de prédiction statique et de passer outre les réglages par défaut. Ces bits sont appelés des suggestions de branchement (branch hint).
La prédiction de branchement avec des compteurs à saturation locaux
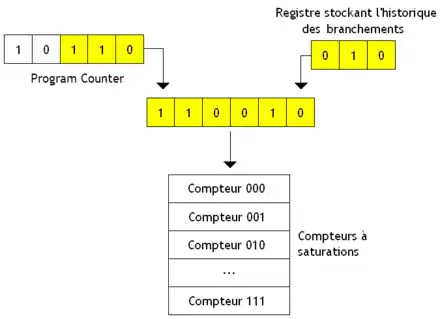
Avec la prédiction dynamique, on mémorise à chaque exécution du branchement si celui-ci est pris ou pas, et on effectue une moyenne statistique sur toutes les exécutions précédentes du branchement. Si la probabilité d'être pris est supérieure à 50 %, le branchement est considéré comme pris. Dans le cas contraire, il est considéré comme non pris. L'idée est d'utiliser un compteur à saturation qui mémorise le nombre de fois qu'un branchement est pris ou non pris. Ce compteur est initialisé de manière à avoir une probabilité proche de 50 %. Le compteur est incrémenté si le branchement est pris et décrémenté s'il est non pris. Pour faire la prédiction, on regarde le bit de poids fort du compteur : le branchement est considéré comme pris si ce bit de poids fort est à 1, et non pris s'il vaut 0. Certains processeurs utilisent un seul compteur à saturation, qui fait la moyenne pour tous les branchements. D'autres utilisent un compteur par branchement dans le tampon de destination de branchement. Pour la culture générale, il faut savoir que le compteur à saturation du Pentium 1 était légèrement bogué.
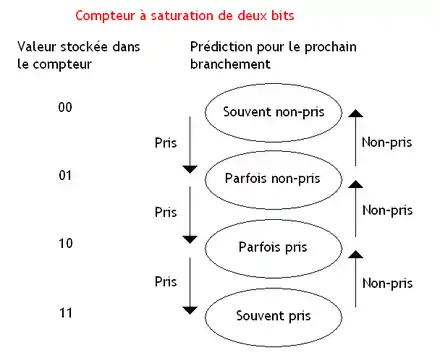
Le compteur à saturation fonctionne mal pour un branchement exécuté comme suit : pris, non pris, pris, non pris, et ainsi de suite. Même chose pour un branchement qui ferait : pris, non pris, non pris, non pris, pris, non pris, non pris, non pris, etc. Une solution pour régler ce problème est de se souvenir des 2, 3, 4 (ou plus suivant les modèles) exécutions précédentes du branchement. Pour cela, on va utiliser un registre à décalage. À chaque fois qu'un branchement s’exécute, on décale le contenu du registre et on fait rentrer un 1 si le branchement est pris, et un 0 sinon. Pour chaque valeur possible contenue dans le registre, on a un compteur à saturation associé. Chaque compteur mémorise le nombre de fois qu'un branchement a été pris à chaque fois que son historique est identique à celui mémorisé dans le registre. Par exemple, si le registre contient 010, le compteur associé indique qu'à chaque fois que le branchement a été non pris, puis pris, puis non pris, le branchement a été majoritairement pris ou non pris.
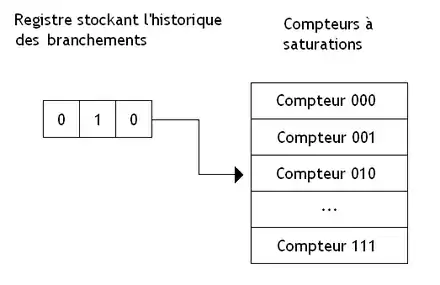
La prédiction de branchement avec des compteurs à saturation globaux
Certains processeurs se payent le luxe d'avoir un registre (et le jeu de compteurs à saturation qui vont avec) différent pour chaque branchement qui est placé dans le tampon de destination de branchement : on dit qu'ils font de la prédiction locale. D'autres, utilisent un registre unique pour tous les branchements : ceux-ci font de la prédiction globale. L'avantage de ces unités de prédiction, c'est que d'éventuelles corrélations entre branchements sont prises en compte. Mais cela a un revers : si deux branchements différents passent dans l'unité de prédiction de branchement avec le même historique, ils modifieront le même compteur à saturation. En clair, ces deux branchements vont se marcher dessus sans vergogne, chacun interférant sur les prédiction de l'autre !
C'est la raison d'être des unités de prédiction « gshare » et « gselect » : limiter le plus possible ces interférences. Pour cela, on va effectuer une petite opération entre l'historique et certains bits de l'adresse de ces branchements (leur program counter) pour trouver quel compteur utiliser.
- Avec les unités de prédiction « gshare », cette opération est un simple XOR entre le registre d'historique et les bits de poids faible de l'adresse du branchement. Le résultat de ce XOR donne le numéro du compteur à utiliser.
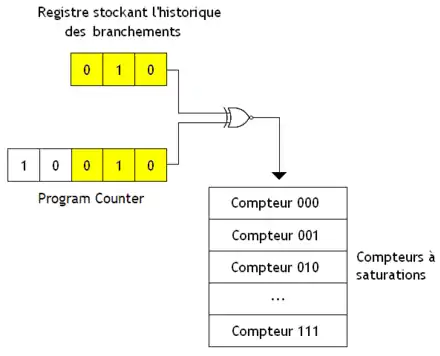
- Avec les unités de prédiction « gselect », cette opération consiste simplement à mettre côte à côte ces bits et l'historique pour obtenir le numéro du compteur à saturation à utiliser.
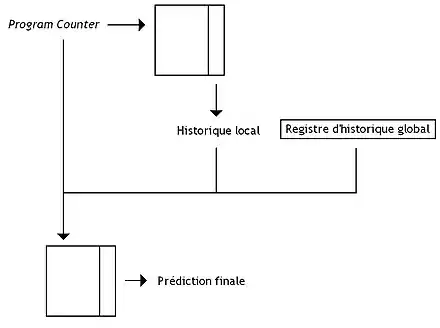
D'autres unités de prédiction mélangent prédiction globale et locale. Par exemple, on peut citer la prédiction mixte (alloyed predictor). Avec celle-ci, la table des compteurs à saturation est adressée avec la concaténation :
- de bits du program counter ;
- du registre d'historique global ;
- d'un historique local, obtenu avec l'aide d'une table de correspondances branchement → historique local.
La prédiction des branchements des boucles FOR
Certaines unités de prédiction de branchement sont capables de prédire à la perfection les branchements de boucles FOR, qui utilisent un compteur : ces branchements sont pris n − 1 fois, la dernière exécution étant non prise. La méthode de prédiction utilise un simple compteur, incrémenté à chaque exécution du branchement. Tant que la valeur stockée dans le compteur est différente du nombre n, on considère que le branchement est pris, tandis que si le contenu de ce compteur vaut n, le branchement n'est pas pris. Lorsqu'une boucle est exécutée la première fois, ce nombre n est détecté, et stocké dans le tampon de destination de branchement.
Les prédicteurs hybrides
Il est possible de combiner plusieurs unités de prédiction de branchement différentes et de combiner leurs résultats en une seule prédiction. De nombreuses unités de prédiction de branchement se basent sur ce principe. Dans le cas le plus simple, on utilise plusieurs unités de prédiction de branchement, et on garde le résultat majoritaire : si une majorité d'unités pense que le branchement est pris, alors on le considère comme pris, et comme non pris dans le cas contraire.
La prédiction par consensus (agree predictor) utilise une prédiction dynamique à deux niveaux, couplée avec un compteur à saturation. Le décision finale vérifie que ces deux circuits sont d'accord : lorsque les deux unités de branchement ne sont pas d’accord, c'est qu'il y a surement eu interférence. Cette décision se fait donc en utilisant une porte XOR suivie d'une porte NON entre les sorties de ces deux unités de prédiction de branchement.
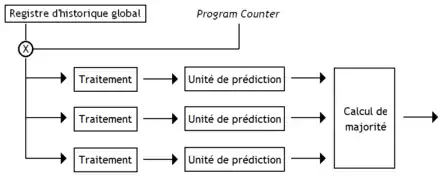
Cette technique est aussi utilisée sur l'unité de prédiction de branchement « e-gskew ». Sur celle-ci, trois unités de prédiction de branchement sont utilisées, avec un vote majoritaire. Pour les trois unités, on commence par effectuer un XOR entre certains bits du program counter, et le registre d'historique global. Simplement, le résultat subit une modification qui dépend de l'unité : la fonction de hachage qui associe une entrée à un branchement dépend de l'unité.
Une autre technique remplace la porte à majorité par un additionneur. Cette technique demande de lire directement le contenu des compteurs de l'unité de prédiction, et de les additionner entre eux. On déduit la prédiction à partir de cette somme : prendre le bit de poids fort suffit.
On peut aussi utiliser des historiques de taille différente, qui sont combinés avec le program counter pour identifier les branchements dans chaque unité de prédiction. L'ensemble des tailles d'historique donne quelque chose du type 1, 2, 4, 8, 16, etc. On obtient alors la prédiction à longueur d’historique géométrique (geometric history length predictor).
Une autre technique consiste à prioriser les unités de prédiction de branchement. Par défaut, on utilise une première unité de branchement, relativement simple (un simple compteur à saturation par branchement) : cette unité a la priorité la plus faible, et est utilisée en dernier recours. À côté, on trouve une seconde unité de branchement, qui utilise un autre algorithme. À chaque cycle, la seconde unité reçoit une requête de prédiction de branchement :
- si sa table de correspondances ne permet pas de donner de prédiction pour ce branchement, alors on utilise la prédiction de l'autre unité ;
- dans le cas contraire, la prédiction disponible est utilisée en lieu et place de celle de l'unité simple.
Pour implémenter le tout, rien de plus simple. Il suffit :
- de placer un multiplexeur qui effectue le choix de la prédiction ;
- d'ajouter une sortie de 1 bit à la seconde unité, qui indique si l'unité peut prédire le branchement (succès de cache dans la table de correspondances) ;
- de commander le multiplexeur avec la sortie de 1 bit.
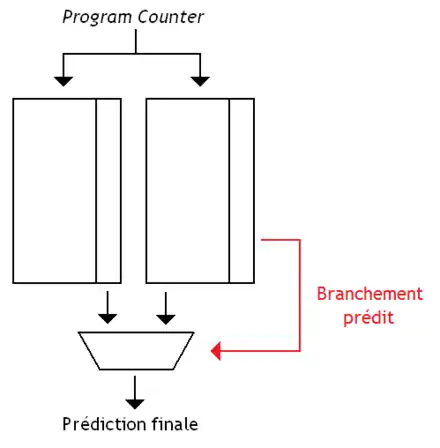
D'autres unités de prédiction de branchement sont composées de deux unités de prédiction séparées et choisissent laquelle croire avec un compteur à saturation : ce compteur indiquera si la première unité de prédiction a plus souvent raison que l'autre unité. Le résultat de ce compteur à saturation est alors utilisé pour commander un multiplexeur, qui effectuera le choix entre les deux prédictions. C'est cette technique qui est utilisée dans l’unité de prédiction bimodale (bimode predictor). Celle-ci est composée de deux tables :
- une dédiée aux branchements qui sont très souvent pris ;
- une autre pour les branchement très peu pris.
Chaque table attribue un compteur à saturation pour chaque branchement. Les branchements sont identifiés par quelques bits du program counter qui sont XORés avec un registre d'historique global. Le résultat de ce XOR est envoyé aux deux tables, qui vont alors fournir chacune une prédiction. Ces deux prédictions seront envoyées à un multiplexeur commandé par une une unité de sélection, qui se chargera de déduire quelle unité a raison : cette unité de sélection est composé d'une table de correspondances program counter → compteur à saturation. On peut encore améliorer l'unité de sélection de prédiction en n'utilisant non pas des compteurs à saturation, mais une unité de prédiction dynamique à deux niveaux, ou toute autre unité vue auparavant.
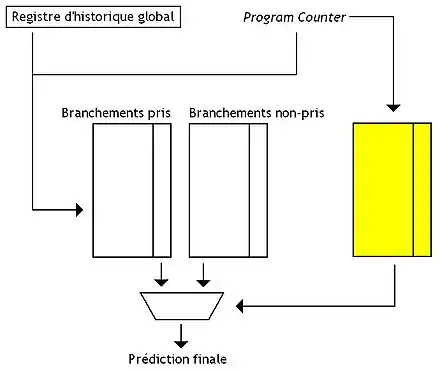
Certains processeurs utilisent plusieurs unités de prédiction de branchement qui fonctionnent en parallèle. Certains d'entre eux utilisent deux unités de prédiction de branchement : une très rapide mais ne pouvant prédire que les branchements « simples à prédire », et une autre plus lente qui prend le relais quand la première unité de prédiction de branchement n'arrive pas à prédire un branchement.
Les processeurs à chemins multiples
Pour limiter la casse en cas de mauvaise prédiction, certains processeurs chargent des instructions en provenance des deux chemins (celui du branchement pris, et celui du branchement non pris) dans une mémoire cache, qui permet de récupérer rapidement les instructions correctes en cas de mauvaise prédiction de branchement. Certains processeurs vont plus loin et exécutent les deux possibilités séparément : c'est ce qu'on appelle l'exécution stricte (eager execution). Bien sûr, on n’est pas limité à un seul branchement mais on peut poursuivre un peu plus loin. On peut remarquer que cette technique utilise la prédiction de direction branchement , pour savoir quelle la destination des branchements. Les techniques utilisées pour annuler les instructions du chemin non-pris sont les mêmes que celles utilisées pour la prédiction de branchement.
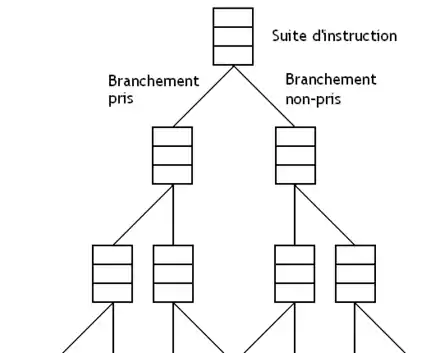
Implémentation
Implémenter cette technique demande de dupliquer les circuits de chargement pour charger des instructions provenant de plusieurs « chemins d’exécution ». Pour identifier les instructions à annuler, chaque instruction se voit attribuer un numéro par l'unité de chargement, qui indique à quel chemin elle appartient. Chaque chemin peut être dans quatre états, états qui doivent être mémorisés avec le program counter qui correspond :
- invalide (pas de second chemin) ;
- en cours de chargement ;
- mis en pause suite à un défaut de cache ;
- chemin stoppé car il s'est séparé en deux autres chemins, à cause d'un branchement.
Pour l'accès au cache d'instructions, l'implémentation varie suivant le type de cache utilisé. Certains processeurs utilisent un cache à un seul port avec un circuit d'arbitrage. La politique d'arbitrage peut être plus ou moins complexe. Dans le cas le plus simple, chaque chemin charge ses instructions au tour par tour. Des politiques plus complexes sont possibles : on peut notamment privilégier le chemin qui a la plus forte probabilité d'être pris, pas exemple. D'autres processeurs préfèrent utiliser un cache multiport, capable d’alimenter plusieurs chemins à la fois.
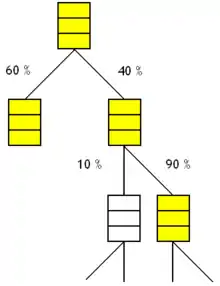
L'exécution stricte disjointe
Avec cette technique, on est limité par le nombre d'unités de calculs, de registres, etc. Au bout d'un certain nombre d’embranchements, le processeur finit par ne plus pouvoir poursuivre l’exécution, par manque de ressources matérielles.
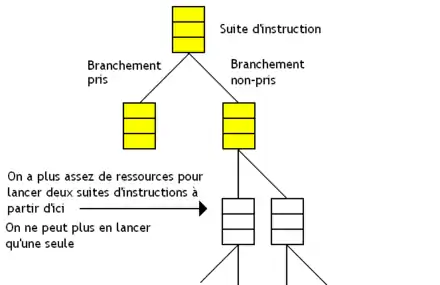
Pour limiter la casse, on peut coupler exécution stricte et prédiction de branchement.
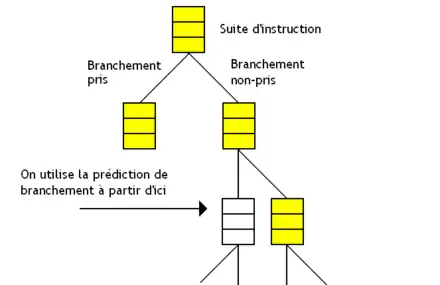
L'idée est de ne pas exécuter les chemins qui ont une probabilité trop faible d'être pris. Si un chemin a une probabilité inférieure à un certain seuil, on ne charge pas ses instructions. On parle d’exécution stricte disjointe (disjoint eager execution). C'est la technique qui est censée donner les meilleurs résultats d'un point de vue théorique. À chaque fois qu'un nouveau branchement est rencontré, le processeur refait les calculs de probabilité. Cela signifie que d'anciens branchements qui n'avaient pas été exécutés car ils avaient une probabilité trop faible peuvent être exécuté si des branchements avec des probabilités encore plus faibles sont rencontrés en cours de route.