Vous pensez surement qu'il faut obligatoirement plusieurs processeurs pour exécuter plusieurs programmes en parallèle, mais sachez que c'est faux ! Il est parfois possible pour un processeur seul d’exécuter plusieurs programmes en même temps. Pour cela, il faut utiliser des processeurs spéciaux, qui utilisent des ruses de sioux.
Du parallélisme avec un seul processeur
A l'intérieur d'un processeur, on trouve un circuit qui fait des calculs: l'unité de calcul. Il arrive que l'unité de calcul d'un processeur ne fasse rien, pour diverses raisons. Et si on n'arrive pas à donner du travail à l'unité de calcul avec un seul programme, pourquoi ne pas remplir les vides avec les instructions d'un autre programme ? Et bien cela peut se faire de trois manières différentes.
Le multithreading sur les processeurs à émission unique
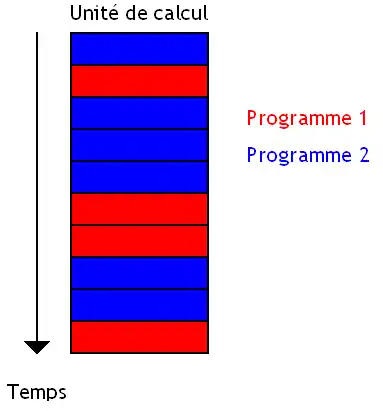
Première technique : le Coarse Grained Multithreading, qui change de programme quand un évènement bien précis a lieu. Le changement de programme peut s’effectuer pour des raisons différentes. En général, on change de programme lorsque certaines instructions sont exécutées : accès à la mémoire, branchements, etc.
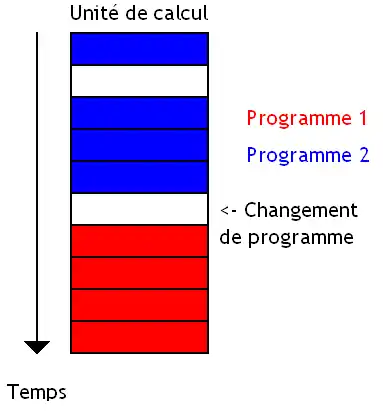
Le cas le plus fréquent est un accès à la mémoire (lors d'un cache miss). Il faut dire que l'accès à la mémoire est quelque chose de très lent, aussi changer de programme et exécuter des instructions pour recouvrir l'accès à la mémoire est une bonne chose. On peut aussi utiliser une instruction de changement de programme, fournie par le jeu d'instruction du processeur.
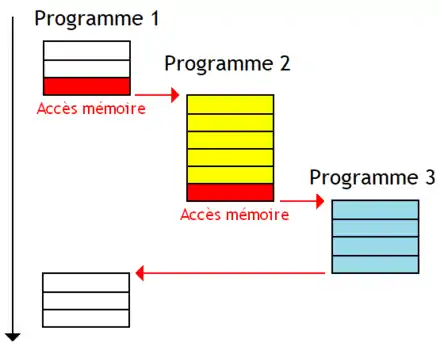
La seconde méthode, le Fine Grained Multithreading, change de programme à chaque cycle d'horloge. L'avantage est que deux instructions successives n'appartiennent pas au même programme. Il n'y a donc pas de dépendances entre instructions successives et les circuits liés à la détection ou la prise en compte de ces dépendances disparaissent. Mais pour cela, on est obligé d'avoir autant de programmes en cours d’exécution qu'il y a d'étages de pipeline. Et quand ce n'est pas le cas, on trouver des solutions pour limiter la casse. Par exemple, certains processeurs lancent plusieurs instructions d'un même programme à la suite, chaque instruction contenant quelques bits pour dire au processeur : tu peux lancer 1, 2, 3 instructions à la suite sans problème. Cette technique s'appelle l'anticipation de dépendances.
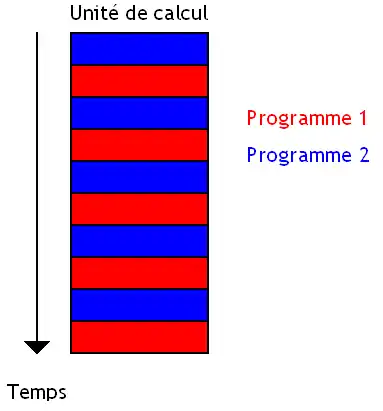
Sur d'autres processeurs, plusieurs programmes s’exécutent en même temps et chaque programme utilise l'unité de calcul dès que les autres la laissent libre. On parle alors de multithreading total.
Le multithreading sur les processeurs à émission multiple
Les techniques vues au-dessus peuvent s'adapter sur les processeurs capables de démarrer plusieurs instructions simultanément sur des unités de calcul séparées. On peut ainsi adapter le Coarse-grained multithreading et le Fine-grained multithreading. Dans les deux cas, un seul programme a accès aux unités de calcul à chaque cycle d'horloge.
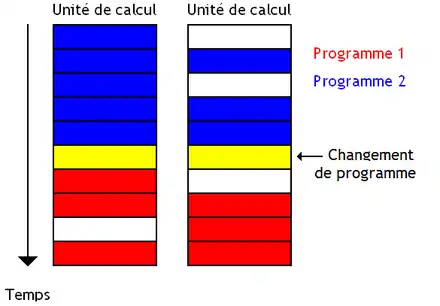

Mais on peut aussi faire en sorte que plusieurs programmes puissent faire démarrer leurs instructions en même temps. A chaque cycle d'horloge, le processeur peut exécuter des instructions provenant de divers programmes. On obtient la technique du Simultaneous Multi-Threading ou SMT.

L'implémentation matérielle
Il est obligatoire de dupliquer les registres pour que chaque programme ait son ensemble de registres rien qu'à lui. Cela demande soit un banc de registre (register file) par programme, soit un banc de registre commun géré par fenêtrage de registre (chaque programme ayant sa propre fenêtre de registres). De plus, les processeurs multithreadés utilisent le fait que l'unité de Fetch et l'unité de calcul sont séparés et fonctionnent en pipeline. Pour simplifier, le processeur peut exécuter une instruction sur l'unité de calcul et commencer à charger l'instruction suivante, en même temps.
Le processeur charge des instructions en provenance de programmes différents, ce qui demande d'utiliser plusieurs Program Counter et éventuellement plusieurs unités de Fetch si la mémoire ou le cache d'instruction sont multiports. Dans le cas où il n'y a qu'une seule unité de Fetch, un seul programme peut charger ses instructions à chaque cycle. L'unité de Fetch donne la main à chacun des programmes les uns après les autres, en boucle. Un circuit se charge de choisir le Program Counter - le thread - qui aura la chance de charger ses instructions. On peut par exemple donner la priorité aux threads qui accèdent le moins à la mémoire RAM (peu de cache miss), à ceux qui ont exécutés le moins d'instructions de branchement récemment, etc.
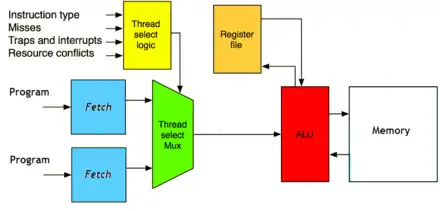
Généralement, la fenêtre d'instruction (instruction windows) est partagée entre les différents programmes. Chaque instruction mise en attente (chaque entrée) stocke le numéro du programme, attribué à l'instruction par l'unité de Fetch.
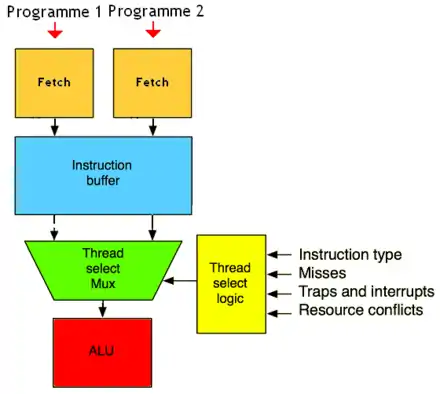
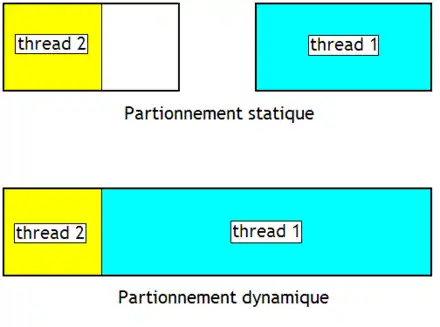
La fenêtre d'instruction est partitionnée en morceaux réservés à un programme bien précis. Si ces morceaux ont la même taille, on parle de partitionnement statique. Dans d'autres cas, si jamais un programme a besoin de plus de place que l'autre, il peut réserver un peu plus de place que son concurrent : on parle de partitionnement dynamique.