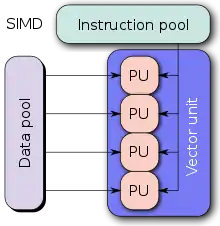
Nous allons maintenant aborder le parallélisme de données, qui consiste à traiter des données différentes en parallèle. De nombreuses situations s'y prêtent relativement bien : traitement d'image, manipulation de sons, vidéo, rendu 3d, etc. Mais pour exploiter ce parallélisme, il a fallu concevoir des processeurs adaptés.
Une solution simple est d'utiliser plusieurs processeurs qui exécutent la même instruction, chacun sur des données différentes. Cette solution a autrefois été utilisée sur certains supercalculateurs, comme les Thinking machines CM-1 et CM-2, qui exécutaient tous la même instruction au même cycle d'horloge sur 64000 processeurs différents (chaque processeur était minimaliste). Mais ce genre de solution ne peut être efficace et rentable que sur des grosses données, car elle nécessite des ordinateurs assez chers. N'espérez pas commander ce genre d’ordinateurs pour noël !
Ces architectures ont depuis étés remplacées par des architectures qui exploitent le parallélisme de données au niveau de l'unité de calcul, celle-ci pouvant exécuter des calculs en parallèle. Nous allons aborder ces architectures dans ce chapitre.
Les instructions SIMD
Certains processeurs fournissent des instructions vectorielles, des instructions capables de traiter plusieurs éléments en parallèle. Elles travaillent sur un plusieurs nombres entiers ou flottants placés les uns à côté des autres, qui forment ce qu'on appelle un vecteur. Quand on exécute une instruction sur un vecteur, celle-ci traite ces entiers ou flottants en parallèle, simultanément.
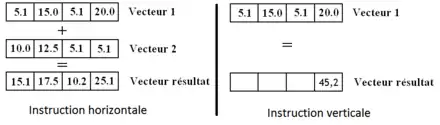
Les instructions SIMD peuvent être rassemblées en deux grands groupes : les horizontales et les verticales. Les instructions horizontales travaillent en parallèle sur les éléments qui sont "à la même place" dans deux vecteurs. Les instructions verticales vont réduire un vecteur en un simple nombre. Elle peuvent calculer la somme des éléments d'un vecteur, calculer le produit de tous les éléments d'un vecteur, renvoyer le nombre d’éléments nuls dans un vecteur, etc. Une instruction de calcul vectoriel va traiter chacune des données du vecteur indépendamment des autres. Par exemple, une instruction d'addition vectorielle va additionner ensemble les données qui sont à la même place dans deux vecteurs, et placer le résultat dans un autre vecteur, à la même place.
Les instructions SIMD sont difficilement utilisables dans des langages de haut niveau et c'est donc au compilateur de traduire un programme avec des instructions vectorielles. Les transformations qui permettent de traduire des morceaux de programmes en instructions vectorielles (déroulage de boucles, strip-mining) portent le nom de vectorisation.
Les registres vectoriels
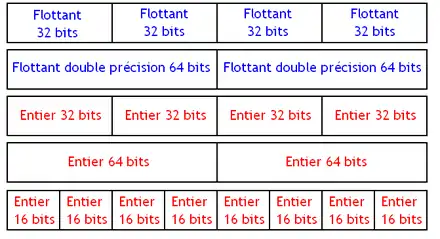
Les processeurs SIMD contiennent des registres spécialisés pouvant chacun contenir un paquet. Ces registres ayant tous une taille fixe, la taille d'un paquet est fixée une fois pour toute par le jeu d'instruction. Cela implique que suivant la taille des données à manipuler, on pourra en placer plus ou moins dans un paquet. Suivant la taille des données, et le type de celle-si, on devra effecteur des instructions différentes. Par exemple, on devra utiliser deux instructions différentes suivant qu'on manipule des flottants 64 bits ou des entiers 32 bits. Il faudra aussi gérer la taille des données, pour savoir comment découper le paquet en données. Et pour cela, on utilise encore une fois différentes instructions : l'instruction pour manipuler des paquets contenant des entiers de 16 bits sera différente de celle manipulant des entiers de 32 bits.
Un processeur vectoriel peut incorporer des registres qui facilitent le traitement des diverses instructions. Parmi ces registres, nous aborderons ultérieurement le Vector Length Register, et le Vector Mask Register.
Le Vector Length Register
Le Vector Length Register permet de gérer les tableaux dont la taille n'est pas un multiple d'un vecteur. Celui-ci indique combien d’éléments on doit traiter dans un vecteur. On peut ainsi dire au processeur : je veux que tu ne traite que les 40 premiers éléments présents d'un paquet. Quand on arrive à la fin d'un tableau, il suffit de configurer le Vector Length Register pour ne traiter que ce qu'il faut.

Il facilite l'usage du déroulage de boucle, une optimisation qui vise à réduire le nombre d'itérations d'une boucle en dupliquant son corps en plusieurs exemplaires. Le compilateur réplique le corps de la boucle (les instructions à répéter) en plusieurs exemplaires dans cette boucle, avant de corriger le nombre d'itérations de la boucle. Par exemple, prenons cette boucle, écrite dans le langage C :
int i;
for (i = 0; i < 100; ++i)
{
a[i] = b[i] * 7 ;
}
Celle-ci peut être déroulée comme suit :
int i;
for (i = 0; i < 100; i+=4)
{
a[i] = b[i] * 7 ;
a[i+1] = b[i+1] * 7 ;
a[i+2] = b[i+2] * 7 ;
a[i+3] = b[i+3] * 7 ;
}
Les instructions vectorielles permettent de traiter plusieurs éléments à la fois, ce qui fait que plusieurs tours de boucles peuvent être rassemblés en une seule instruction SIMD. Le déroulage de boucles permet d'exposer des situations où ce regroupement est possible. Dans notre exemple, si jamais notre processeur dispose d'une instruction de multiplication capable de traiter 4 éléments du tableau a ou b en une seule fois, la boucle déroulée peut être vectorisée assez simplement en utilisant une multiplication vectorielle (que nous noterons vec_mul).
int i;
for (i = 0; i < 100; i+=4)
{
vec_a[i] = vec_mul ( vec_b[i] , 7 ) ;
}
Le déroulage de boucles n'est toutefois pas une optimisation valable pour toutes les boucles. Reprenons l'exemple de la boucle vue plus haut. Si jamais le tableau à manipuler a un nombre d’éléments qui n'est pas multiple de 4, la boucle ne pourra être vectorisée, vu que la multiplication vectorielle ne peut traiter que 4 éléments à la fois. Pour ce faire, les compilateurs utilisent généralement deux boucles : une qui traite les éléments du tableau avec des instructions SIMD, et une autre qui traite les éléments restants avec des instructions non vectorielles. Cette transformation s'appelle le strip-mining.
Par exemple, si je veux parcourir un tableau de taille fixe contenant 102 éléments, je devrais avoir une boucle comme celle-ci :
int i;
for (i = 0; i < 100; i+=4)
{
a[i] = b[i] * 7 ;
a[i+1] = b[i+1] * 7 ;
a[i+2] = b[i+2] * 7 ;
a[i+3] = b[i+3] * 7 ;
}
for (i = 100; i < 102; ++i)
{
a[i] = b[i] * 7 ;
}
Les processeurs vectoriels utilisent le Vector Length Register pou éviter d'utiliser le strip-mining. Avec ce registre, il est possible de demander aux instructions vectorielles de ne traiter que les n premiers éléments d'un vecteur : il suffit de placer la valeur n dans le Vector Length Register. Évidemment, n doit être inférieur ou égal au nombre d’éléments maximal du vecteur. Avec ce registre, on n'a pas besoin d'une seconde boucle pour traiter les éléments restants, et une simple instruction vectorielle peut suffire.
Le Vector Mask Register
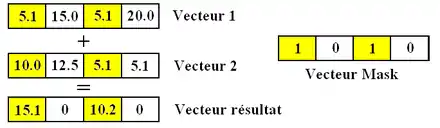
Autre obstacle à la vectorisation : la présence de branchements conditionnels dans les boucles à vectoriser. Si une boucle contient des branchements conditionnels, elle ne peut pas être vectorisée facilement : il est impossible de zapper certains éléments d'un vecteur suivant une condition. Pour résoudre ce problèmes, les processeurs vectoriels utilisent un registre de masque, ou Vector Mask Register. Celui-ci stocke un bit pour chaque donnée présente dans le vecteur à traiter, qui indique s'il faut ignorer la donnée ou non.
Les accès mémoire
La gestion des accès mémoire est assez hétéroclite, la façon de faire étant différente selon le architectures.
- Sur certains processeurs assez anciens, les instructions vectorielles lisent et écrivent en mémoire RAM, sans passer par des registres : on parle de processeurs memoire-mémoire.
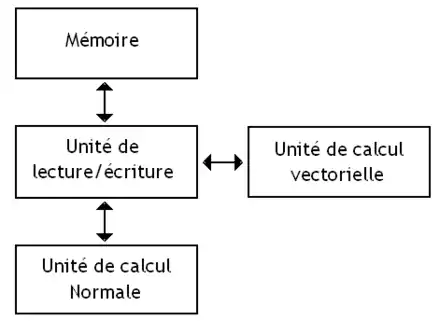
- Les processeurs à registres vectoriels possèdent des registres vectoriels dédiés aux vecteurs.
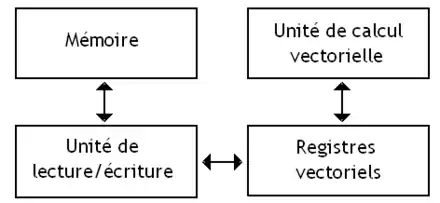
Dans le cas le plus simple, les données d'un vecteur sont contigües en mémoire et l'instruction peut utiliser le mode d'adressage vectoriel absolu. Avec ce mode d'adressage, les instructions ont juste à préciser l'adresse mémoire du début du vecteur. Avec des vecteurs de 8 octets, toute instruction d'accès mémoire utilisant le mode d'adressage absolu va lire ou écrire des blocs de 8 octets. L'adresse de départ de ces blocs 'est soumise à des contraintes d'alignement sur les jeux d'instructions comme le SSE, le MMX, etc. La raison à cela est que gérer des accès non alignés en mémoire rend les circuits de lecture/écriture en mémoire plus complexes. En contrepartie, ces contraintes compliquent l'utilisation des instructions vectorielle par le compilateur.
D'autres modes d'adressage des vecteurs permettent à une instruction de charger des données dispersées en mémoire pour les rassembler dans un vecteur. On peut notamment citer l'existence d'accès mémoires en stride et en scatter-gather.
L'accès en stride regroupe des données séparées par un intervalle régulier d'adresses. Ce mode d'accès a besoin de l'adresse initiale, de celle du premier élément du vecteur, et de la distance entre deux données en mémoire. Il permet aux instructions de mieux gérer les tableaux de structures, ainsi que les tableaux multi-dimensionnels. Lorsqu'on utilise de tels tableaux, il arrive assez souvent que l'on n'accède qu'à des éléments tous séparés par une même distance. Par exemple, si on fait des calculs de géométrie dans l'espace, on peut très bien ne vouloir traiter que les coordonnées sur l'axe des x, sans accès sur l'axe des y ou des z. Les instructions d'accès mémoire en enjambées gèrent de tels cas efficacement.
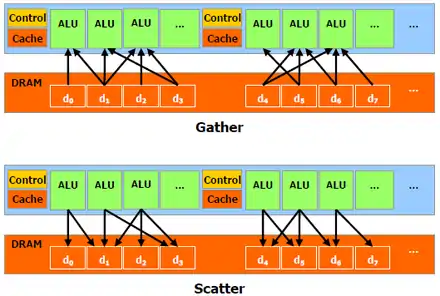
Les processeurs vectoriels incorporent aussi les accès en scatter-gather. Les accès en Scatter-Gather peuvent être vus comme une généralisation de l'adressage indirect à registre aux vecteurs, chaque élément du vecteur étant adressé via adressage indirect. Cet accès demande d'avoir la liste des adresses mémoires des données. Quand une instruction exécute un accès en Scatter, les données présentes dans ces adresses sont rassemblées dans un vecteur, et enregistrée dans un registre vectoriel. Bien sûr, il existe aussi l’inverse pour l'écriture : c'est l'accès en Gather. Cet accès sert à mieux gérer les matrices creuses, des matrices où une grande partie des éléments sont nuls et où, dans un souci d'optimisation, seuls les éléments non nuls de la matrice sont stockés en mémoire.
Exemple avec les processeurs x86
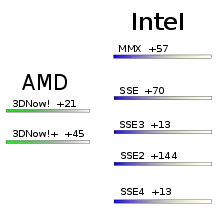
Après avoir vu la théorie sur les instructions SIMD, il est temps de voir un exemple concret : celui des instructions SIMD des processeurs x86, présents dans nos PC. Le jeu d'instruction des PC qui fonctionnent sous Windows est appelé le x86. C'est un jeu d'instructions particulièrement ancien, apparu en 1978. Depuis, des extensions x86 ont ajouté des instructions au x86 de base. On peut citer par exemple les extensions MMX, SSE, SSE2, 3dnow!, etc. Les premières instructions SIMD furent fournies par une extension x86 du nom de MMX, introduite par Intel en 1996 sur le processeur Pentium MMX. Le MMX a perduré durant quelques années avant d'être remplacé par les extensions SSE. La même année, AMD sorti d'expansion 3DNow!, qui ajoutait 21 instructions SIMD similaires à celles du MMX. Celui-ci fût suivi du 3DNow!+ quelques années plus tard. Le SSE fût ensuite décliné en plusieurs versions avant d'être "remplacé" par l'AVX. Une grande quantité de ces extensions x86 sont des ajouts d'instructions SIMD.
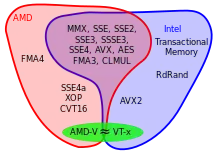
L’extension MMX
Le MMX ajoutait pas mal d'instructions SIMD assez basiques, essentiellement des instructions arithmétiques : addition, soustraction, opérations logiques, décalages, rotations, mise à zéro d'un registre, etc. La multiplication est aussi supportée, mais avec quelques petites subtilités, via l'instruction PMULLW. Les instructions MMX ne mettent pas le registre d'état à jour et ne préviennent pas en cas d'overflow ou d'underflow si ceux-ci arrivent (pour les instructions qui ne travaillent pas en arithmétique saturée).
Le MMX introduisait 8 registres vectoriels, du nom de MM0, MM1, MM2, MM3, MM4, MM5, MM6 et MM7, d'une taille de 64 bits, qui ne pouvaient contenir que des nombres entiers. Ils avaient cependant un léger défaut, qui a nuit à l'adoption du MMX. Pour comprendre ce défaut, il faut savoir que les flottants sont gérés par l'extension x87, qui définit 8 registres flottants de 80 bits. Et chaque registre MMX correspondait aux 64 bits de poids faible d'un des 8 registres flottants de la x87 ! En clair : il était impossible d'utiliser en même temps l'unité de calcul flottante et l'unité MMX. En faisant ainsi, sauvegarder les registres lors d'un changement de contexte, d'une interruption, ou d'un appel de fonction était très simple : la sauvegarde des registres de la FPU x87 suffisait. Mais cela a sacrément gêné les programmeurs ou les compilateurs qui voulaient utiliser le jeu d'instruction MMX.
L’extension SSE

Dans les années 1999, une nouvelle extension SIMD fit son apparition sur les processeurs Intel Pentium 3 : le Streaming SIMD Extensions, abrévié SSE. Ce SSE fut ensuite complété, et différentes versions virent le jour : le SSE2, SSE3, SSE4, etc. Cette extension fit apparaitre 8 nouveaux registres, les registres XMM. Sur les processeurs 64 bits, ces registres sont doublés et on en trouve donc 16. En plus de ces registres, on trouve aussi un registre d'état qui permet de contrôler le comportement des instructions SSE : celui contient des bits qui permettront de dire au processeur que les instructions doivent arrondir leurs calculs d'une certaine façon, etc. Ce registre n'est autre que le registre MXCSR. Chose étrange, seuls les 16 premiers bits de ce registres ont une utilité : les concepteurs du SSE ont surement préférés laisser un peu de marge au cas où.
La première version du SSE contenait assez peu d'instructions : seulement 70. Le SSE première version ne fournissait que des instructions pouvant manipuler des paquets contenant 4 nombres flottants de 32 bits (simple précision). Je ne vais pas toutes les lister, mais je peux quand-même dire qu'on trouve des instructions arithmétiques de base, avec pas mal d'opérations en plus : permutations, opérations arithmétiques complexes, instructions pour charger des données depuis la mémoire dans un registre. Petit détail : la multiplication est gérée plus simplement et l'on a pas besoin de s’embêter à faire mumuse avec plusieurs instructions différentes pour faire une simple multiplication comme avec le MMX.
On peut quand même signaler une chose : des instructions permettant de contrôler le cache firent leur apparition. On retrouve ainsi des instructions qui permet d'écrire ou de lire le contenu d'un registre XMM en mémoire sans le copier dans le cache. Ces instructions permettent ainsi de garder le cache propre en évitant de copier inutilement des données dedans. On peut citer par exemple, les instructions MOVNTQ et MOVNTPS du SSE premiére version. On trouve aussi des instructions permettant de charger le contenu d'une portion de mémoire dans le cache, ce qui permet de contrôler son contenu. De telles instructions de prefetch permettent ainsi de charger à l'avance une donnée dont on aura besoin, permettant de supprimer pas mal de cache miss. Le SSE fournissait notamment les instruction PREFETCH0, PREFETCH1, PREFETCH2 et PREFETCHNTA. Autant vous dire qu'utiliser ces instructions peut donner lieu à de sacrés gains si on s'y prend correctement ! Il faut tout de même noter que le SSE n'est pas seul "jeu d'instruction" incorporant des instructions de contrôle du cache : certains jeux d'instruction POWER PC (je pense à l'Altivec) ont aussi cette particularité.
Avec le SSE2, de nouvelles instructions furent ajoutés, permettant d'utiliser des nombres de 64, 16 et 8 bits dans chaque vecteur. Le SSE2 incorporait ainsi pas moins de 144 instructions différentes, instructions du SSE première version incluses. Ce qui commençait à faire beaucoup.
Puis, vient le SSE3, avec ses 13 instructions supplémentaires. Pas grand chose à signaler, si ce n'est que des instructions permettant d'additionner ou de soustraire tout les éléments d'un paquet SSE ensemble, des instructions pour les nombres complexes, et plus intéressant : les deux instructions MWAIT et MONITOR qui permettent de paralléliser plus facilement des programmes.
Le SSE4 fut un peu plus complexe et fut décliné lui-même en 2 sous-versions. Le SSE4.1 introduit ainsi des opérations de calcul de moyenne, de copie conditionnelle de registre (un registre est copié dans un autre si le résultat d'une opération de comparaison précédente est vrai), de calcul de produits scalaire, de calcul du minimum ou du maximum de deux entiers, des calculs d'arrondis, et quelques autres. Avec le SSE4.2, le vice à été poussé jusqu'à incorporer des instructions de traitement de chaines de caractères.
L’extension AVX
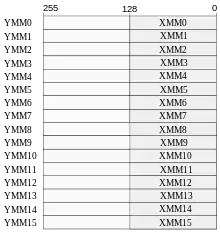
Avec l'AVX, on retrouve 16 registres d'une taille de 256 bits, nommés de YMM0 à YMM15 et dédiés aux instructions AVX. Ils sont partagés avec les registres XMM : les 128 bits de poids faible des registres YMM ne sont autre que les registres XMM. L'AVX complète le SSE et ses extensions, en rajoutant quelques instructions, et surtout en permettant de traiter des données de 256 bits.
Son principal atout face au SSE est que les instructions AVX permettent de préciser le registre de destination en plus des registres d'opérandes. Avec le SSE et le MMX, le résultat d'une instruction SIMD était écrit dans un des deux registres d'opérande manipulé par l'instruction. Il fallait sauvegarder son contenu si on en avait besoin plus tard, ce qui n'est plus nécessaire avec l'AVX.
Les processeurs vectoriels
Les instructions SIMD sont assez rudimentaires, et certains processeurs assez anciens allaient un peu plus loin : ces processeurs sont ce qu'on appelle des processeurs vectoriels. Ils incorporent diverses techniques que de simples instructions SIMD n'ont pas forcément. Les processeurs vectoriels ne font pas leurs calculs de la même manière que les processeurs SIMD, et n'accèdent pas à la mémoire de la même façon. Par exemple, pour permettre les accès en scatter-gather, les processeurs vectoriels sont souvent combinés à des mémoires multiports ou pipelinées. De plus, les processeurs vectoriels ne possèdent aucune mémoire cache pour les données (même s'ils ont des cache d'instruction).
Une unité de calcul pipelinée
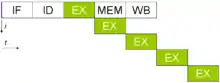
La différence entre processeur vectoriel et SIMD tient dans la façon dont sont traités les vecteurs : les instructions SIMD traitent chaque élément en parallèle, alors que les processeurs vectoriels pipelinent ces calculs ! Par pipeliner, on veut dire que l’exécution de chaque instruction est découpée en plusieurs étapes indépendantes. Au lieu d'attendre la fin de l’exécution d'un opération avant de passer à la suivante, on peut commencer le traitement d'une nouvelle donnée sans avoir à attendre que l'ancienne soit terminée.
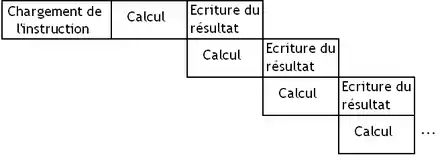
Pour donner un exemple, on peut donner l'exemple d'une multiplication flottante effectuée entre deux registres. Son exécution peut être décomposée en plusieurs étapes. Par exemple, on peut avoir 3 étapes :
- une première étape E qui va additionner les exposants et gérer les diverses exceptions ;
- une étape M qui va multiplier les mantisses ;
- et enfin une étape A qui va arrondir le résultat.
L’exécution de notre opération flottante sur un vecteur donnerait donc quelque chose dans le genre, où chaque ligne correspond au traitement d'un nouvel élément dans un vecteur, dans un paquet SIMD.
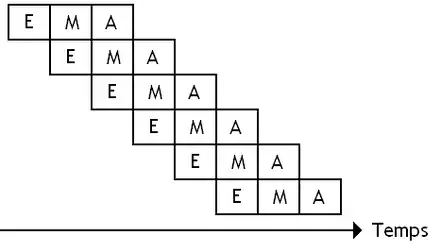
Avec une unité de calcul pipelinée découpée en N étages, on peut gérer N données simultanées : autant qu'il y a d'étapes différentes. Mais ce nombre maximal de données met un certain temps avant d'être atteint. L'unité de calcul met du temps avant d'arriver à son régime de croisière. Durant ce temps, elle n'a pas commencé à traiter suffisamment d’éléments pour que toutes les étapes soient occupées. Ce temps de démarrage est strictement égal du nombre d'étapes nécessaires pour effectuer une instruction. La même chose arrive vers la fin du vecteur, quand il ne reste plus suffisamment d’éléments à traiter pour remplir toutes les étapes.
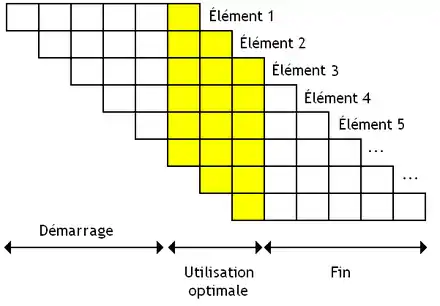
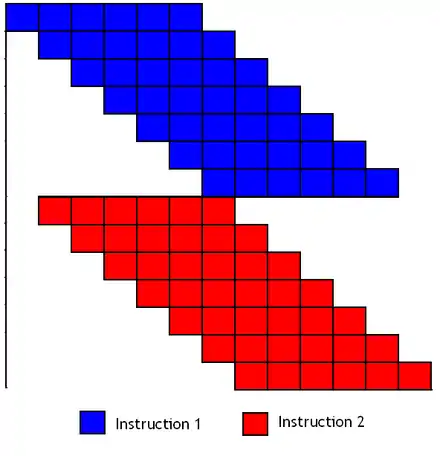
Pour amortir ces temps de démarrage et de fin, certains processeurs démarrent une nouvelle instruction sans attendre la fin de la précédente : deux instructions peuvent se chevaucher pour remplir les vides. Par contre, il peut y avoir des problèmes lorsque deux instructions qui se suivent manipulent le même vecteur. Il faut que la première instruction ait fini de manipuler un élément avant que la suivante ne veuille commencer à le modifier. Pour cela, il faut avoir des vecteurs suffisamment qui contiennent plus d’éléments qu'il n'y a d'étapes pour effectuer notre instruction.
La technique du chaining
La technique du pipeline peut encore être améliorée dans certains cas particuliers. Imaginons que l'on ait trois paquets : A, B et C. Pour chaque énième élément de ces paquets, je souhaite effectuer le calcul . En théorie, il faudrait faire d'abord la multiplication, stocker le résultat temporaire de la multiplication dans un registre vectoriel, puis faire l'addition. Mais en rusant un peu, on peut utiliser le pipeline plus efficacement. Une fois que le premier élèment de la multiplication du premier vecteur est connu, pourquoi ne pas démarrer l'addition immédiatement après, et continuer la multiplication en parallèle ? Après, tout les deux calculs ont lieu dans des ALUs séparés.

Pour ce faire, on doit modifier notre pipeline de façon à ce que le résultat de chaque étape d'un calcul soit réutilisable au cycle d’horloge suivant. La sortie de l'unité de multiplication doit être connectée à l'entrée de l'ALU d'addition. Un processeur implémentant le chaining a toutes ses unités de calcul reliées entre elles de cette façon : la sortie d'une unité est reliée aux entrées de toutes les autres. Il s'agit de ce qu'on appelle le Vector Chaining.
Les unités de calcul parallèles
Certains de nos processeurs vectoriels utilisent plusieurs ALU pour accélérer les calculs. En clair, ils sont capables de traiter les éléments d'un vecteur dans des ALU différentes. Vu que nos ALU sont pipelinées, rien n’empêche d’exécuter plusieurs instructions vectorielles différentes dans une seule ALU, chaque instruction étant à une étape différente. Mais d'ordinaire, les processeurs vectoriels comportent plusieurs ALUs spécialisées : une pour les additions, une pour la multiplication, une pour la division, etc.
Les processeurs de flux
Les processeurs de flux, aussi appelés stream processors, sont des processeurs SIMD qui utilisent une hiérarchie de registres. Voici à quoi ressemble l'architecture d'un Stream Processor :
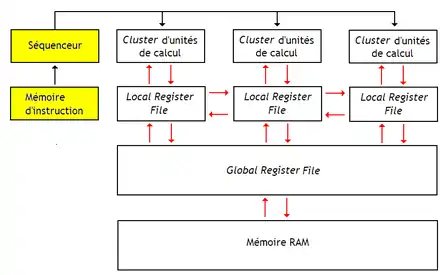
A première vue, les schémas du dessus ne ressemblent à rien de connu. Et pourtant on peut déjà faire quelques remarques assez intéressantes.
L'absence du cache de données
En théorie, les processeurs de flux contiennent peu de mémoires caches, comme pour les processeurs vectoriels. Il faut dire que les processeurs de flux sont, comme les processeurs vectoriels, conçus pour manipuler des tableaux de données, qui ont une faible localité temporelle : quand on accède à une donnée dans un tableau, il est rare qu'on doive la réutiliser plus tard. Dans ces conditions, utiliser des mémoires caches est contre-productif. C'est pour cela que les premiers processeurs de flux, comme l'Imagine, n'avaient strictement aucun cache. Au lieu de chercher à diminuer la latence avec des caches, les processeurs de flux vont plutôt chercher à masquer cette dernière en exécutant des instructions en parallèle des accès mémoire, soit en utilisant un pipeline long, soit avec du multithreading matériel.
Mais attention : si un processeur de flux ne contient pas de mémoire cache pour les données, ce n'est pas le cas pour les instructions. Après tout, si l'on doit exécuter ces instructions plusieurs fois de suite sur des données différentes, autant éviter de les charger de la mémoire à chaque fois. Pour éviter cela, les suites d'instructions à exécuter sont stockées dans une petite mémoire une bonne fois pour toute. Il s'agit bel et bien d'une petite mémoire cache.
Une hiérarchie de bancs de registres
Les processeurs de flux ont plusieurs bancs de registres : des bancs de registres locaux (Local Register File) directement connectés aux unités de calcul, un banc de registres global (Global Register File) plus gros, lui-même relié à la mémoire. Le banc de registres global sert d'intermédiaire entre la mémoire RAM et les bancs de registres locaux. Il remplace la mémoire cache et resemble beaucoup à une mémoire de type local store. Le processeur dispose d'instructions pour transférer des données entre les bancs de registres, ainsi qu'avec la mémoire. Outre son rôle d'intermédiaire, le banc de registres global sert à transférer des données entre les bancs de registres locaux, où à stocker des données globales utilisées par des Clusters d'ALU différents. Un processeur de flux possède des instructions capables de transférer des données entre le banc de registre global et la mémoire RAM, qui sont capables de faire des accès mémoires en enjambées, en Scatter-Gather, etc.
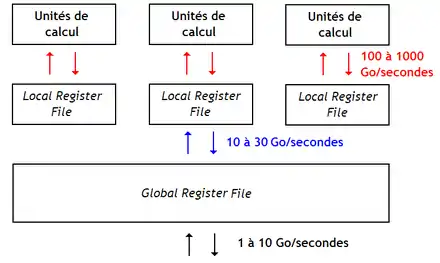
On peut se demander pourquoi utiliser plusieurs couches de registres ? Le fait est que les processeurs de flux disposent de plus d'une centaine ou d'un millier d'ALU ! Alimenter ces unités de calcul en opérandes demanderait un banc de registres énorme, lent, et qui chaufferait beaucoup trop. Pour garder un banc de registres rapide et pratique, on est obligé de limiter le nombre d'unités de calcul connectées dessus, ainsi que le nombre de registres contenus dans le banc de registres. La solution est d'utiliser une hiérarchie de registres, similaire à la hiérarchie mémoire d'un ordinateur. Cela garantit que les bancs de registres locaux sont petits et rapides, secondés par un banc de registre global d'appoint, de forte capacité, mais plus lent.
La mémoire RAM d'un processeur de flux est souvent une mémoire multibanques, comme avec les processeurs vectoriels. Elle a souvent un gros débit binaire (pour rappel, le débit binaire d'une mémoire est le nombre de bits qu'elle peut transférer en une seule seconde). Par contre, le temps d'accès est généralement assez mauvais.